
पीडीएफ फाइलें सूचना और डेटा साझा करने के लिए इंटरनेट पर व्यापक रूप से उपयोग की जाती हैं। वे काफी लोकप्रिय हैं क्योंकि वे किसी भी मंच पर देखते समय दस्तावेज़ों की सत्यनिष्ठा बनाए रखते हैं। हालाँकि, हमारा स्रोत पर नियंत्रण नहीं है और कुछ फ़ाइलें स्कैन किए गए प्रारूप में साझा की जाती हैं। कभी-कभी आप एक छवि को पीडीएफ के रूप में कैप्चर करते हैं और बाद में आपको फ़ाइल से सामग्री निकालने की आवश्यकता होती है। तो एक व्यवहार्य समाधान एक ओसीआर ऑपरेशन करना और टेक्स्ट निकालना है। हालाँकि, OCR ऑपरेशन के बाद, यदि आपको फ़ाइल को संरक्षित करने की आवश्यकता है, तो PDF प्रारूप में रूपांतरण एक व्यवहार्य समाधान है। इस लेख में, हम पायथन का उपयोग करके स्कैन की गई पीडीएफ को टेक्स्ट पीडीएफ में कैसे परिवर्तित करें, इस पर चर्चा करने जा रहे हैं।
ओसीआर पीडीएफ एपीआई
Python के लिए Aspose.PDF Cloud SDK Aspose.PDF Cloud के चारों ओर एक आवरण है। यह आपको पायथन एप्लिकेशन के भीतर सभी पीडीएफ फाइल प्रोसेसिंग क्षमताओं को करने में सक्षम बनाता है। Adobe Acrobat या किसी अन्य एप्लिकेशन के बिना PDF फ़ाइलों में हेरफेर करें। तो एसडीके का उपयोग करने के लिए, पहला कदम इसकी स्थापना है, और यह पीआईपी और गिटहब रिपॉजिटरी पर डाउनलोड के लिए उपलब्ध है। अब सिस्टम पर एसडीके के नवीनतम संस्करण को स्थापित करने के लिए टर्मिनल/कमांड प्रॉम्प्ट पर निम्न आदेश निष्पादित करें।
pip install asposepdfcloud
एमएस विजुअल स्टूडियो
आप विजुअल स्टूडियो प्रोजेक्ट के भीतर सीधे अपने पायथन प्रोजेक्ट में भी संदर्भ जोड़ सकते हैं। कृपया पायथन पर्यावरण विंडो के तहत asposepdfcloud को एक पैकेज के रूप में खोजें। स्थापना प्रक्रिया को पूरा करने के लिए कृपया नीचे दी गई छवि में क्रमांकित चरणों का पालन करें।

इमेज 1:- पायथन पैकेज के लिए Aspose.PDF क्लाउड एसडीके।
Aspose.Cloud डैशबोर्ड
चूंकि हमारे एपीआई केवल अधिकृत व्यक्तियों के लिए सुलभ हैं, इसलिए अगला कदम Aspose.Cloud डैशबोर्ड पर एक खाता बनाना है। यदि आपके पास गिटहब या Google खाता है, तो बस साइन अप करें या नया खाता बनाएं बटन पर क्लिक करें और आवश्यक जानकारी प्रदान करें। अब क्रेडेंशियल्स का उपयोग करके डैशबोर्ड में लॉगिन करें और डैशबोर्ड से एप्लिकेशन सेक्शन का विस्तार करें और क्लाइंट आईडी और क्लाइंट सीक्रेट विवरण देखने के लिए क्लाइंट क्रेडेंशियल्स अनुभाग की ओर स्क्रॉल करें।
