
PDF skrár eru mikið notaðar á netinu til að deila upplýsingum og gögnum. Þau eru nokkuð vinsæl vegna þess að þau viðhalda tryggð skjala þegar þau eru skoðuð á hvaða vettvangi sem er. Hins vegar höfum við ekki stjórn á upprunanum og sumum skrám er deilt á skannuðu sniði. Stundum tekur þú mynd sem PDF og síðar þarftu að draga efnið úr skránni. Þannig að raunhæf lausn er að framkvæma OCR aðgerð og draga út textann. Hins vegar, eftir OCR aðgerðina, ef þú þarft að varðveita skrána, þá er umbreyting í PDF snið raunhæf lausn. Í þessari grein ætlum við að ræða skrefin um hvernig á að umbreyta skönnuðu PDF í texta PDF með Python.
OCR PDF API
Aspose.PDF Cloud SDK fyrir Python er umbúðir utan um Aspose.PDF Cloud. Það gerir þér kleift að framkvæma alla PDF skráarvinnslugetu innan Python forritsins. Meðhöndla PDF skrár án Adobe Acrobat eða önnur forrit. Svo til að nota SDK er fyrsta skrefið uppsetning þess og það er hægt að hlaða niður í PIP og GitHub geymslu. Framkvæmdu nú eftirfarandi skipun á flugstöðinni/skipanakvaðningunni til að setja upp nýjustu útgáfuna af SDK á kerfinu.
pip install asposepdfcloud
MS Visual Studio
Þú getur líka bætt tilvísuninni beint við í Python verkefninu þínu innan Visual Studio verkefnisins. Vinsamlegast leitaðu að asposepdfcloud sem pakka undir Python umhverfi glugganum. Vinsamlegast fylgdu skrefunum sem eru númeruð á myndinni hér að neðan til að ljúka uppsetningarferlinu.
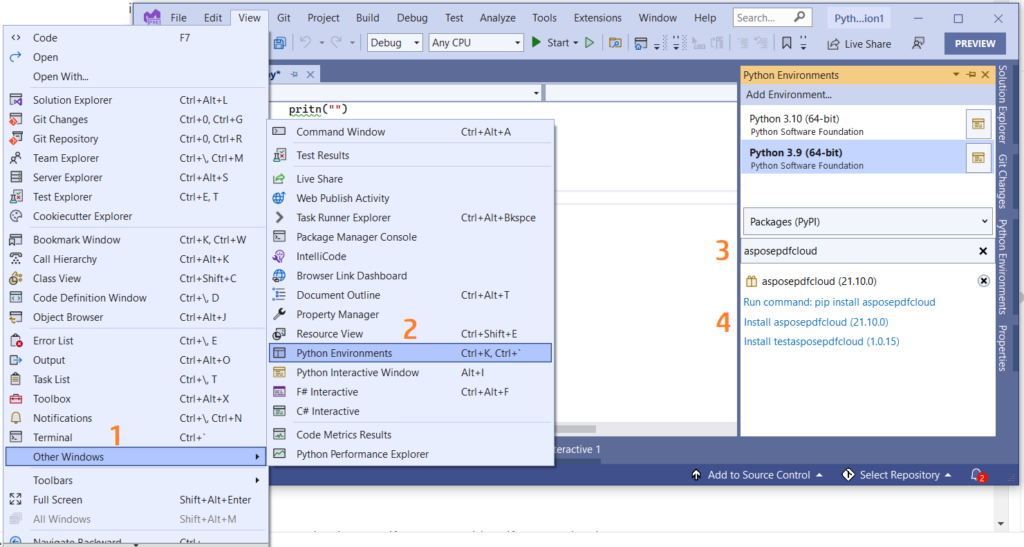
Mynd 1:- Aspose.PDF Cloud SDK fyrir Python pakkann.
Aspose.Cloud mælaborð
Þar sem API okkar eru aðeins aðgengileg viðurkenndum aðilum, þannig að næsta skref er að búa til reikning á Aspose.Cloud mælaborðinu. Ef þú ert með GitHub eða Google reikning, einfaldlega Skráðu þig eða smelltu á Búa til nýjan reikning hnappinn og gefðu upp nauðsynlegar upplýsingar. Skráðu þig nú inn á mælaborðið með því að nota skilríki og stækkaðu forritahlutann frá mælaborðinu og skrunaðu niður að hlutanum viðskiptavinaskilríki til að sjá viðskiptavinaauðkenni og leyndarmál viðskiptavinar.
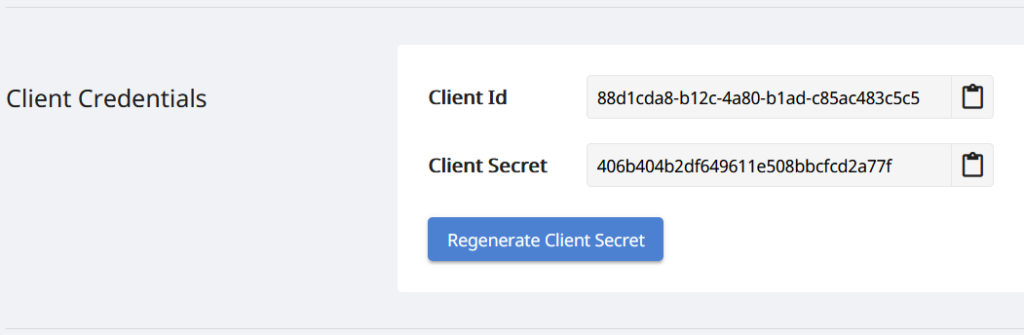
Mynd 2:- Viðskiptavinaskilríki á Aspose.Cloud mælaborðinu.
