
Pliki PDF są powszechnie używane w Internecie do udostępniania informacji i danych. Są dość popularne, ponieważ zachowują wierność dokumentów podczas przeglądania na dowolnej platformie. Nie mamy jednak kontroli nad źródłem i niektóre pliki udostępniamy w zeskanowanym formacie. Czasami przechwytujesz obraz jako plik PDF, a później musisz wyodrębnić zawartość z pliku. Tak więc realnym rozwiązaniem jest wykonanie operacji OCR i wyodrębnienie tekstu. Jednak po operacji OCR, jeśli chcesz zachować plik, konwersja do formatu PDF jest realnym rozwiązaniem. W tym artykule omówimy kroki konwersji zeskanowanego pliku PDF na tekstowy PDF za pomocą Pythona.
OCR PDF API
Aspose.PDF Cloud SDK for Python to opakowanie na Aspose.PDF Cloud. Umożliwia wykonywanie wszystkich funkcji przetwarzania plików PDF w aplikacji Python. Manipuluj plikami PDF bez programu Adobe Acrobat lub jakiejkolwiek innej aplikacji. Tak więc, aby korzystać z pakietu SDK, pierwszym krokiem jest jego instalacja i jest on dostępny do pobrania w repozytorium PIP i GitHub. Teraz wykonaj następujące polecenie w terminalu / wierszu polecenia, aby zainstalować najnowszą wersję SDK w systemie.
pip install asposepdfcloud
MS VisualStudio
Możesz także bezpośrednio dodać odwołanie do projektu w języku Python w ramach projektu programu Visual Studio. Proszę wyszukać asposepdfcloud jako pakiet w oknie środowiska Pythona. Wykonaj kroki ponumerowane na poniższym obrazku, aby zakończyć proces instalacji.

Obraz 1: — pakiet Aspose.PDF Cloud SDK dla języka Python.
Pulpit nawigacyjny Aspose.Cloud
Ponieważ nasze API są dostępne tylko dla upoważnionych osób, kolejnym krokiem jest utworzenie konta na desce rozdzielczej Aspose.Cloud. Jeśli masz konto GitHub lub Google, po prostu Zarejestruj się lub kliknij przycisk Utwórz nowe konto i podaj wymagane informacje. Teraz zaloguj się do pulpitu nawigacyjnego przy użyciu poświadczeń i rozwiń sekcję Aplikacje z pulpitu nawigacyjnego i przewiń w dół do sekcji Poświadczenia klienta, aby zobaczyć szczegóły dotyczące identyfikatora klienta i klucza tajnego klienta.
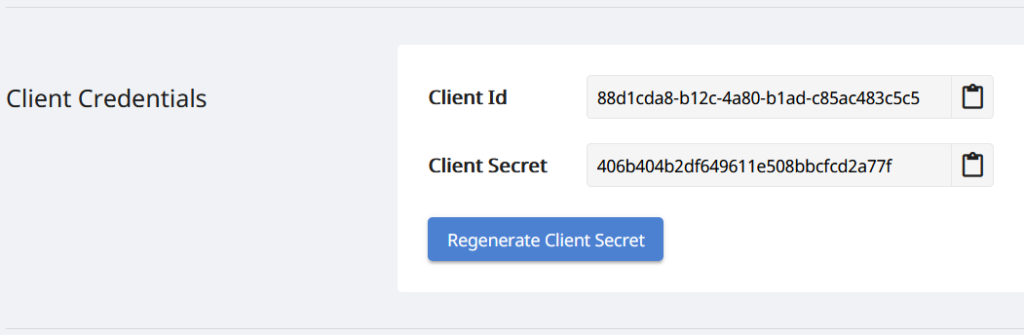
Obraz 2: - Poświadczenia klienta na pulpicie nawigacyjnym Aspose.Cloud.
Obraz PDF do przeszukiwalnego pliku PDF w Pythonie
Wykonaj czynności podane poniżej, aby wykonać operację OCR na zeskanowanym dokumencie PDF, a następnie zapisać go jako możliwy do przeszukiwania (umożliwienie przeszukiwania pdf). Te kroki pomogą nam opracować bezpłatny OCR online przy użyciu Pythona.