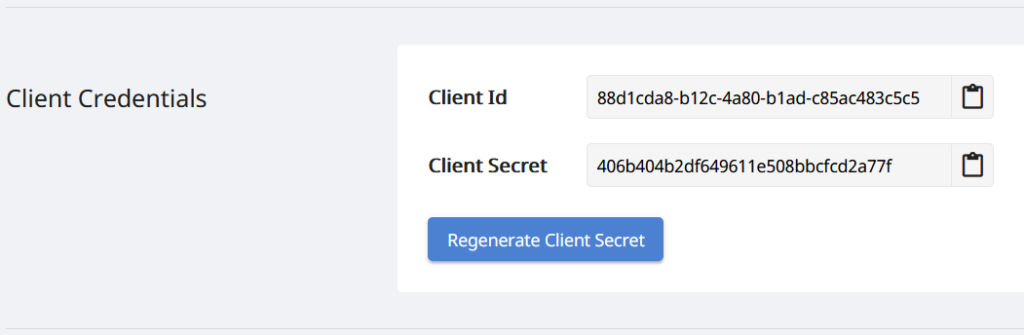
इमेज 2:- Aspose.Cloud डैशबोर्ड पर क्लाइंट क्रेडेंशियल्स।
पायथन में खोज योग्य पीडीएफ के लिए छवि पीडीएफ
स्कैन किए गए पीडीएफ दस्तावेज़ पर ओसीआर ऑपरेशन करने के लिए कृपया नीचे दिए गए चरणों का पालन करें और फिर इसे खोज योग्य (पीडीएफ खोज योग्य बनाएं) के रूप में सहेजें। ये कदम हमें पायथन का उपयोग करके मुफ्त ऑनलाइन ओसीआर विकसित करने में मदद करते हैं।
- सबसे पहले, हमें Client ID Client Secret को तर्क के रूप में प्रदान करते हुए ApiClient वर्ग का एक उदाहरण बनाने की आवश्यकता है
- दूसरे, PdfApi वर्ग का एक उदाहरण बनाएँ जो ApiClient ऑब्जेक्ट को इनपुट तर्क के रूप में लेता है
- अब PdfApi वर्ग की putsearchabledocument(..) विधि को कॉल करें जो इनपुट PDF नाम और OCR इंजन की भाषा का संकेत देने वाला एक वैकल्पिक पैरामीटर लेती है।
def ocrPDF():
try:
#Client credentials
client_secret = "406b404b2df649611e508bbcfcd2a77f"
client_id = "88d1cda8-b12c-4a80-b1ad-c85ac483c5c5"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# PdfApiClient को तर्क के रूप में पारित करते समय PdfApi उदाहरण बनाएँ
pdf_api = PdfApi(pdf_api_client)
#input PDF file name
input_file = 'image-based-pdf-sample.pdf'
# OCR ऑपरेशन करने के लिए API को कॉल करें और आउटपुट को क्लाउड स्टोरेज में सेव करें
response = pdf_api.put_searchable_document(name=input_file,lang='eng')
# कंसोल में प्रिंट संदेश (वैकल्पिक)
print('Image PDF successfully converted to Text PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
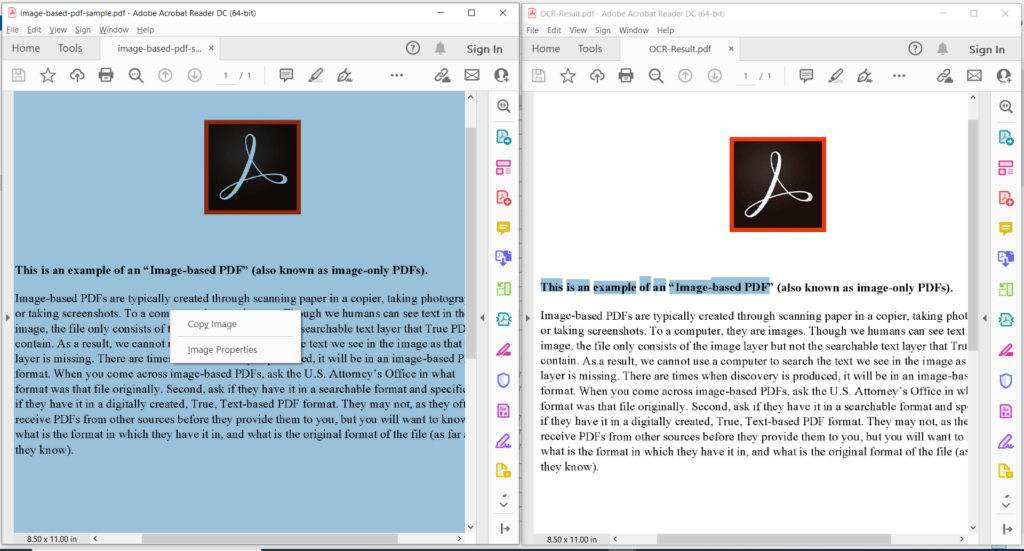
इमेज 3:- पीडीएफ ओसीआर ऑपरेशन का पूर्वावलोकन।
ऊपर की छवि में, बायाँ भाग इनपुट स्कैन की गई PDF फ़ाइल को दर्शाता है और दाईं ओर का भाग परिणामी टेक्स्ट-आधारित PDF का पूर्वावलोकन दिखाता है। उपरोक्त उदाहरण में उपयोग की गई नमूना फ़ाइलें image-based-pdf-sample.pdf और OCR-Result.pdf से डाउनलोड की जा सकती हैं।
