
PDF-faile kasutatakse Internetis teabe ja andmete jagamiseks laialdaselt. Need on üsna populaarsed, kuna säilitavad mis tahes platvormil vaatamisel dokumentide truuduse. Siiski ei ole meil allika üle kontrolli ja mõnda faili jagatakse skannitud vormingus. Mõnikord jäädvustate pildi PDF-vormingus ja hiljem peate failist sisu välja võtma. Seega on elujõuline lahendus sooritada OCR-operatsioon ja eraldada tekst. Kui aga pärast OCR-i toimingut on vaja fail säilitada, on PDF-vormingusse teisendamine mõistlik lahendus. Selles artiklis käsitleme samme, kuidas muuta skannitud PDF-fail Pythoni abil teksti-PDF-iks.
OCR PDF API
Aspose.PDF Cloud SDK Pythoni jaoks on ümbris Aspose.PDF Cloud ümber. See võimaldab teil Pythoni rakenduses kasutada kõiki PDF-failide töötlemise võimalusi. PDF-failidega manipuleerimine ilma Adobe Acrobati või mõne muu rakenduseta. Nii et SDK kasutamiseks on esimene samm selle installimine ja see on allalaadimiseks saadaval hoidla PIP ja GitHub kaudu. Nüüd käivitage terminalis/käsuviibal järgmine käsk, et installida süsteemi SDK uusim versioon.
pip install asposepdfcloud
MS Visual Studio
Samuti saate viite otse lisada oma Pythoni projekti Visual Studio projektis. Otsige Pythoni keskkonnaakna all paketina asposepdfcloud. Installimise lõpuleviimiseks järgige alloleval pildil nummerdatud samme.
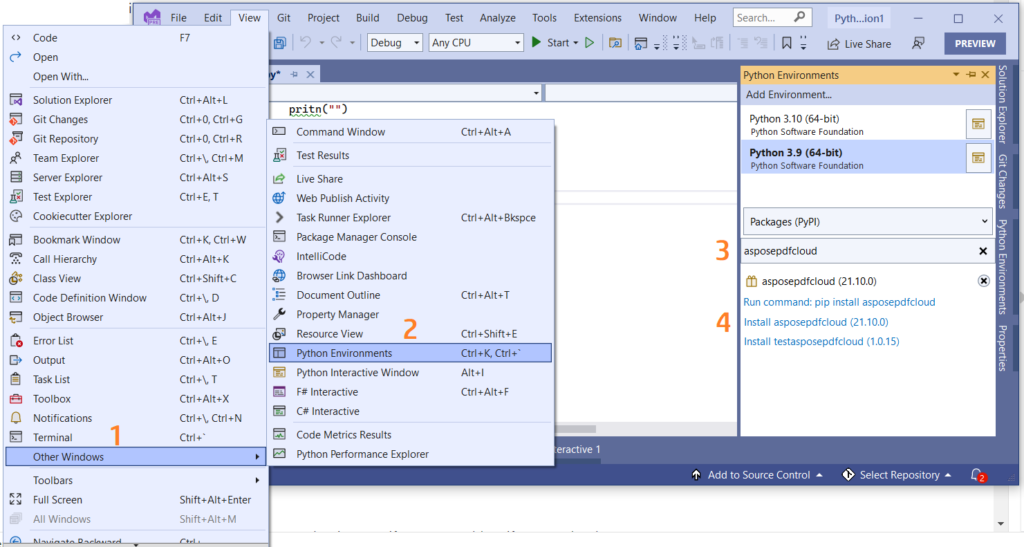
Pilt 1: Aspose.PDF Cloud SDK Pythoni paketi jaoks.
Aspose.Cloud Dashboard
Kuna meie API-d on juurdepääsetavad ainult volitatud isikutele, on järgmiseks sammuks konto loomine saidil Aspose.Cloud dashboard. Kui teil on GitHubi või Google’i konto, registreeruge või klõpsake nupul Loo uus konto ja sisestage nõutav teave. Nüüd logige mandaatide abil armatuurlauale sisse ja laiendage armatuurlaual jaotist Rakendused ja kerige alla jaotise Kliendi volikirjad, et näha kliendi ID ja kliendi saladuse üksikasju.
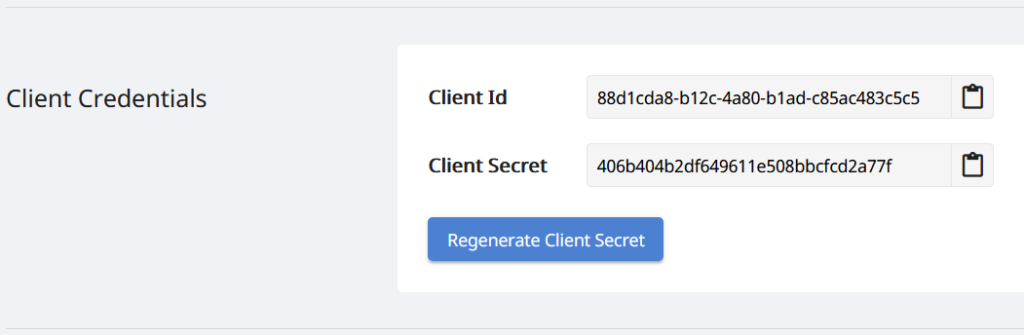
Pilt 2: – kliendi mandaadid Aspose.Cloudi armatuurlaual.
