
PDF datoteke naširoko se koriste putem interneta za dijeljenje informacija i podataka. Prilično su popularni jer održavaju vjernost dokumenata pri gledanju na bilo kojoj platformi. Međutim, nemamo kontrolu nad izvorom i neke se datoteke dijele u skeniranom formatu. Ponekad snimite sliku kao PDF i kasnije trebate izdvojiti sadržaj iz datoteke. Stoga je održivo rješenje izvršiti OCR operaciju i izdvojiti tekst. Međutim, nakon OCR operacije, ako trebate sačuvati datoteku, konverzija u PDF format je održivo rješenje. U ovom članku raspravljat ćemo o koracima kako pretvoriti skenirani PDF u tekstualni PDF pomoću Pythona.
OCR PDF API
Aspose.PDF Cloud SDK za Python je omotač oko Aspose.PDF Cloud. Omogućuje vam izvođenje svih mogućnosti obrade PDF datoteka unutar Python aplikacije. Manipulirajte PDF datotekama bez programa Adobe Acrobat ili bilo koje druge aplikacije. Dakle, da biste koristili SDK, prvi korak je njegova instalacija, a dostupan je za preuzimanje preko PIP i GitHub repozitorija. Sada izvršite sljedeću naredbu na terminalu/naredbenom retku da biste instalirali najnoviju verziju SDK-a na sustav.
pip install asposepdfcloud
MS Visual Studio
Također možete izravno dodati referencu u svoj Python projekt unutar projekta Visual Studio. Molimo pretražite asposepdfcloud kao paket u prozoru okruženja Python. Slijedite korake označene brojevima na slici ispod kako biste dovršili postupak instalacije.
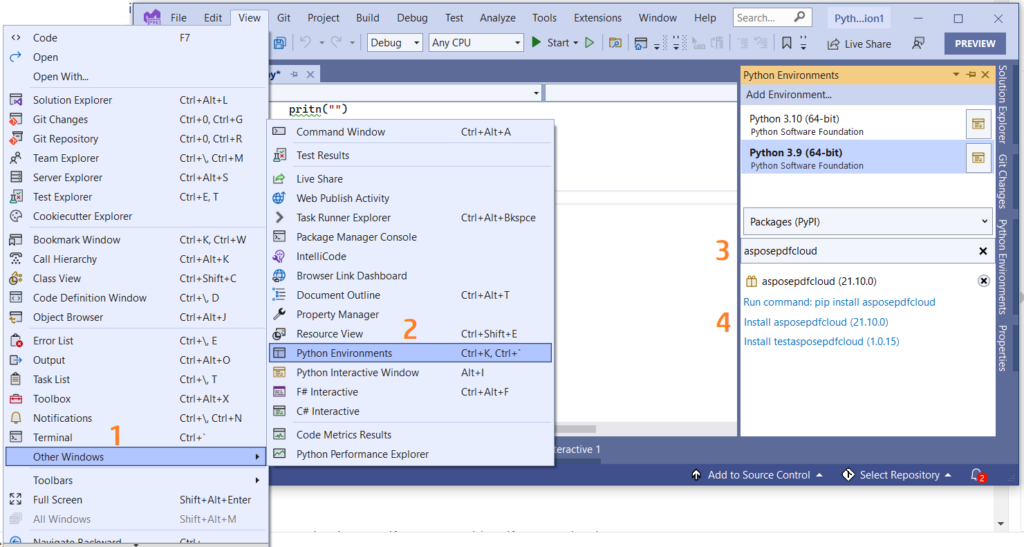
Slika 1:- Aspose.PDF Cloud SDK za Python paket.
Nadzorna ploča Aspose.Cloud
Budući da su naši API-ji dostupni samo ovlaštenim osobama, sljedeći korak je kreiranje računa na Aspose.Cloud nadzornoj ploči. Ako imate GitHub ili Google račun, jednostavno se prijavite ili kliknite na gumb Create a new Account i unesite tražene podatke. Sada se prijavite na nadzornu ploču pomoću vjerodajnica i proširite odjeljak Aplikacije s nadzorne ploče i pomaknite se prema dolje prema odjeljku Vjerodajnice klijenta kako biste vidjeli pojedinosti o ID-u klijenta i tajnoj tajni klijenta.
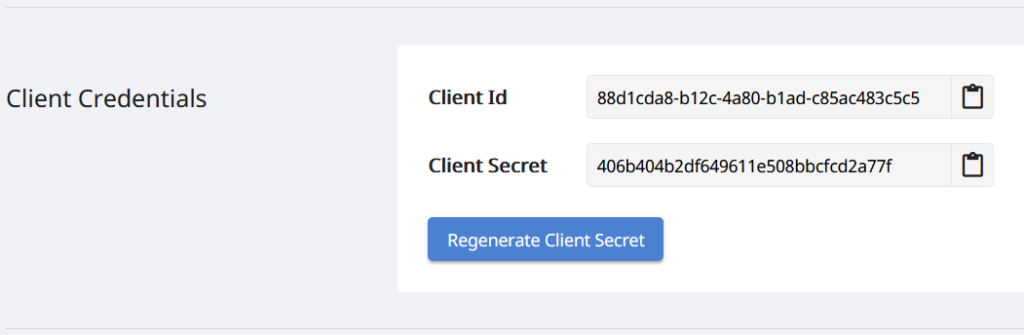
Slika 2: - vjerodajnice klijenta na nadzornoj ploči Aspose.Cloud.