ओसीआर ऑनलाइन कर्ल कमांड का उपयोग कर
REST API को cURL कमांड के माध्यम से भी एक्सेस किया जा सकता है और चूंकि हमारे क्लाउड API REST आर्किटेक्चर पर आधारित हैं, इसलिए हम cURL कमांड का उपयोग PDF OCR को ऑनलाइन करने के लिए भी कर सकते हैं। हालाँकि, रूपांतरण ऑपरेशन के साथ आगे बढ़ने से पहले, हमें Aspose.Cloud डैशबोर्ड पर निर्दिष्ट आपके व्यक्तिगत क्लाइंट क्रेडेंशियल्स के आधार पर एक JSON वेब टोकन (JWT) उत्पन्न करने की आवश्यकता है। यह अनिवार्य है क्योंकि हमारे एपीआई केवल पंजीकृत उपयोगकर्ताओं के लिए ही सुलभ हैं। जेडब्ल्यूटी टोकन उत्पन्न करने के लिए कृपया निम्न आदेश निष्पादित करें।
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=88d1cda8-b12c-4a80-b1ad-c85ac483c5c5&client_secret=406b404b2df649611e508bbcfcd2a77f" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
एक बार हमारे पास JWT टोकन होने के बाद, कृपया OCR ऑपरेशन करने के लिए निम्न कमांड निष्पादित करें और उसी क्लाउड स्टोरेज में आउटपुट को सेव करें।
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/image-based-pdf-sample.pdf/ocr" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
निष्कर्ष
इस लेख में, हमने पायथन कोड स्निपेट का उपयोग करके छवि पीडीएफ से खोज योग्य पीडीएफ के चरणों पर चर्चा की है। हमने cURL कमांड का उपयोग करके OCR ऑनलाइन प्रदर्शन करने के तरीके के विवरण का भी पता लगाया है। चूंकि हमारे क्लाउड SDK MIT लाइसेंस के तहत विकसित किए गए हैं, इसलिए आप GitHub से पूरा कोड स्निपेट डाउनलोड कर सकते हैं और इसे अपनी आवश्यकताओं के अनुसार अपडेट कर सकते हैं। क्लाउड एपीआई द्वारा वर्तमान में दी जा रही अन्य रोमांचक सुविधाओं के बारे में अधिक जानने के लिए हम आपको डेवलपर गाइड का पता लगाने की अत्यधिक सलाह देते हैं।
यदि आपके कोई संबंधित प्रश्न हैं या आप हमारे एपीआई का उपयोग करते समय किसी भी समस्या का सामना करते हैं, तो कृपया बेझिझक हमसे मुफ्त ग्राहक सहायता फोरम के माध्यम से संपर्क करें।
संबंधित आलेख
इसके बारे में अधिक जानने के लिए हम निम्नलिखित लेखों को पढ़ने का भी सुझाव देते हैं