
Skedarët PDF përdoren gjerësisht në internet për shkëmbimin e informacionit dhe të dhënave. Ato janë mjaft të njohura sepse ruajnë besnikërinë e dokumenteve kur shikojnë në çdo platformë. Megjithatë, ne nuk kemi kontroll mbi burimin dhe disa skedarë ndahen në format të skanuar. Ndonjëherë ju kapni një imazh si një PDF dhe më vonë ju duhet të nxirrni përmbajtjen nga skedari. Pra, një zgjidhje e mundshme është kryerja e një operacioni OCR dhe nxjerrja e tekstit. Sidoqoftë, pas operacionit OCR, nëse keni nevojë të ruani skedarin, atëherë konvertimi në formatin PDF është një zgjidhje e mundshme. Në këtë artikull, ne do të diskutojmë hapat se si të konvertohet një PDF e skanuar në tekst PDF duke përdorur Python.
OCR PDF API
Aspose.PDF Cloud SDK për Python është një mbështjellës rreth Aspose.PDF Cloud. Kjo ju mundëson të kryeni të gjitha aftësitë e përpunimit të skedarëve PDF brenda aplikacionit Python. Manipuloni skedarët PDF pa Adobe Acrobat ose ndonjë aplikacion tjetër. Pra, për të përdorur SDK-në, hapi i parë është instalimi i tij dhe është i disponueshëm për shkarkim përmes depove PIP dhe GitHub. Tani ekzekutoni komandën e mëposhtme në terminalin / vijën e komandës për të instaluar versionin më të fundit të SDK në sistem.
pip install asposepdfcloud
MS Visual Studio
Ju gjithashtu mund të shtoni direkt referencën në projektin tuaj Python brenda projektit Visual Studio. Ju lutemi kërkoni asposepdfcloud si një paketë nën dritaren e mjedisit Python. Ju lutemi ndiqni hapat e numëruar në imazhin më poshtë për të përfunduar procesin e instalimit.
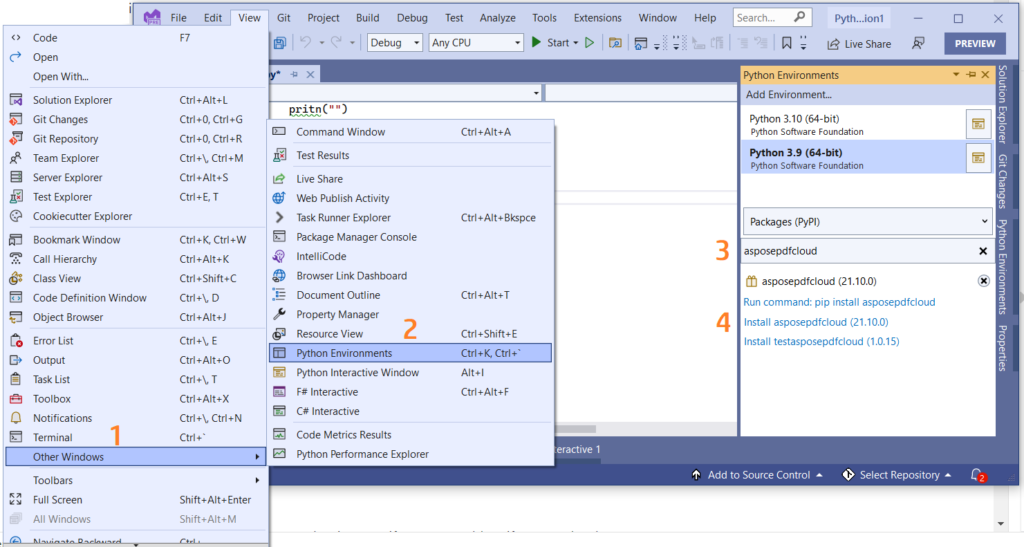
Imazhi 1:- Aspose.PDF Cloud SDK për paketën Python.
Aspose.Paneli i resë kompjuterike
Meqenëse API-të tona janë të aksesueshme vetëm për personat e autorizuar, kështu që hapi tjetër është krijimi i një llogarie në Aspose.Cloud dashboard. Nëse keni llogari GitHub ose Google, thjesht Regjistrohuni ose klikoni në butonin Krijo një llogari të re dhe jepni informacionin e kërkuar. Tani identifikohuni në panelin e kontrollit duke përdorur kredencialet dhe zgjeroni seksionin Aplikacionet nga paneli dhe lëvizni poshtë drejt seksionit Kredencialet e klientit për të parë detajet e ID-së së klientit dhe sekretit të klientit.
