
माहिती आणि डेटा शेअरिंगसाठी PDF फाइल्स इंटरनेटवर मोठ्या प्रमाणावर वापरल्या जातात. ते खूप लोकप्रिय आहेत कारण ते कोणत्याही प्लॅटफॉर्मवर पाहताना कागदपत्रांची निष्ठा राखतात. तथापि, स्त्रोतावर आमचे नियंत्रण नाही आणि काही फायली स्कॅन केलेल्या स्वरूपात सामायिक केल्या आहेत. काहीवेळा तुम्ही PDF म्हणून प्रतिमा कॅप्चर करता आणि नंतर तुम्हाला फाइलमधून सामग्री काढावी लागते. त्यामुळे OCR ऑपरेशन करणे आणि मजकूर काढणे हा एक व्यवहार्य उपाय आहे. तथापि, ओसीआर ऑपरेशननंतर, जर तुम्हाला फाइल जतन करायची असेल, तर पीडीएफ फॉरमॅटमध्ये रूपांतर करणे हा एक व्यवहार्य उपाय आहे. या लेखात, आम्ही पायथन वापरून स्कॅन केलेल्या पीडीएफला टेक्स्ट पीडीएफमध्ये कसे रूपांतरित करावे यावरील चरणांवर चर्चा करणार आहोत.
OCR PDF API
[Aspose.PDF Cloud SDK for Python2 हे [Aspose.PDF क्लाउड3 भोवती एक आवरण आहे. हे तुम्हाला पायथन ऍप्लिकेशनमध्ये सर्व पीडीएफ फाइल प्रोसेसिंग क्षमता पूर्ण करण्यास सक्षम करते. Adobe Acrobat किंवा इतर कोणत्याही अनुप्रयोगाशिवाय PDF फाइल्स हाताळा. त्यामुळे SDK वापरण्यासाठी, पहिली पायरी म्हणजे त्याची स्थापना, आणि ते PIP आणि GitHub रेपॉजिटरीवरून डाउनलोड करण्यासाठी उपलब्ध आहे. आता सिस्टमवर SDK ची नवीनतम आवृत्ती स्थापित करण्यासाठी टर्मिनल/कमांड प्रॉम्प्टवर खालील कमांड कार्यान्वित करा.
pip install asposepdfcloud
एमएस व्हिज्युअल स्टुडिओ
व्हिज्युअल स्टुडिओ प्रोजेक्टमध्ये तुम्ही तुमच्या पायथन प्रोजेक्टमध्ये थेट संदर्भ जोडू शकता. कृपया Python पर्यावरण विंडो अंतर्गत पॅकेज म्हणून asposepdfcloud शोधा. प्रतिष्ठापन प्रक्रिया पूर्ण करण्यासाठी कृपया खालील प्रतिमेमध्ये क्रमांक दिलेल्या चरणांचे अनुसरण करा.
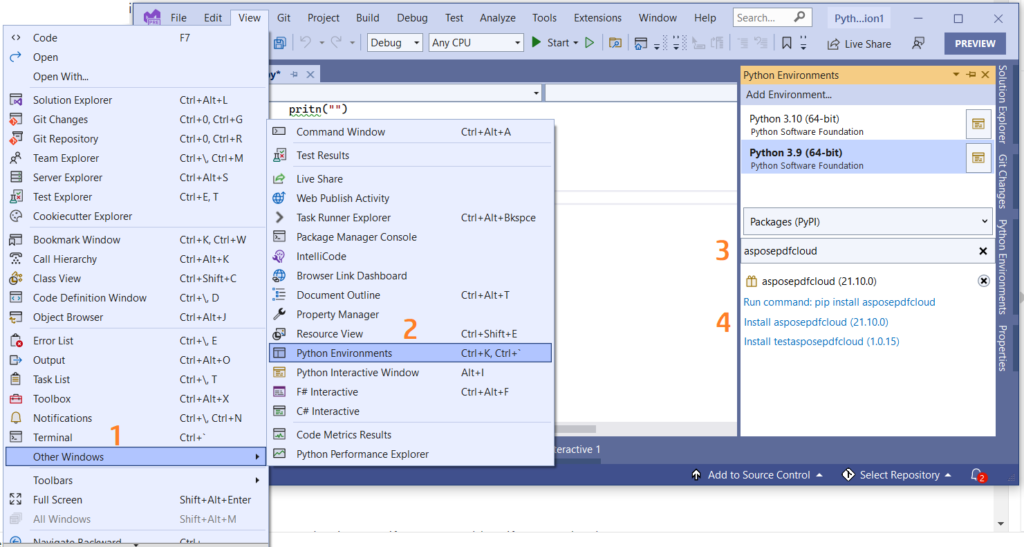
प्रतिमा 1:- Python पॅकेजसाठी Aspose.PDF क्लाउड SDK.
