
Файли PDF широко використовуються в Інтернеті для обміну інформацією та даними. Вони досить популярні, оскільки зберігають точність документів при перегляді на будь-якій платформі. Однак ми не контролюємо джерело, і деякі файли надаються у відсканованому форматі. Іноді ви захоплюєте зображення у форматі PDF, а потім вам потрібно витягнути вміст із файлу. Таким чином, життєздатним рішенням є виконання операції розпізнавання тексту та вилучення тексту. Однак, якщо після операції OCR вам потрібно зберегти файл, перетворення у формат PDF є життєздатним рішенням. У цій статті ми обговоримо кроки, як перетворити сканований PDF-файл у текстовий PDF-файл за допомогою Python.
OCR PDF API
Aspose.PDF Cloud SDK для Python є оболонкою Aspose.PDF Cloud. Він дає змогу виконувати всі можливості обробки PDF-файлів у програмі Python. Керуйте файлами PDF без Adobe Acrobat або будь-якої іншої програми. Отже, щоб використовувати SDK, першим кроком є його встановлення, і він доступний для завантаження через PIP і GitHub репозиторій. Тепер виконайте наступну команду в терміналі/командному рядку, щоб інсталювати останню версію SDK у системі.
pip install asposepdfcloud
MS Visual Studio
Ви також можете безпосередньо додати посилання у свій проект Python у проекті Visual Studio. Виконайте пошук asposepdfcloud як пакет у вікні середовища Python. Будь ласка, виконайте кроки, пронумеровані на зображенні нижче, щоб завершити процес встановлення.

Зображення 1:- Aspose.PDF Cloud SDK для пакета Python.
Інформаційна панель Aspose.Cloud
Оскільки наші API доступні лише авторизованим особам, наступним кроком є створення облікового запису на інформаційній панелі Aspose.Cloud. Якщо у вас є обліковий запис GitHub або Google, просто зареєструйтеся або натисніть кнопку Створити новий обліковий запис і надайте необхідну інформацію. Тепер увійдіть на інформаційну панель, використовуючи облікові дані, розгорніть розділ «Програми» на інформаційній панелі та прокрутіть униз до розділу «Облікові дані клієнта», щоб переглянути дані про ідентифікатор клієнта та секрет клієнта.
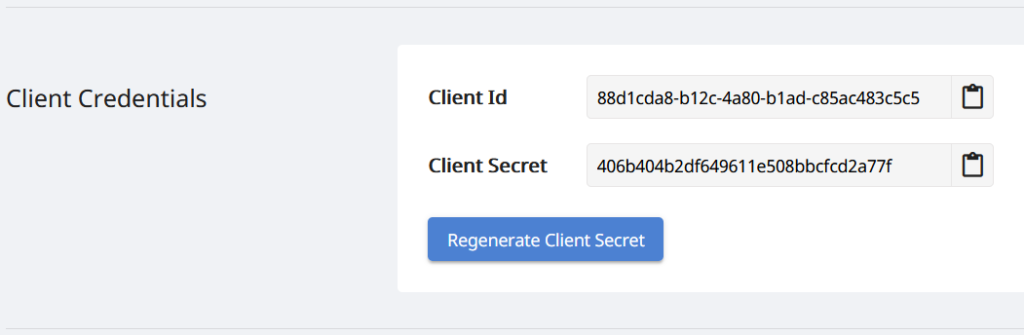
Зображення 2: облікові дані клієнта на інформаційній панелі Aspose.Cloud.
Зображення PDF у PDF із можливістю пошуку в Python
Будь ласка, виконайте наведені нижче кроки, щоб виконати операцію оптичного розпізнавання тексту на відсканованому PDF-документі, а потім зберегти його як доступний для пошуку (зробити PDF доступним для пошуку). Ці кроки допоможуть нам розробити безкоштовне оптичне розпізнавання символів онлайн за допомогою Python.