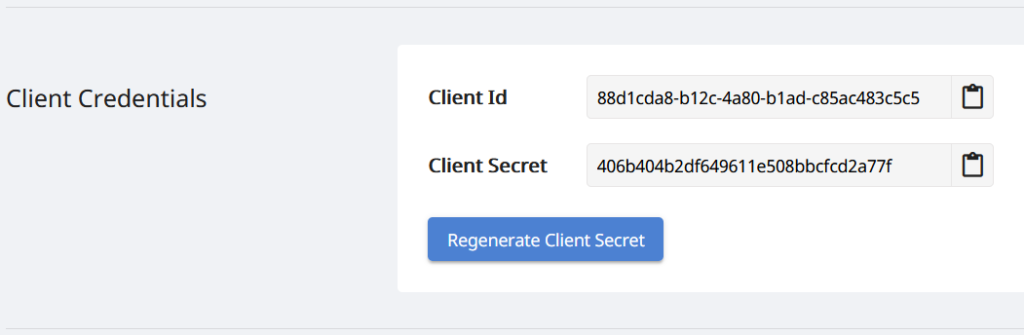
Imazhi 2:- Kredencialet e klientit në pultin e Aspose.Cloud.
Imazhi PDF në PDF të kërkueshëm në Python
Ju lutemi ndiqni hapat e dhënë më poshtë për të kryer operacionin OCR në një dokument të skanuar PDF dhe më pas ruajeni atë si të kërkueshëm (bëjeni pdf të kërkueshëm). Këta hapa na ndihmojnë të zhvillojmë OCR falas në internet duke përdorur Python.
- Së pari, ne duhet të krijojmë një shembull të klasës ApiClient duke ofruar si argumente Client ID Secret Client
- Së dyti, krijoni një shembull të klasës PdfApi e cila merr objektin ApiClient si argument hyrës
- Tani thirrni metodën putsearchabledocument(..) të klasës PdfApi e cila merr emrin e hyrjes PDF dhe një parametër opsional që tregon gjuhën e motorit OCR.
def ocrPDF():
try:
#Client credentials
client_secret = "406b404b2df649611e508bbcfcd2a77f"
client_id = "88d1cda8-b12c-4a80-b1ad-c85ac483c5c5"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# krijoni shembullin PdfApi ndërsa kaloni PdfApiClient si argument
pdf_api = PdfApi(pdf_api_client)
#input PDF file name
input_file = 'image-based-pdf-sample.pdf'
# telefononi API-në për të kryer operacionin OCR dhe për të ruajtur daljen në ruajtjen e cloud
response = pdf_api.put_searchable_document(name=input_file,lang='eng')
# printoni mesazhin në tastierë (opsionale)
print('Image PDF successfully converted to Text PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)

Imazhi 3: - Pamja paraprake e funksionimit PDF OCR.
Në imazhin e mësipërm, pjesa e majtë tregon skedarin PDF të skanuar në hyrje dhe pjesa në anën e djathtë tregon një pamje paraprake të PDF-së rezultante të bazuar në tekst. Skedarët mostër të përdorura në shembullin e mësipërm mund të shkarkohen nga image-based-pdf-sample.pdf dhe OCR-Result.pdf.
OCR në internet duke përdorur komandat cURL
API-të REST mund të aksesohen gjithashtu nëpërmjet komandave cURL dhe meqenëse API-të tona në renë kompjuterike bazohen në arkitekturën REST, kështu që ne mund të përdorim edhe komandën cURL për të kryer PDF OCR në internet. Megjithatë, përpara se të vazhdojmë me operacionin e konvertimit, duhet të gjenerojmë një JSON Web Token (JWT) bazuar në kredencialet tuaja individuale të klientit të specifikuara në panelin e kontrollit Aspose.Cloud. Është e detyrueshme sepse API-të tona janë të aksesueshme vetëm për përdoruesit e regjistruar. Ju lutemi ekzekutoni komandën e mëposhtme për të gjeneruar shenjën JWT.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=88d1cda8-b12c-4a80-b1ad-c85ac483c5c5&client_secret=406b404b2df649611e508bbcfcd2a77f" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Pasi të kemi kodin JWT, ju lutemi ekzekutoni komandën e mëposhtme për të kryer operacionin OCR dhe për të ruajtur daljen në të njëjtën ruajtje në renë kompjuterike.
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/image-based-pdf-sample.pdf/ocr" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
konkluzioni
Në këtë artikull, ne kemi diskutuar hapat drejt imazhit PDF në PDF të kërkueshme duke përdorur fragmentin e kodit Python. Ne kemi eksploruar gjithashtu detajet se si të kryeni OCR Online duke përdorur komandat cURL. Meqenëse SDK-të tona cloud janë zhvilluar nën licencën MIT, kështu që ju mund të shkarkoni fragmentin e plotë të kodit nga GitHub dhe ta përditësoni atë sipas kërkesave tuaja. Ne ju rekomandojmë shumë të eksploroni Udhëzuesin e zhvilluesit për të mësuar më shumë rreth veçorive të tjera emocionuese që ofrohen aktualisht nga Cloud API.
Në rast se keni ndonjë pyetje të lidhur ose hasni ndonjë problem gjatë përdorimit të API-ve tona, ju lutemi mos ngurroni të na kontaktoni përmes forumit falas të mbështetjes së klientit.
Artikuj të ngjashëm
Ne sugjerojmë gjithashtu të kaloni artikujt e mëposhtëm për të mësuar më shumë rreth