
Los archivos PDF se utilizan ampliamente en Internet para compartir información y datos. Son bastante populares porque mantienen la fidelidad de los documentos cuando se visualizan en cualquier plataforma. Sin embargo, no tenemos control sobre la fuente y algunos archivos se comparten en formato escaneado. A veces captura una imagen como PDF y luego necesita extraer el contenido del archivo. Entonces, una solución viable es realizar una operación de OCR y extraer el texto. Sin embargo, después de la operación OCR, si necesita conservar el archivo, la conversión a formato PDF es una solución viable. En este artículo, vamos a discutir los pasos sobre cómo convertir un PDF escaneado a PDF de texto usando Python.
- API de OCR PDF
- PDF de imagen a PDF con capacidad de búsqueda en Python
- OCR en línea usando comandos cURL
API de OCR PDF
Aspose.PDF Cloud SDK for Python es un contenedor de Aspose.PDF Cloud. Le permite realizar todas las capacidades de procesamiento de archivos PDF dentro de la aplicación Python. Manipule archivos PDF sin Adobe Acrobat o cualquier otra aplicación. Entonces, para usar el SDK, el primer paso es su instalación, y está disponible para su descarga a través del repositorio PIP y GitHub. Ahora ejecute el siguiente comando en la terminal/símbolo del sistema para instalar la última versión de SDK en el sistema.
pip install asposepdfcloud
MS Visual Studio
También puede agregar directamente la referencia en su proyecto de Python dentro del proyecto de Visual Studio. Busque asposepdfcloud como un paquete en la ventana del entorno de Python. Siga los pasos enumerados en la imagen a continuación para completar el proceso de instalación.
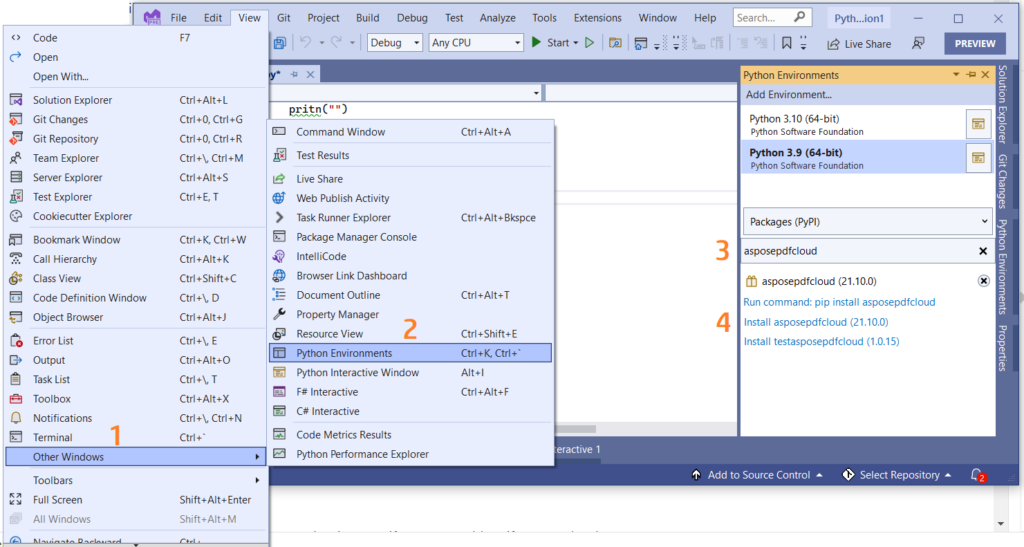
Imagen 1: - Paquete Aspose.PDF Cloud SDK para Python.
Tablero de Aspose.Cloud
Dado que nuestras API solo son accesibles para personas autorizadas, el siguiente paso es crear una cuenta en Aspose.Cloud Dashboard. Si tiene una cuenta de GitHub o Google, simplemente regístrese o haga clic en el botón Crear una nueva cuenta y proporcione la información requerida. Ahora inicie sesión en el tablero usando las credenciales y expanda la sección Aplicaciones desde el tablero y desplácese hacia abajo hasta la sección Credenciales del cliente para ver los detalles del ID del cliente y el Secreto del cliente.
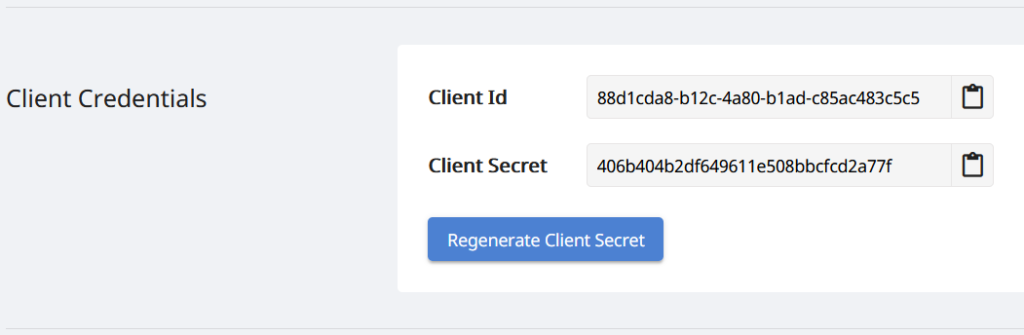
Imagen 2: - Credenciales de cliente en el panel de control de Aspose.Cloud.