PDF slike u PDF koji se može pretraživati u Pythonu
Slijedite dolje navedene korake za izvođenje OCR operacije na skeniranom PDF dokumentu i zatim ga spremite kao pretraživi (učinite pdf pretraživim). Ovi nam koraci pomažu da razvijemo besplatni online OCR pomoću Pythona.
- Prvo, moramo stvoriti instancu klase ApiClient dok dajemo Client ID Client Secret kao argumente
- Drugo, stvorite instancu PdfApi klase koja uzima ApiClient objekt kao ulazni argument
- Sada pozovite metodu putsearchabledocument(..) klase PdfApi koja uzima ulazni naziv PDF-a i izborni parametar koji označava jezik OCR mehanizma.
def ocrPDF():
try:
#Client credentials
client_secret = "406b404b2df649611e508bbcfcd2a77f"
client_id = "88d1cda8-b12c-4a80-b1ad-c85ac483c5c5"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# stvoriti PdfApi instancu dok prosljeđuje PdfApiClient kao argument
pdf_api = PdfApi(pdf_api_client)
#input PDF file name
input_file = 'image-based-pdf-sample.pdf'
# pozvati API za izvođenje OCR operacije i spremanje izlaza u pohranu u oblaku
response = pdf_api.put_searchable_document(name=input_file,lang='eng')
# ispis poruke u konzoli (opcionalno)
print('Image PDF successfully converted to Text PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
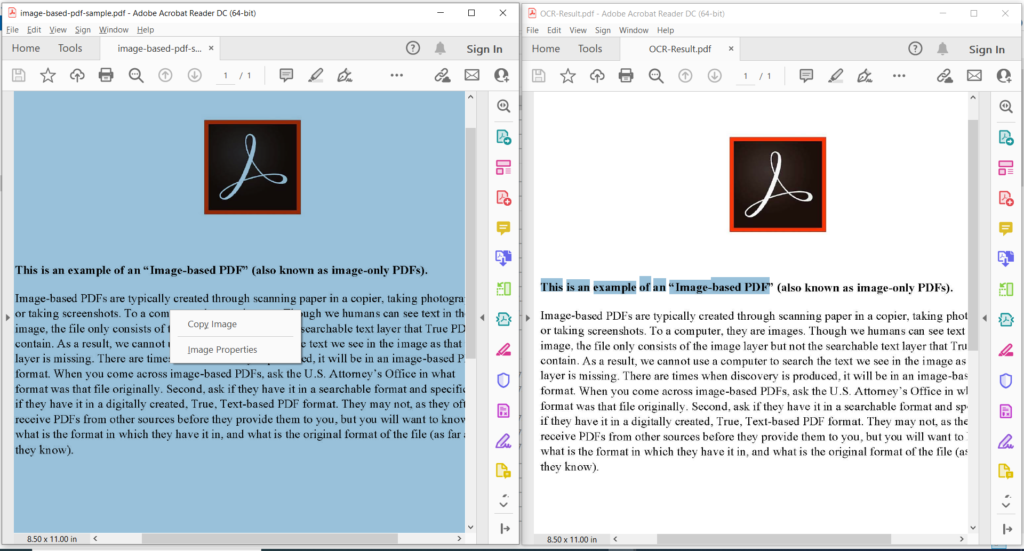
Slika 3: - Pregled PDF OCR operacije.
Na gornjoj slici lijevi dio označava ulaznu skeniranu PDF datoteku, a dio s desne strane prikazuje pregled rezultirajućeg tekstualnog PDF-a. Ogledne datoteke korištene u gornjem primjeru mogu se preuzeti s image-based-pdf-sample.pdf i OCR-Result.pdf.
OCR online pomoću cURL naredbi
REST API-jima također se može pristupiti putem cURL naredbi, a kako se naši Cloud API-ji temelje na REST arhitekturi, tako da također možemo koristiti cURL naredbu za izvođenje PDF OCR-a online. Međutim, prije nego što nastavimo s operacijom konverzije, moramo generirati JSON web token (JWT) na temelju vjerodajnica vašeg pojedinačnog klijenta navedenih na nadzornoj ploči Aspose.Cloud. To je obavezno jer su naši API-ji dostupni samo registriranim korisnicima. Molimo izvršite sljedeću naredbu za generiranje JWT tokena.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=88d1cda8-b12c-4a80-b1ad-c85ac483c5c5&client_secret=406b404b2df649611e508bbcfcd2a77f" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Nakon što dobijemo JWT token, molimo izvršite sljedeću naredbu za izvođenje OCR operacije i spremanje izlaza u istu pohranu u oblaku.
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/image-based-pdf-sample.pdf/ocr" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Zaključak
U ovom smo članku raspravljali o koracima za pretvaranje slikovnog PDF-a u pretraživi PDF pomoću Python isječka koda. Također smo istražili pojedinosti o tome kako izvesti OCR online pomoću cURL naredbi. Budući da su naši SDK-ovi za oblak razvijeni pod licencom MIT-a, možete preuzeti potpuni isječak koda s GitHub i ažurirati ga prema svojim zahtjevima. Toplo vam preporučujemo da istražite Vodič za razvojne programere kako biste saznali više o drugim uzbudljivim značajkama koje trenutno nudi Cloud API.
U slučaju da imate bilo kakvih povezanih pitanja ili naiđete na bilo kakve probleme tijekom korištenja naših API-ja, slobodno nas kontaktirajte putem besplatnog foruma za korisničku podršku.
povezani članci
Također predlažemo da prođete kroz sljedeće članke da biste saznali više o tome