Aspose.Cloud डॅशबोर्ड
आमचे API केवळ अधिकृत व्यक्तींसाठीच प्रवेश करण्यायोग्य असल्याने, पुढील पायरी म्हणजे [Aspose.Cloud डॅशबोर्ड6 वर खाते तयार करणे. तुमच्याकडे GitHub किंवा Google खाते असल्यास, फक्त साइन अप करा किंवा, नवीन खाते तयार करा बटणावर क्लिक करा आणि आवश्यक माहिती प्रदान करा. आता क्रेडेन्शियल्स वापरून डॅशबोर्डवर लॉगिन करा आणि डॅशबोर्डवरून अॅप्लिकेशन्स विभाग विस्तृत करा आणि क्लायंट आयडी आणि क्लायंट गुप्त तपशील पाहण्यासाठी क्लायंट क्रेडेन्शियल्स विभागाकडे खाली स्क्रोल करा.
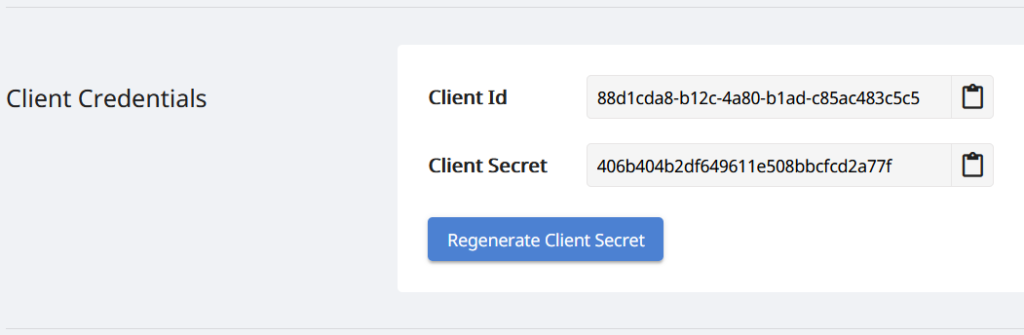
इमेज २:- Aspose.Cloud डॅशबोर्डवरील क्लायंट क्रेडेन्शियल.
Python मध्ये शोधण्यायोग्य PDF ते प्रतिमा PDF
कृपया स्कॅन केलेल्या PDF दस्तऐवजावर OCR ऑपरेशन करण्यासाठी खालील चरणांचे अनुसरण करा आणि नंतर ते शोधण्यायोग्य म्हणून जतन करा (पीडीएफ शोधण्यायोग्य बनवा). या पायऱ्या पायथन वापरून मोफत ऑनलाइन OCR विकसित करण्यात आम्हाला मदत करतात.
- प्रथम, वितर्क म्हणून क्लायंट आयडी क्लायंट सीक्रेट प्रदान करताना आम्हाला ApiClient क्लासचे उदाहरण तयार करावे लागेल
- दुसरे म्हणजे, PdfApi क्लासचे एक उदाहरण तयार करा जे ApiClient ऑब्जेक्ट इनपुट वितर्क म्हणून घेते
- आता PdfApi क्लासची putsearchabledocument(..) पद्धत कॉल करा जी इनपुट पीडीएफ नाव आणि OCR इंजिनची भाषा दर्शविणारा पर्यायी पॅरामीटर घेते.
def ocrPDF():
try:
#Client credentials
client_secret = "406b404b2df649611e508bbcfcd2a77f"
client_id = "88d1cda8-b12c-4a80-b1ad-c85ac483c5c5"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# PdfApiClient वितर्क म्हणून पास करताना PdfApi उदाहरण तयार करा
pdf_api = PdfApi(pdf_api_client)
#input PDF file name
input_file = 'image-based-pdf-sample.pdf'
# OCR ऑपरेशन करण्यासाठी API ला कॉल करा आणि क्लाउड स्टोरेजमध्ये आउटपुट जतन करा
response = pdf_api.put_searchable_document(name=input_file,lang='eng')
# कन्सोलमध्ये संदेश प्रिंट करा (पर्यायी)
print('Image PDF successfully converted to Text PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
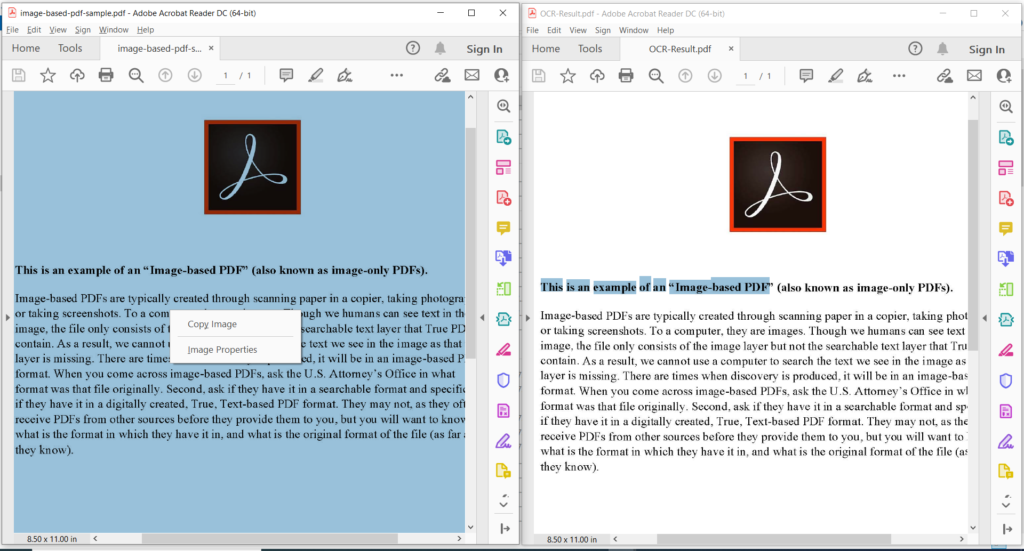
प्रतिमा ३:- PDF OCR ऑपरेशनचे पूर्वावलोकन.