PDF de imagen a PDF con capacidad de búsqueda en Python
Siga los pasos que se indican a continuación para realizar la operación de OCR en un documento PDF escaneado y luego guárdelo como un archivo de búsqueda (haga que el PDF se pueda buscar). Estos pasos nos ayudan a desarrollar OCR en línea gratuito usando Python.
- Primero, necesitamos crear una instancia de la clase ApiClient mientras proporcionamos Client ID Client Secret como argumentos
- En segundo lugar, cree una instancia de la clase PdfApi que tome el objeto ApiClient como argumento de entrada
- Ahora llame al método putsearchabledocument(..) de la clase PdfApi que toma el nombre del PDF de entrada y un parámetro opcional que indica el idioma del motor OCR.
def ocrPDF():
try:
#Client credentials
client_secret = "406b404b2df649611e508bbcfcd2a77f"
client_id = "88d1cda8-b12c-4a80-b1ad-c85ac483c5c5"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# cree una instancia de PdfApi mientras pasa PdfApiClient como argumento
pdf_api = PdfApi(pdf_api_client)
#input PDF file name
input_file = 'image-based-pdf-sample.pdf'
# llame a la API para realizar la operación de OCR y guarde la salida en el almacenamiento en la nube
response = pdf_api.put_searchable_document(name=input_file,lang='eng')
# imprimir mensaje en consola (opcional)
print('Image PDF successfully converted to Text PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
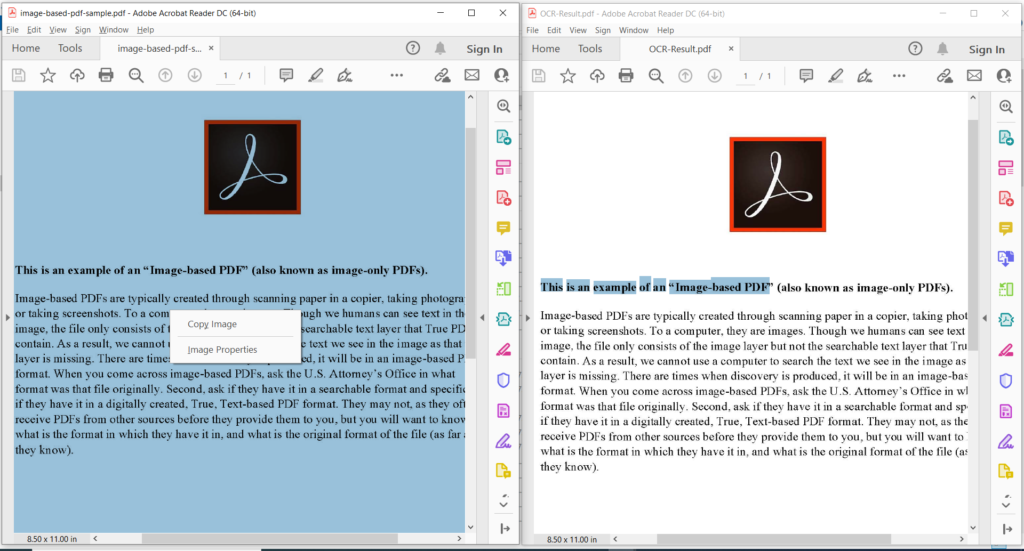
Imagen 3:- Vista previa de la operación PDF OCR.
En la imagen de arriba, la parte izquierda indica el archivo PDF escaneado de entrada y la parte del lado derecho muestra una vista previa del PDF resultante basado en texto. Los archivos de muestra utilizados en el ejemplo anterior se pueden descargar desde image-based-pdf-sample.pdf y OCR-Result.pdf.
OCR en línea usando comandos cURL
También se puede acceder a las API REST a través de los comandos cURL y, dado que nuestras API en la nube se basan en la arquitectura REST, también podemos usar el comando cURL para realizar PDF OCR en línea. Sin embargo, antes de continuar con la operación de conversión, debemos generar un token web JSON (JWT) basado en las credenciales de su cliente individual especificadas en el panel de control de Aspose.Cloud. Es obligatorio porque nuestras API solo son accesibles para usuarios registrados. Ejecute el siguiente comando para generar el token JWT.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=88d1cda8-b12c-4a80-b1ad-c85ac483c5c5&client_secret=406b404b2df649611e508bbcfcd2a77f" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Una vez que tengamos el token JWT, ejecute el siguiente comando para realizar la operación de OCR y guardar la salida en el mismo almacenamiento en la nube.
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/image-based-pdf-sample.pdf/ocr" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Conclusión
En este artículo, hemos discutido los pasos para convertir PDF de imagen a PDF con capacidad de búsqueda usando un fragmento de código de Python. También hemos explorado los detalles sobre cómo realizar OCR en línea usando los comandos cURL. Como nuestros SDK en la nube se desarrollan bajo la licencia MIT, puede descargar el fragmento de código completo de GitHub y actualizarlo según sus requisitos. Le recomendamos encarecidamente que explore la Guía para desarrolladores para obtener más información sobre otras funciones interesantes que actualmente ofrece Cloud API.
En caso de que tenga alguna consulta relacionada o encuentre algún problema al usar nuestras API, no dude en contactarnos a través del foro gratuito de atención al cliente.
Artículos relacionados
También sugerimos leer los siguientes artículos para obtener más información sobre