Pilt PDF-ist Pythonis otsitavaks PDF-iks
Skannitud PDF-dokumendi OCR-toimingu tegemiseks järgige alltoodud samme ja seejärel salvestage see otsitavaks (muutke pdf-fail otsitavaks). Need sammud aitavad meil Pythoni abil arendada tasuta võrgus OCR-i.
- Esiteks peame looma ApiClient klassi eksemplari, pakkudes samas argumentidena Client ID Client Secret
- Teiseks looge PdfApi klassi eksemplar, mis võtab sisendargumendina ApiClient objekti
- Nüüd kutsuge PdfApi klassi meetod putsearchabledocument(..), mis võtab sisestatud PDF-i nime ja valikulise parameetri, mis näitab OCR-mootori keelt.
def ocrPDF():
try:
#Client credentials
client_secret = "406b404b2df649611e508bbcfcd2a77f"
client_id = "88d1cda8-b12c-4a80-b1ad-c85ac483c5c5"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# luua PdfApi eksemplar, edastades argumendina PdfApiClient
pdf_api = PdfApi(pdf_api_client)
#input PDF file name
input_file = 'image-based-pdf-sample.pdf'
# helistage API-le, et teha OCR-operatsioon ja salvestada väljund pilvesalvestusse
response = pdf_api.put_searchable_document(name=input_file,lang='eng')
# prindi sõnum konsoolis (valikuline)
print('Image PDF successfully converted to Text PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
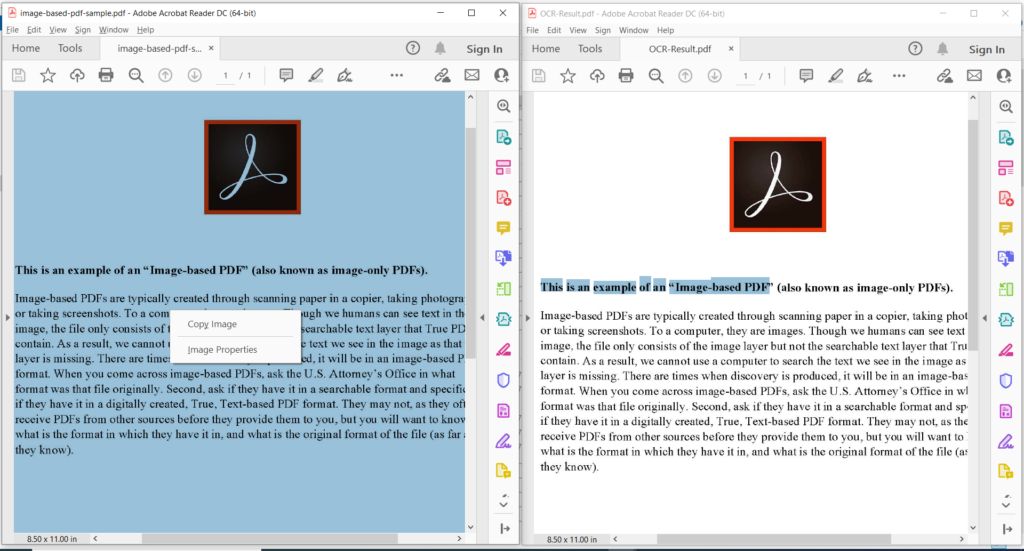
Pilt 3: PDF-OCR-i töö eelvaade.
Ülaltoodud pildil tähistab vasakpoolne osa sisendskannitud PDF-faili ja parempoolne osa näitab saadud tekstipõhise PDF-i eelvaadet. Ülaltoodud näites kasutatud näidisfaile saab alla laadida saidilt image-based-pdf-sample.pdf ja OCR-Result.pdf.
OCR võrgus, kasutades cURL-i käske
REST API-dele pääseb juurde ka cURL-i käskude kaudu ja kuna meie pilve API-d põhinevad REST-arhitektuuril, saame cURL-i käsku kasutada ka PDF-i OCR-i veebis teostamiseks. Enne teisendustoiminguga jätkamist peame siiski looma JSON-i veebimärgi (JWT), mis põhineb teie individuaalsetel kliendimandaatidel, mis on määratud Aspose.Cloud armatuurlaual. See on kohustuslik, kuna meie API-dele on juurdepääs ainult registreeritud kasutajatele. JWT-märgi genereerimiseks täitke järgmine käsk.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=88d1cda8-b12c-4a80-b1ad-c85ac483c5c5&client_secret=406b404b2df649611e508bbcfcd2a77f" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Kui meil on JWT-märk, täitke OCR-toimingu tegemiseks järgmine käsk ja salvestage väljund samasse pilvmällu.
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/image-based-pdf-sample.pdf/ocr" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Järeldus
Selles artiklis oleme arutanud samme, kuidas muuta Pythoni koodilõigu abil PDF-pildist otsitav PDF. Oleme uurinud ka üksikasju selle kohta, kuidas OCR-i veebis cURL-käskude abil teostada. Kuna meie pilve-SDK-d on välja töötatud MIT-litsentsi alusel, võite kogu koodilõigu saidilt GitHub alla laadida ja seda vastavalt oma vajadustele värskendada. Soovitame tungivalt uurida arendaja juhendit, et saada lisateavet teiste põnevate funktsioonide kohta, mida praegu Cloud API pakub.
Kui teil on seotud küsimusi või kui teil tekib meie API-de kasutamisel probleeme, võtke meiega ühendust tasuta klienditoe foorumi kaudu.
seotud artiklid
Soovitame selle kohta lisateabe saamiseks läbi lugeda ka järgmised artiklid