- Najpierw musimy utworzyć instancję klasy ApiClient, podając jako argumenty Client ID Client Secret
- Po drugie, utwórz instancję klasy PdfApi, która przyjmuje obiekt ApiClient jako argument wejściowy
- Teraz wywołaj metodę putsearchabledocument(..) klasy PdfApi, która pobiera nazwę wejściowego pliku PDF oraz opcjonalny parametr wskazujący język silnika OCR.
def ocrPDF():
try:
#Client credentials
client_secret = "406b404b2df649611e508bbcfcd2a77f"
client_id = "88d1cda8-b12c-4a80-b1ad-c85ac483c5c5"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# utwórz instancję PdfApi, przekazując PdfApiClient jako argument
pdf_api = PdfApi(pdf_api_client)
#input PDF file name
input_file = 'image-based-pdf-sample.pdf'
# wywołaj API, aby wykonać operację OCR i zapisać dane wyjściowe w chmurze
response = pdf_api.put_searchable_document(name=input_file,lang='eng')
# wydrukuj wiadomość w konsoli (opcjonalnie)
print('Image PDF successfully converted to Text PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
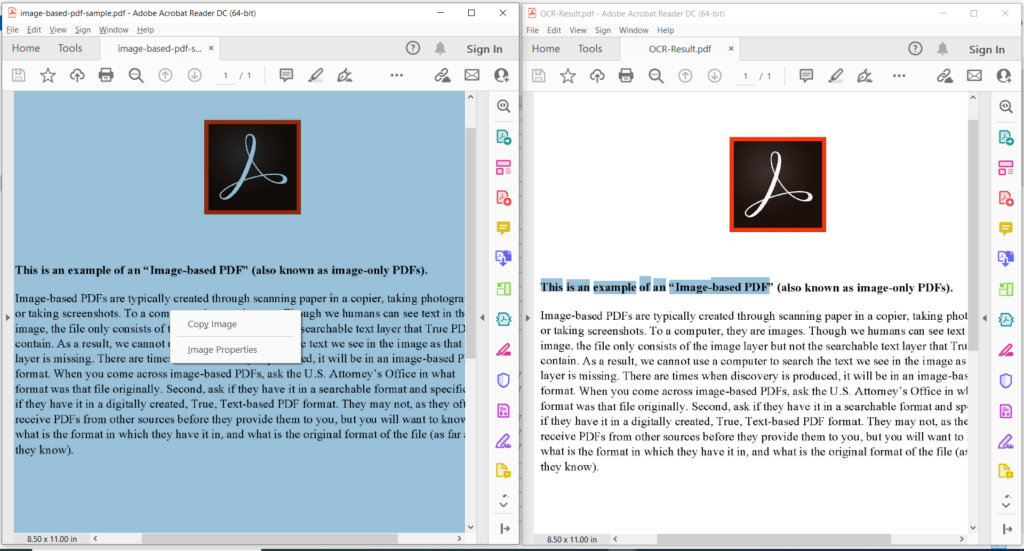
Obraz 3: - Podgląd operacji PDF OCR.
Na powyższym obrazku lewa część oznacza wejściowy zeskanowany plik PDF, a część po prawej stronie pokazuje podgląd wynikowego tekstowego pliku PDF. Przykładowe pliki użyte w powyższym przykładzie można pobrać z image-based-pdf-sample.pdf i OCR-Result.pdf.
OCR online za pomocą poleceń cURL
Dostęp do interfejsów API REST można również uzyskać za pomocą poleceń cURL, a ponieważ nasze interfejsy API w chmurze są oparte na architekturze REST, możemy również użyć polecenia cURL do wykonywania OCR PDF online. Jednak przed przystąpieniem do operacji konwersji musimy wygenerować JSON Web Token (JWT) w oparciu o indywidualne poświadczenia klienta określone na pulpicie nawigacyjnym Aspose.Cloud. Jest to obowiązkowe, ponieważ nasze interfejsy API są dostępne tylko dla zarejestrowanych użytkowników. Wykonaj następujące polecenie, aby wygenerować token JWT.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=88d1cda8-b12c-4a80-b1ad-c85ac483c5c5&client_secret=406b404b2df649611e508bbcfcd2a77f" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Gdy mamy token JWT, wykonaj następujące polecenie, aby wykonać operację OCR i zapisać dane wyjściowe w tym samym magazynie w chmurze.
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/image-based-pdf-sample.pdf/ocr" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Wniosek
W tym artykule omówiliśmy kroki konwersji obrazu PDF do pliku PDF z możliwością wyszukiwania przy użyciu fragmentu kodu Pythona. Zbadaliśmy również szczegóły dotyczące wykonywania OCR Online za pomocą poleceń cURL. Ponieważ nasze pakiety SDK w chmurze są opracowywane na licencji MIT, możesz pobrać cały fragment kodu z GitHub i zaktualizować go zgodnie ze swoimi wymaganiami. Zdecydowanie zalecamy zapoznanie się z Przewodnikiem dla programistów, aby dowiedzieć się więcej o innych ekscytujących funkcjach oferowanych obecnie przez Cloud API.
Jeśli masz jakiekolwiek związane z tym pytania lub napotkasz jakiekolwiek problemy podczas korzystania z naszych interfejsów API, skontaktuj się z nami za pośrednictwem bezpłatnego forum obsługi klienta.
Powiązane artykuły
Sugerujemy również przejrzenie poniższych artykułów, aby dowiedzieć się więcej