
PDF lêers word wyd oor die internet gebruik vir inligting en data deel. Hulle is baie gewild omdat hulle die getrouheid van dokumente handhaaf wanneer hulle op enige platform bekyk word. Ons het egter nie beheer oor die bron nie en sommige lêers word in geskandeerde formaat gedeel. Soms neem jy ’n prent as ’n PDF vas en later moet jy die inhoud uit die lêer onttrek. Dus ’n lewensvatbare oplossing is om ’n OCR-operasie uit te voer en die teks te onttrek. As u egter na die OCR-operasie die lêer moet bewaar, is omskakeling na PDF-formaat ’n lewensvatbare oplossing. In hierdie artikel gaan ons die stappe bespreek oor hoe om ’n geskandeerde PDF na teks PDF om te skakel met Python.
OCR PDF API
Aspose.PDF Wolk SDK vir Python is ’n omhulsel rondom Aspose.PDF Wolk. Dit stel jou in staat om alle PDF-lêerverwerkingsvermoëns binne die Python-toepassing uit te voer. Manipuleer PDF-lêers sonder Adobe Acrobat of enige ander toepassing. Dus om die SDK te gebruik, is die eerste stap die installasie daarvan, en dit is beskikbaar vir aflaai oor PIP en GitHub bewaarplek. Voer nou die volgende opdrag op die terminale/opdragprompt uit om die nuutste weergawe van SDK op die stelsel te installeer.
pip install asposepdfcloud
MS Visual Studio
U kan ook die verwysing direk in u Python-projek binne die Visual Studio-projek byvoeg. Soek asseblief asposepdfcloud as ’n pakket onder die Python-omgewingsvenster. Volg asseblief die stappe genommer in die prent hieronder om die installasieproses te voltooi.
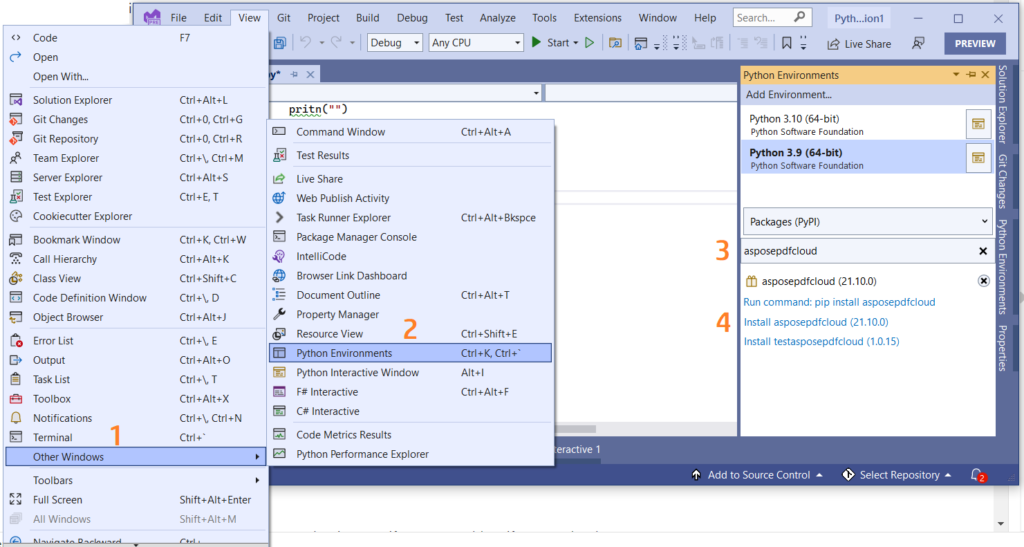
Beeld 1:- Aspose.PDF Wolk SDK vir Python-pakket.
Aspose.Wolk Dashboard
Aangesien ons API’s slegs vir gemagtigde persone toeganklik is, is die volgende stap dus om ’n rekening op Aspose.Cloud-dashboard te skep. As jy ’n GitHub- of Google-rekening het, teken eenvoudig aan of klik op die Skep ’n nuwe rekening-knoppie en verskaf die vereiste inligting. Meld nou aan by die dashboard deur gebruik te maak van geloofsbriewe en brei die Toepassings-afdeling vanaf die dashboard uit en blaai af na die Kliëntbewyse-afdeling om Kliënt-ID en Kliëntgeheime besonderhede te sien.
