
PDF 文件在互联网上广泛用于信息和数据共享。它们非常受欢迎,因为它们在任何平台上查看时都能保持文档的保真度。但是,我们无法控制源,并且某些文件以扫描格式共享。有时您将图像捕获为 PDF,稍后您需要从文件中提取内容。所以一个可行的解决方案是执行OCR操作并提取文本。但是,在OCR操作之后,如果您需要保存文件,那么转换为PDF格式是一个可行的解决方案。在本文中,我们将讨论如何使用 Python 将扫描的 PDF 转换为文本 PDF 的步骤。
OCR PDF API
Aspose.PDF Cloud SDK for Python 是 Aspose.PDF Cloud 的包装器。它使您能够在 Python 应用程序中执行所有 PDF 文件处理功能。无需 Adobe Acrobat 或任何其他应用程序即可处理 PDF 文件。因此,要使用 SDK,第一步是安装,可通过 PIP 和 GitHub 存储库下载。现在在终端/命令提示符下执行以下命令以在系统上安装最新版本的 SDK。
pip install asposepdfcloud
微软视觉工作室
您也可以直接在 Visual Studio 项目中的 Python 项目中添加引用。请在Python环境窗口下搜索asposepdfcloud作为包。请按照下图中编号的步骤完成安装过程。

图片 1:- Aspose.PDF Cloud SDK for Python 包。
Aspose.Cloud 仪表盘
由于我们的 API 仅供授权人员访问,因此下一步是在 Aspose.Cloud 仪表板 上创建一个帐户。如果您有 GitHub 或 Google 帐户,只需注册或单击 创建新帐户 按钮并提供所需信息。现在使用凭据登录到仪表板并从仪表板展开应用程序部分并向下滚动到客户端凭据部分以查看客户端 ID 和客户端密码详细信息。
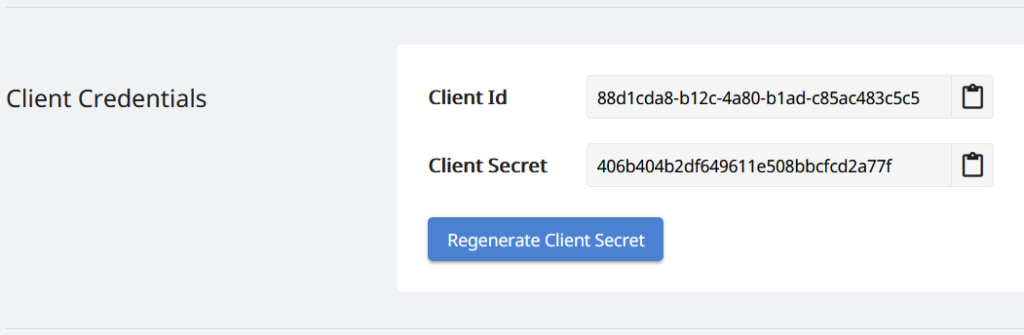
图 2:- Aspose.Cloud 仪表板上的客户端凭证。
在 Python 中将图像 PDF 转换为可搜索的 PDF
请按照以下步骤对扫描的 PDF 文档执行 OCR 操作,然后将其保存为可搜索的(使 pdf 可搜索)。这些步骤帮助我们使用 Python 开发免费的在线 OCR。
- 首先,我们需要创建一个 ApiClient 类的实例,同时提供 Client ID Client Secret 作为参数
- 其次,创建一个 PdfApi 类的实例,它将 ApiClient 对象作为输入参数
- 现在调用 PdfApi 类的 putsearchabledocument(..) 方法,它接受输入 PDF 名称和一个可选参数,指示 OCR 引擎的语言。
def ocrPDF():
try:
#Client credentials
client_secret = "406b404b2df649611e508bbcfcd2a77f"
client_id = "88d1cda8-b12c-4a80-b1ad-c85ac483c5c5"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# 在将 PdfApiClient 作为参数传递时创建 PdfApi 实例
