
Súbory PDF sa široko používajú na internete na zdieľanie informácií a údajov. Sú pomerne obľúbené, pretože zachovávajú vernosť dokumentov pri prezeraní na akejkoľvek platforme. Nemáme však kontrolu nad zdrojom a niektoré súbory sú zdieľané v naskenovanom formáte. Niekedy zachytíte obrázok ako PDF a neskôr potrebujete extrahovať obsah zo súboru. Takže životaschopným riešením je vykonať operáciu OCR a extrahovať text. Ak však po operácii OCR potrebujete súbor zachovať, konverzia do formátu PDF je životaschopným riešením. V tomto článku budeme diskutovať o krokoch, ako previesť naskenované PDF na textové PDF pomocou Pythonu.
OCR PDF API
Aspose.PDF Cloud SDK pre Python je obal okolo Aspose.PDF Cloud. Umožňuje vám vykonávať všetky možnosti spracovania súborov PDF v rámci aplikácie Python. Manipulujte so súbormi PDF bez aplikácie Adobe Acrobat alebo akejkoľvek inej aplikácie. Takže ak chcete používať SDK, prvým krokom je jej inštalácia a je k dispozícii na stiahnutie cez úložisko PIP a GitHub. Teraz spustite nasledujúci príkaz na terminálovom/príkazovom riadku a nainštalujte najnovšiu verziu SDK do systému.
pip install asposepdfcloud
MS Visual Studio
Môžete tiež priamo pridať odkaz do svojho projektu Python v rámci projektu Visual Studio. Vyhľadajte asposepdfcloud ako balík v okne prostredia Pythonu. Na dokončenie procesu inštalácie postupujte podľa krokov očíslovaných na obrázku nižšie.
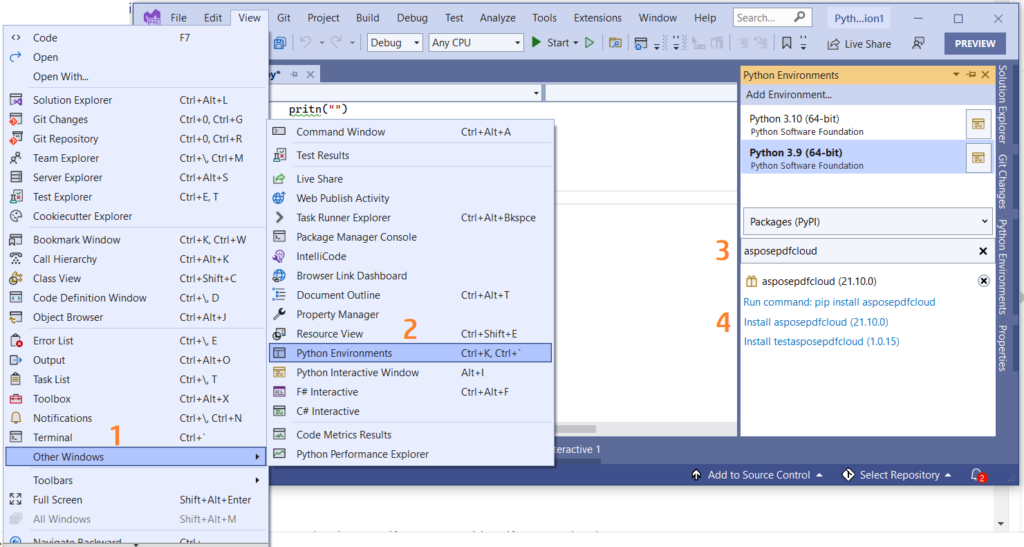
Obrázok 1:- Aspose.PDF Cloud SDK pre balík Python.
Aspose.Cloud Dashboard
Keďže naše API sú prístupné iba oprávneným osobám, ďalším krokom je vytvorenie účtu na Aspose.Cloud dashboard. Ak máte účet GitHub alebo Google, jednoducho sa zaregistrujte alebo kliknite na tlačidlo Vytvoriť nový účet a zadajte požadované informácie. Teraz sa prihláste do ovládacieho panela pomocou poverení a rozbaľte sekciu Aplikácie z ovládacieho panela a prejdite nadol smerom k sekcii Poverenia klienta, kde nájdete podrobnosti o ID klienta a tajomstve klienta.
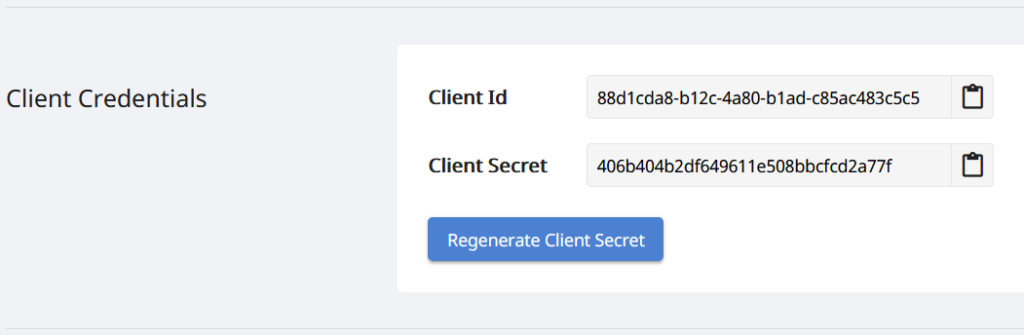
Obrázok 2: Poverenia klienta na ovládacom paneli Aspose.Cloud.