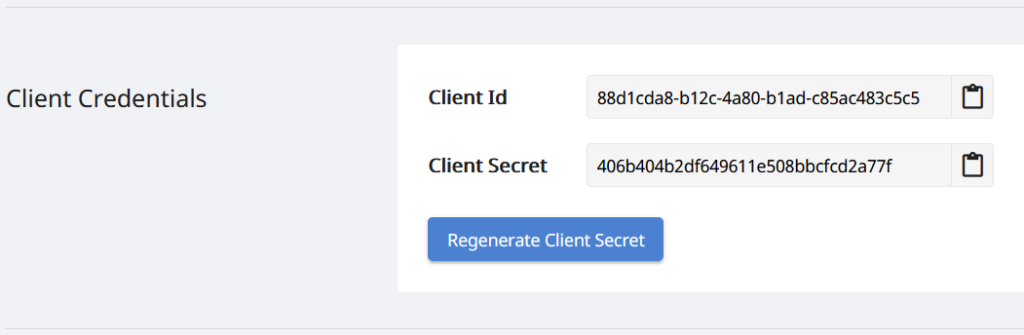
Beeld 2:- Kliënt geloofsbriewe op Aspose.Cloud dashboard.
Prent PDF na soekbare PDF in Python
Volg asseblief die stappe hieronder gegee om OCR-bewerking op ’n geskandeerde PDF-dokument uit te voer en stoor dit dan as ’n soekbare (maak pdf soekbaar). Hierdie stappe help ons om gratis aanlyn OCR met Python te ontwikkel.
- Eerstens moet ons ’n instansie van ApiClient-klas skep terwyl ons Client ID Client Secret as argumente verskaf
- Tweedens, skep ’n instansie van PdfApi-klas wat ApiClient-objek as invoerargument neem
- Roep nou die putsearchabledocument(..)-metode van PdfApi-klas wat insette PDF-naam en ’n opsionele parameter neem wat die taal van OCR-enjin aandui.
def ocrPDF():
try:
#Client credentials
client_secret = "406b404b2df649611e508bbcfcd2a77f"
client_id = "88d1cda8-b12c-4a80-b1ad-c85ac483c5c5"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# skep PdfApi-instansie terwyl PdfApiClient as argument deurgee
pdf_api = PdfApi(pdf_api_client)
#input PDF file name
input_file = 'image-based-pdf-sample.pdf'
# bel die API om OCR-bewerking uit te voer en die uitset in wolkberging te stoor
response = pdf_api.put_searchable_document(name=input_file,lang='eng')
# druk boodskap in konsole (opsioneel)
print('Image PDF successfully converted to Text PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)

Beeld 3: - Voorskou van PDF OCR-bewerking.
In die prent hierbo dui die linkergedeelte die insette geskandeerde PDF-lêer aan en die gedeelte aan die regterkant wys ’n voorskou van die gevolglike teksgebaseerde PDF. Die voorbeeldlêers wat in die voorbeeld hierbo gebruik word, kan afgelaai word vanaf image-based-pdf-sample.pdf en OCR-Result.pdf.
OCR aanlyn met behulp van cURL-opdragte
Die REST API’s kan ook verkry word via cURL-opdragte en aangesien ons Wolk-API’s op REST-argitektuur gebaseer is, kan ons ook die cURL-opdrag gebruik om PDF OCR aanlyn uit te voer. Voordat ons egter met omskakeling voortgaan, moet ons ’n JSON Web Token (JWT) genereer gebaseer op jou individuele kliënt geloofsbriewe gespesifiseer oor Aspose.Cloud dashboard. Dit is verpligtend omdat ons API’s slegs vir geregistreerde gebruikers toeganklik is. Voer asseblief die volgende opdrag uit om die JWT-token te genereer.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=88d1cda8-b12c-4a80-b1ad-c85ac483c5c5&client_secret=406b404b2df649611e508bbcfcd2a77f" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Sodra ons die JWT-token het, voer asseblief die volgende opdrag uit om die OCR-bewerking uit te voer en die uitvoer in dieselfde wolkberging te stoor.
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/image-based-pdf-sample.pdf/ocr" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Afsluiting
In hierdie artikel het ons die stappe bespreek om PDF na soekbare PDF te prent met behulp van Python-kodebrokkie. Ons het ook die besonderhede ondersoek oor hoe om OCR aanlyn uit te voer met behulp van die cURL-opdragte. Aangesien ons wolk-SDK’s onder MIT-lisensie ontwikkel is, kan u die volledige kodebrokkie van GitHub aflaai en dit volgens u vereistes opdateer. Ons beveel jou sterk aan om die Ontwikkelaargids te verken om meer te wete te kom oor ander opwindende kenmerke wat tans deur Cloud API aangebied word.
As jy enige verwante navrae het of enige probleme ondervind tydens die gebruik van ons API’s, voel asseblief vry om ons te kontak via die gratis kliëntediensforum.
verwante artikels
Ons stel ook voor dat u deur die volgende artikels gaan om meer te wete te kom