वरील प्रतिमेमध्ये, डावा भाग इनपुट स्कॅन केलेली PDF फाइल दर्शवितो आणि उजव्या बाजूचा भाग परिणामी मजकूर-आधारित PDF चे पूर्वावलोकन दर्शवितो. वरील उदाहरणामध्ये वापरलेल्या नमुना फायली image-based-pdf-sample.pdf आणि OCR-Result.pdf वरून डाउनलोड केल्या जाऊ शकतात.
CURL कमांड वापरून OCR ऑनलाइन
REST API मध्ये देखील cURL आदेशांद्वारे प्रवेश केला जाऊ शकतो आणि आमचे क्लाउड API REST आर्किटेक्चरवर आधारित असल्यामुळे आम्ही PDF OCR ऑनलाइन करण्यासाठी cURL कमांड देखील वापरू शकतो. तथापि, रूपांतरण ऑपरेशनला पुढे जाण्यापूर्वी, Aspose.Cloud डॅशबोर्डवर निर्दिष्ट केलेल्या तुमच्या वैयक्तिक क्लायंट क्रेडेन्शियल्सवर आधारित आम्हाला JSON वेब टोकन (JWT) तयार करणे आवश्यक आहे. हे अनिवार्य आहे कारण आमचे API फक्त नोंदणीकृत वापरकर्त्यांसाठी प्रवेशयोग्य आहेत. कृपया JWT टोकन जनरेट करण्यासाठी खालील कमांड कार्यान्वित करा.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=88d1cda8-b12c-4a80-b1ad-c85ac483c5c5&client_secret=406b404b2df649611e508bbcfcd2a77f" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
आमच्याकडे JWT टोकन मिळाल्यावर, कृपया OCR ऑपरेशन करण्यासाठी खालील कमांड कार्यान्वित करा आणि त्याच क्लाउड स्टोरेजमध्ये आउटपुट जतन करा.
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/image-based-pdf-sample.pdf/ocr" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
निष्कर्ष
या लेखात, आम्ही पायथन कोड स्निपेट वापरून पीडीएफ ते शोधण्यायोग्य पीडीएफ प्रतिमा करण्याच्या चरणांवर चर्चा केली आहे. सीआरएल कमांड वापरून ओसीआर ऑनलाइन कसे चालवायचे याचे तपशील देखील आम्ही शोधले आहेत. आमची क्लाउड SDKs MIT परवान्याअंतर्गत विकसित केलेली असल्यामुळे, तुम्ही GitHub वरून संपूर्ण कोड स्निपेट डाउनलोड करू शकता आणि तुमच्या गरजेनुसार अपडेट करू शकता. सध्या क्लाउड API द्वारे ऑफर केल्या जात असलेल्या इतर रोमांचक वैशिष्ट्यांबद्दल अधिक जाणून घेण्यासाठी आम्ही तुम्हाला [डेव्हलपर मार्गदर्शक] एक्सप्लोर करण्याची जोरदार शिफारस करतो.
आमची API वापरताना तुम्हाला काही संबंधित प्रश्न असल्यास किंवा तुम्हाला काही समस्या आल्यास, कृपया [विनामूल्य ग्राहक समर्थन मंच[१३] द्वारे आमच्याशी मोकळ्या मनाने संपर्क साधा.
संबंधित लेख
याबद्दल अधिक जाणून घेण्यासाठी आम्ही खालील लेखांमधून जाण्याचा सल्ला देखील देतो