Mynda PDF yfir í leitanlegt PDF í Python
Vinsamlega fylgdu skrefunum hér að neðan til að framkvæma OCR-aðgerð á skönnuðu PDF skjali og vistaðu það síðan sem leitarhæft (gerðu pdf leitarhæft). Þessi skref hjálpa okkur að þróa ókeypis OCR á netinu með Python.
- Í fyrsta lagi þurfum við að búa til tilvik af ApiClient flokki á meðan að veita Client ID Client Secret sem rök
- Í öðru lagi, búðu til tilvik af PdfApi flokki sem tekur ApiClient hlut sem inntaksrök
- Hringdu nú í putsearchabledocument(..) aðferðina í PdfApi flokki sem tekur inn PDF nafn og valfrjálsa færibreytu sem gefur til kynna tungumál OCR vélarinnar.
def ocrPDF():
try:
#Client credentials
client_secret = "406b404b2df649611e508bbcfcd2a77f"
client_id = "88d1cda8-b12c-4a80-b1ad-c85ac483c5c5"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# búðu til PdfApi tilvik á meðan þú sendir PdfApiClient sem rök
pdf_api = PdfApi(pdf_api_client)
#input PDF file name
input_file = 'image-based-pdf-sample.pdf'
# hringdu í API til að framkvæma OCR aðgerð og vista úttakið í skýjageymslu
response = pdf_api.put_searchable_document(name=input_file,lang='eng')
# prenta skilaboð í stjórnborði (valfrjálst)
print('Image PDF successfully converted to Text PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
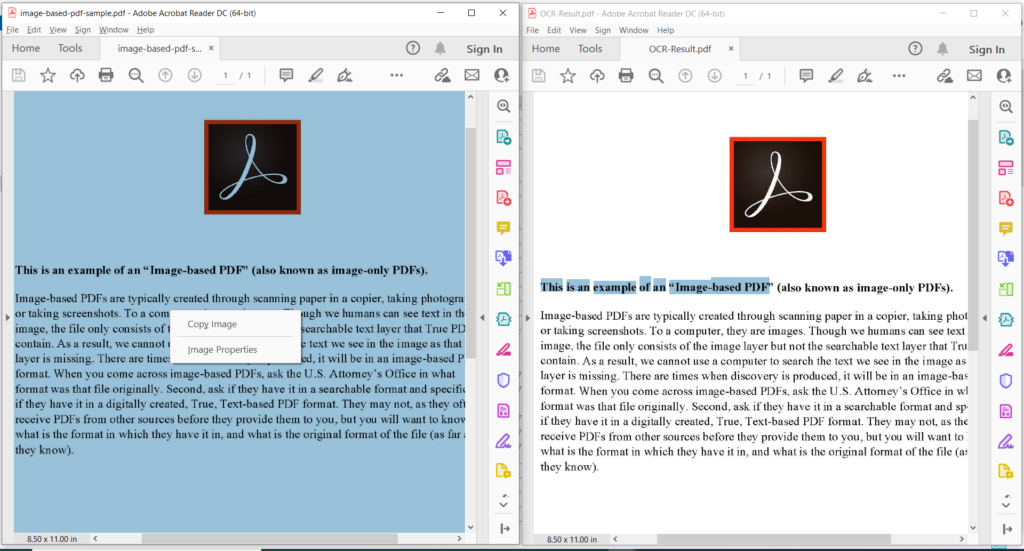
Mynd 3: - Forskoðun á PDF OCR aðgerð.
Á myndinni hér að ofan táknar vinstri hluti inntaksskannuðu PDF-skjalsins og hlutinn hægra megin sýnir forskoðun á texta-undirstaða PDF. Sýnisskrárnar sem notaðar eru í dæminu hér að ofan er hægt að hlaða niður frá image-based-pdf-sample.pdf og OCR-Result.pdf.
OCR á netinu með cURL skipunum
REST API er einnig hægt að nálgast með cURL skipunum og þar sem Cloud API er byggt á REST arkitektúr, þannig að við getum líka notað cURL skipunina til að framkvæma PDF OCR á netinu. Hins vegar, áður en haldið er áfram með umbreytingaraðgerðir, þurfum við að búa til JSON Web Token (JWT) byggt á einstökum persónuskilríkjum viðskiptavinarins sem tilgreind eru á Aspose.Cloud mælaborðinu. Það er skylda vegna þess að API okkar eru aðeins aðgengileg skráðum notendum. Vinsamlegast framkvæmið eftirfarandi skipun til að búa til JWT táknið.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=88d1cda8-b12c-4a80-b1ad-c85ac483c5c5&client_secret=406b404b2df649611e508bbcfcd2a77f" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Þegar við höfum JWT táknið skaltu framkvæma eftirfarandi skipun til að framkvæma OCR aðgerðina og vista úttakið í sömu skýgeymslu.
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/image-based-pdf-sample.pdf/ocr" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Niðurstaða
Í þessari grein höfum við fjallað um skrefin til að mynda PDF í leitanlegt PDF með Python kóðabút. Við höfum einnig kannað upplýsingar um hvernig á að framkvæma OCR á netinu með því að nota cURL skipanirnar. Þar sem SDK-skjölin okkar í skýinu eru þróuð undir MIT leyfi, þannig að þú getur halað niður öllum kóðabútinum frá GitHub og uppfært það í samræmi við kröfur þínar. Við mælum eindregið með því að þú skoðir Hönnunarhandbókina til að læra meira um aðra spennandi eiginleika sem Cloud API býður upp á.
Ef þú hefur einhverjar tengdar fyrirspurnir eða þú lendir í vandræðum þegar þú notar forritaskilin okkar skaltu ekki hika við að hafa samband við okkur í gegnum ókeypis þjónustuborð.
tengdar greinar
Við mælum líka með því að fara í gegnum eftirfarandi greinar til að læra meira um