
Les fichiers PDF sont largement utilisés sur Internet pour le partage d’informations et de données. Ils sont très populaires car ils maintiennent la fidélité des documents lors de la visualisation sur n’importe quelle plate-forme. Cependant, nous n’avons aucun contrôle sur la source et certains fichiers sont partagés au format numérisé. Parfois, vous capturez une image au format PDF et vous devez ensuite extraire le contenu du fichier. Une solution viable consiste donc à effectuer une opération OCR et à extraire le texte. Cependant, après l’opération OCR, si vous avez besoin de conserver le fichier, la conversion au format PDF est une solution viable. Dans cet article, nous allons discuter des étapes à suivre pour convertir un PDF numérisé en PDF texte à l’aide de Python.
API OCR PDF
Aspose.PDF Cloud SDK for Python est un wrapper autour de Aspose.PDF Cloud. Il vous permet d’effectuer toutes les fonctionnalités de traitement de fichiers PDF dans l’application Python. Manipulez des fichiers PDF sans Adobe Acrobat ou toute autre application. Donc, pour utiliser le SDK, la première étape est son installation, et il est disponible en téléchargement sur les référentiels PIP et GitHub. Exécutez maintenant la commande suivante sur le terminal/invite de commande pour installer la dernière version du SDK sur le système.
pip install asposepdfcloud
Microsoft Visual Studio
Vous pouvez également ajouter directement la référence dans votre projet Python dans le projet Visual Studio. Veuillez rechercher asposepdfcloud en tant que package dans la fenêtre de l’environnement Python. Veuillez suivre les étapes numérotées dans l’image ci-dessous pour terminer le processus d’installation.
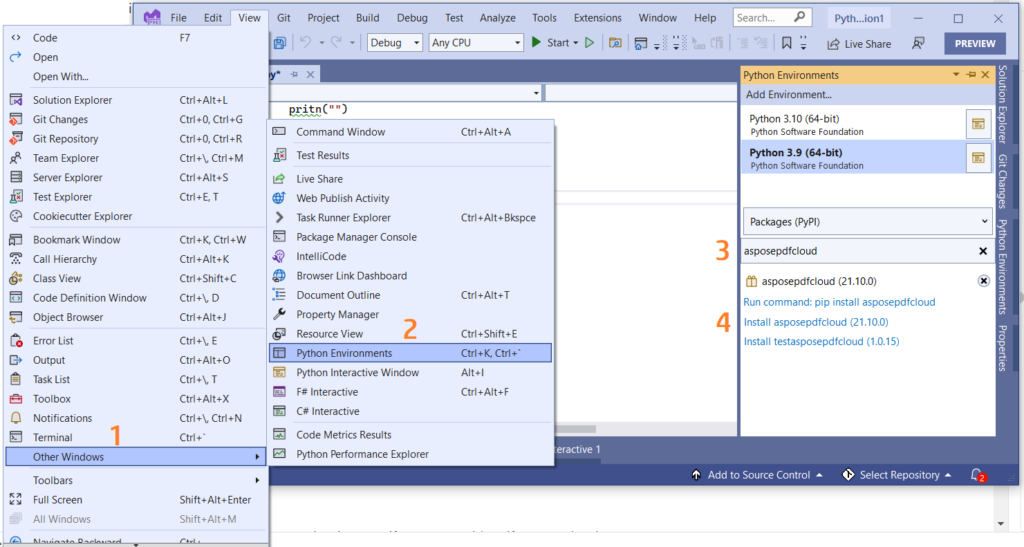
Image 1 :- Aspose.PDF Cloud SDK pour le package Python.
Tableau de bord Aspose.Cloud
Étant donné que nos API ne sont accessibles qu’aux personnes autorisées, la prochaine étape consiste donc à créer un compte sur tableau de bord Aspose.Cloud. Si vous avez un compte GitHub ou Google, inscrivez-vous simplement ou cliquez sur le bouton Créer un nouveau compte et fournissez les informations requises. Connectez-vous maintenant au tableau de bord à l’aide des informations d’identification et développez la section Applications du tableau de bord et faites défiler vers le bas jusqu’à la section Informations d’identification du client pour voir les détails de l’ID client et du secret client.
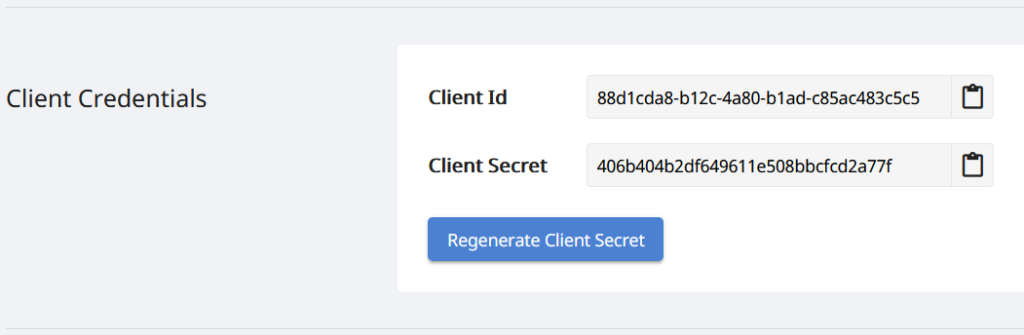
Image 2 :- Identifiants client sur le tableau de bord Aspose.Cloud.