- По-перше, нам потрібно створити екземпляр класу ApiClient, надаючи як аргументи Client ID Client Secret
- По-друге, створіть екземпляр класу PdfApi, який приймає об’єкт ApiClient як вхідний аргумент
- Тепер викличте метод putsearchabledocument(..) класу PdfApi, який приймає назву вхідного PDF-файлу та необов’язковий параметр, що вказує мову механізму OCR.
def ocrPDF():
try:
#Client credentials
client_secret = "406b404b2df649611e508bbcfcd2a77f"
client_id = "88d1cda8-b12c-4a80-b1ad-c85ac483c5c5"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# створити екземпляр PdfApi, передаючи PdfApiClient як аргумент
pdf_api = PdfApi(pdf_api_client)
#input PDF file name
input_file = 'image-based-pdf-sample.pdf'
# виклик API для виконання операції OCR і збереження результату в хмарному сховищі
response = pdf_api.put_searchable_document(name=input_file,lang='eng')
# друкувати повідомлення в консолі (необов'язково)
print('Image PDF successfully converted to Text PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
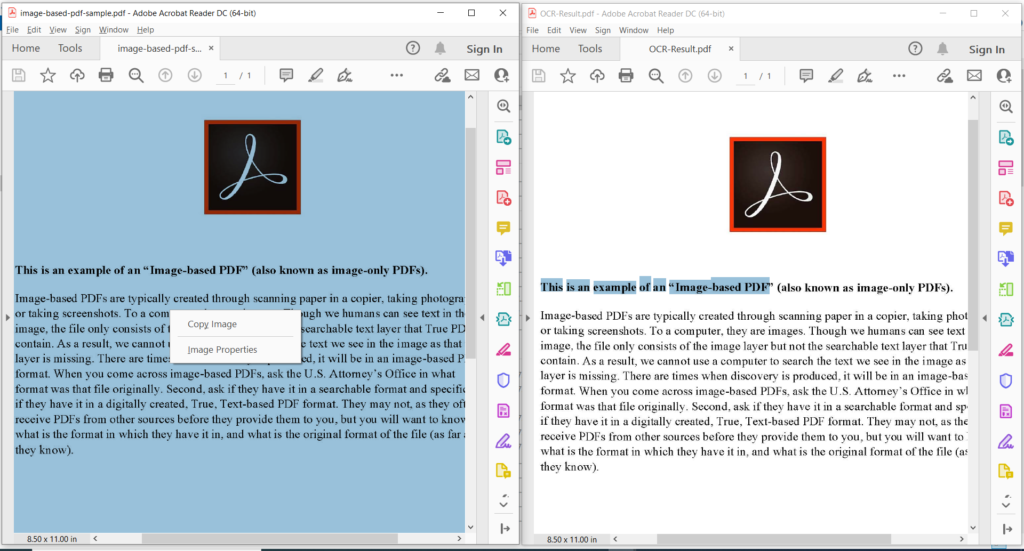
Зображення 3: - Попередній перегляд роботи PDF OCR.
На зображенні вище ліва частина позначає вхідний відсканований файл PDF, а частина праворуч показує попередній перегляд отриманого текстового PDF-файлу. Зразки файлів, використаних у наведеному вище прикладі, можна завантажити з image-based-pdf-sample.pdf і OCR-Result.pdf.
OCR онлайн за допомогою команд cURL
До REST API також можна отримати доступ за допомогою команд cURL, а оскільки наші хмарні API засновані на архітектурі REST, ми також можемо використовувати команду cURL для OCR PDF онлайн. Однак перш ніж продовжити операцію перетворення, нам потрібно створити веб-токен JSON (JWT) на основі облікових даних вашого індивідуального клієнта, указаних на інформаційній панелі Aspose.Cloud. Це обов’язково, оскільки наші API доступні лише зареєстрованим користувачам. Виконайте наступну команду, щоб створити маркер JWT.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=88d1cda8-b12c-4a80-b1ad-c85ac483c5c5&client_secret=406b404b2df649611e508bbcfcd2a77f" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Отримавши маркер JWT, виконайте наведену нижче команду, щоб виконати операцію OCR і зберегти результат у тому самому хмарному сховищі.
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/image-based-pdf-sample.pdf/ocr" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Висновок
У цій статті ми обговорили кроки для перетворення зображень PDF у PDF із можливістю пошуку за допомогою фрагмента коду Python. Ми також дослідили деталі того, як виконувати OCR онлайн за допомогою команд cURL. Оскільки наші хмарні SDK розробляються згідно з ліцензією MIT, ви можете завантажити повний фрагмент коду з GitHub і оновити його відповідно до своїх вимог. Ми настійно рекомендуємо вам ознайомитися з Посібником розробника, щоб дізнатися більше про інші захоплюючі функції, які зараз пропонує Cloud API.
Якщо у вас виникли пов’язані запитання або виникли проблеми під час використання наших API, зв’яжіться з нами через безкоштовний форум підтримки клієнтів.
Схожі статті
Ми також пропонуємо переглянути наступні статті, щоб дізнатися більше