Obrázok PDF do PDF s možnosťou vyhľadávania v Pythone
Ak chcete vykonať operáciu OCR na naskenovanom dokumente PDF a potom ho uložiť ako prehľadávateľný (umožnite prehľadávať súbor PDF), postupujte podľa krokov uvedených nižšie. Tieto kroky nám pomáhajú pri vývoji bezplatného online OCR pomocou Pythonu.
- Najprv musíme vytvoriť inštanciu triedy ApiClient a zároveň poskytnúť ako argumenty Client ID Client Secret
- Po druhé, vytvorte inštanciu triedy PdfApi, ktorá berie objekt ApiClient ako vstupný argument
- Teraz zavolajte metódu putsearchabledocument(..) triedy PdfApi, ktorá preberá vstupný názov PDF a voliteľný parameter označujúci jazyk OCR nástroja.
def ocrPDF():
try:
#Client credentials
client_secret = "406b404b2df649611e508bbcfcd2a77f"
client_id = "88d1cda8-b12c-4a80-b1ad-c85ac483c5c5"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# vytvoriť inštanciu PdfApi a zároveň odovzdať PdfApiClient ako argument
pdf_api = PdfApi(pdf_api_client)
#input PDF file name
input_file = 'image-based-pdf-sample.pdf'
# zavolajte API, aby ste vykonali operáciu OCR a uložili výstup do cloudového úložiska
response = pdf_api.put_searchable_document(name=input_file,lang='eng')
# vytlačiť správu v konzole (voliteľné)
print('Image PDF successfully converted to Text PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
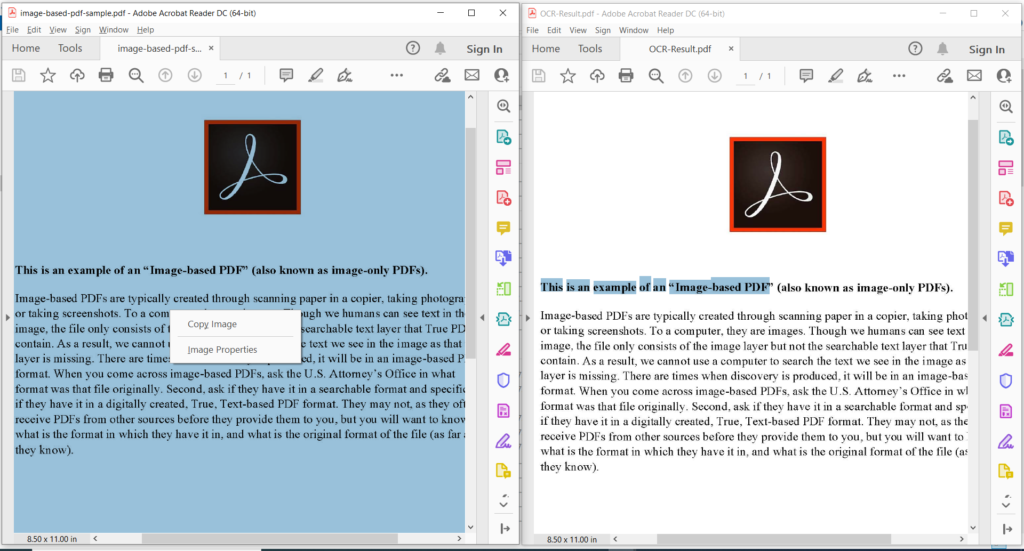
Obrázok 3:- Ukážka operácie PDF OCR.
Na obrázku vyššie ľavá časť označuje vstupný naskenovaný súbor PDF a časť na pravej strane zobrazuje náhľad výsledného textového PDF. Vzorové súbory použité vo vyššie uvedenom príklade si môžete stiahnuť z image-based-pdf-sample.pdf a OCR-Result.pdf.
OCR online pomocou príkazov cURL
K rozhraniam REST API je možné pristupovať aj prostredníctvom príkazov cURL a keďže naše cloudové API sú založené na architektúre REST, príkaz cURL môžeme použiť aj na online OCR PDF. Pred pokračovaním v operácii konverzie však musíme vygenerovať webový token JSON (JWT) na základe vašich individuálnych prihlasovacích údajov klienta zadaných cez informačný panel Aspose.Cloud. Je to povinné, pretože naše API sú prístupné iba registrovaným používateľom. Ak chcete vygenerovať token JWT, vykonajte nasledujúci príkaz.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=88d1cda8-b12c-4a80-b1ad-c85ac483c5c5&client_secret=406b404b2df649611e508bbcfcd2a77f" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Keď máme token JWT, vykonajte nasledujúci príkaz na vykonanie operácie OCR a uloženie výstupu do rovnakého cloudového úložiska.
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/image-based-pdf-sample.pdf/ocr" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Záver
V tomto článku sme diskutovali o krokoch na presun obrázkového PDF do prehľadávateľného PDF pomocou útržku kódu Python. Preskúmali sme aj podrobnosti o tom, ako vykonávať OCR Online pomocou príkazov cURL. Keďže sú naše cloudové súpravy SDK vyvinuté na základe licencie MIT, môžete si stiahnuť celý útržok kódu z GitHub a aktualizovať ho podľa svojich požiadaviek. Dôrazne vám odporúčame preskúmať Príručku pre vývojárov a dozvedieť sa viac o ďalších zaujímavých funkciách, ktoré v súčasnosti ponúka Cloud API.
V prípade, že máte akékoľvek súvisiace otázky alebo narazíte na problémy pri používaní našich rozhraní API, neváhajte nás kontaktovať prostredníctvom bezplatného fóra zákazníckej podpory.
Súvisiace články
Odporúčame vám tiež prečítať si nasledujúce články, aby ste sa o nich dozvedeli viac