PDF image en PDF consultable en Python
Veuillez suivre les étapes indiquées ci-dessous pour effectuer une opération OCR sur un document PDF numérisé, puis l’enregistrer en tant que fichier interrogeable (rendre le pdf interrogeable). Ces étapes nous aident à développer une OCR en ligne gratuite en utilisant Python.
- Tout d’abord, nous devons créer une instance de la classe ApiClient tout en fournissant Client ID Client Secret comme arguments
- Deuxièmement, créez une instance de la classe PdfApi qui prend l’objet ApiClient comme argument d’entrée
- Appelez maintenant la méthode putsearchabledocument(..) de la classe PdfApi qui prend le nom du PDF en entrée et un paramètre facultatif indiquant la langue du moteur OCR.
def ocrPDF():
try:
#Client credentials
client_secret = "406b404b2df649611e508bbcfcd2a77f"
client_id = "88d1cda8-b12c-4a80-b1ad-c85ac483c5c5"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# créer une instance PdfApi en passant PdfApiClient comme argument
pdf_api = PdfApi(pdf_api_client)
#input PDF file name
input_file = 'image-based-pdf-sample.pdf'
# appelez l'API pour effectuer l'opération OCR et enregistrez la sortie dans le stockage en nuage
response = pdf_api.put_searchable_document(name=input_file,lang='eng')
# imprimer le message dans la console (facultatif)
print('Image PDF successfully converted to Text PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
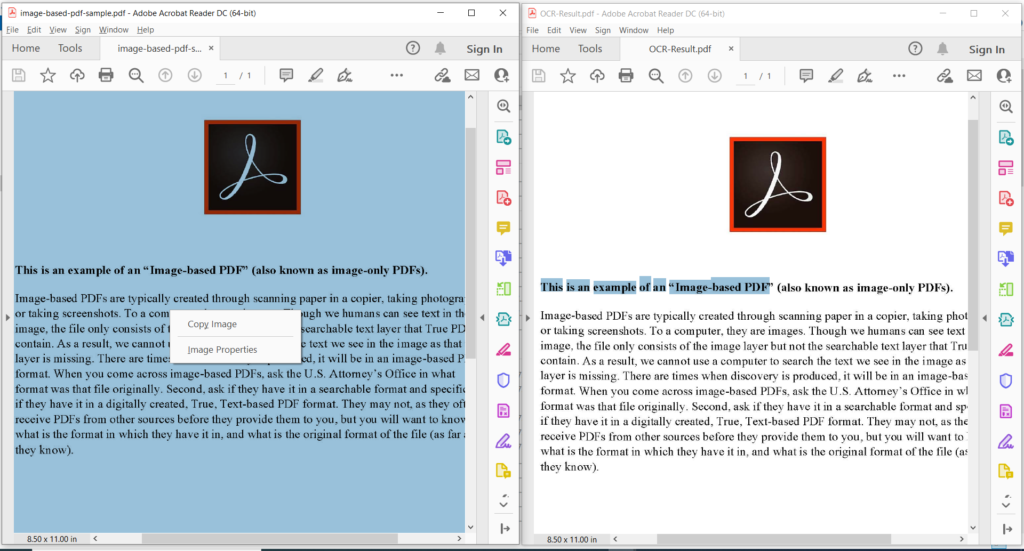
Image 3:- Aperçu de l’opération OCR PDF.
Dans l’image ci-dessus, la partie de gauche indique le fichier PDF numérisé d’entrée et la partie de droite montre un aperçu du PDF textuel résultant. Les exemples de fichiers utilisés dans l’exemple ci-dessus peuvent être téléchargés depuis image-based-pdf-sample.pdf et OCR-Result.pdf.
OCR en ligne à l’aide des commandes cURL
Les API REST sont également accessibles via les commandes cURL et comme nos API Cloud sont basées sur l’architecture REST, nous pouvons également utiliser la commande cURL pour effectuer l’OCR PDF en ligne. Cependant, avant de procéder à l’opération de conversion, nous devons générer un jeton Web JSON (JWT) basé sur vos informations d’identification client individuelles spécifiées sur le tableau de bord Aspose.Cloud. Il est obligatoire car nos API ne sont accessibles qu’aux utilisateurs enregistrés. Veuillez exécuter la commande suivante pour générer le jeton JWT.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=88d1cda8-b12c-4a80-b1ad-c85ac483c5c5&client_secret=406b404b2df649611e508bbcfcd2a77f" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Une fois que nous avons le jeton JWT, veuillez exécuter la commande suivante pour effectuer l’opération OCR et enregistrer la sortie dans le même stockage cloud.
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/image-based-pdf-sample.pdf/ocr" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Conclusion
Dans cet article, nous avons discuté des étapes pour convertir un PDF image en PDF consultable à l’aide d’un extrait de code Python. Nous avons également exploré les détails sur la façon d’effectuer l’OCR en ligne à l’aide des commandes cURL. Comme nos SDK cloud sont développés sous licence MIT, vous pouvez donc télécharger l’extrait de code complet depuis GitHub et le mettre à jour selon vos besoins. Nous vous recommandons vivement d’explorer le Guide du développeur pour en savoir plus sur les autres fonctionnalités intéressantes actuellement proposées par l’API Cloud.
Si vous avez des questions connexes ou si vous rencontrez des problèmes lors de l’utilisation de nos API, n’hésitez pas à nous contacter via le forum d’assistance client gratuit.
Articles Liés
Nous vous suggérons également de parcourir les articles suivants pour en savoir plus sur