pdf_api = PdfApi(pdf_api_client)
#input PDF file name
input_file = 'image-based-pdf-sample.pdf'
# 调用API进行OCR操作并将输出结果保存在云端
response = pdf_api.put_searchable_document(name=input_file,lang='eng')
# 在控制台中打印消息(可选)
print('Image PDF successfully converted to Text PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
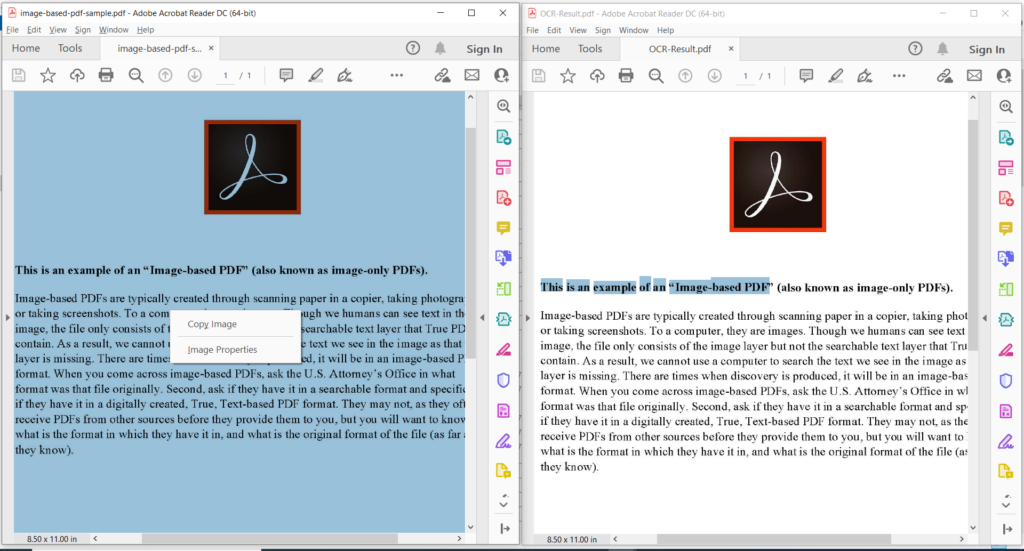
图 3:- PDF OCR 操作预览。
在上图中,左侧部分表示输入的扫描 PDF 文件,右侧部分显示生成的基于文本的 PDF 的预览。上述示例中使用的示例文件可以从 image-based-pdf-sample.pdf 和 OCR-Result.pdf 下载。
使用 cURL 命令在线进行 OCR
REST API 也可以通过 cURL 命令访问,由于我们的 Cloud API 基于 REST 架构,因此我们也可以使用 cURL 命令在线执行 PDF OCR。但是,在继续转换操作之前,我们需要根据您在 Aspose.Cloud 仪表板上指定的个人客户端凭据生成一个 JSON Web 令牌 (JWT)。这是强制性的,因为我们的 API 仅供注册用户访问。请执行以下命令生成 JWT 令牌。
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=88d1cda8-b12c-4a80-b1ad-c85ac483c5c5&client_secret=406b404b2df649611e508bbcfcd2a77f" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
一旦我们有了 JWT 令牌,请执行以下命令来执行 OCR 操作并将输出保存在同一个云存储中。
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/image-based-pdf-sample.pdf/ocr" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
结论
在本文中,我们讨论了使用 Python 代码片段将图像 PDF 转换为可搜索 PDF 的步骤。我们还探讨了如何使用 cURL 命令在线执行 OCR 的详细信息。由于我们的云 SDK 是在 MIT 许可下开发的,因此您可以从 GitHub 下载完整的代码片段并根据您的要求进行更新。我们强烈建议您浏览 开发人员指南,以了解有关 Cloud API 当前提供的其他令人兴奋的功能的更多信息。
如果您有任何相关疑问或在使用我们的 API 时遇到任何问题,请随时通过免费客户支持论坛 与我们联系。
相关文章
我们还建议您阅读以下文章以了解更多信息