
Datoteke PDF se v internetu pogosto uporabljajo za izmenjavo informacij in podatkov. So precej priljubljeni, ker ohranjajo zvestobo dokumentov pri ogledu na kateri koli platformi. Vendar pa nimamo nadzora nad virom in nekatere datoteke so v skupni rabi v skenirani obliki. Včasih zajamete sliko kot PDF in morate pozneje ekstrahirati vsebino iz datoteke. Izvedljiva rešitev je torej izvesti operacijo OCR in ekstrahirati besedilo. Če pa morate po operaciji OCR ohraniti datoteko, je pretvorba v format PDF izvedljiva rešitev. V tem članku bomo razpravljali o korakih za pretvorbo skeniranega PDF-ja v besedilni PDF s pomočjo Pythona.
OCR PDF API
Aspose.PDF Cloud SDK za Python je ovoj okoli Aspose.PDF Cloud. Omogoča vam izvajanje vseh zmožnosti obdelave datotek PDF v aplikaciji Python. Delajte z datotekami PDF brez programa Adobe Acrobat ali katere koli druge aplikacije. Če želite uporabiti SDK, je prvi korak njegova namestitev in je na voljo za prenos prek repozitorija PIP in GitHub. Zdaj izvedite naslednji ukaz na terminalu/ukaznem pozivu, da namestite najnovejšo različico SDK v sistem.
pip install asposepdfcloud
MS Visual Studio
Referenco lahko dodate tudi neposredno v svoj projekt Python znotraj projekta Visual Studio. Poiščite asposepdfcloud kot paket pod oknom okolja Python. Sledite korakom, oštevilčenim na spodnji sliki, da dokončate postopek namestitve.
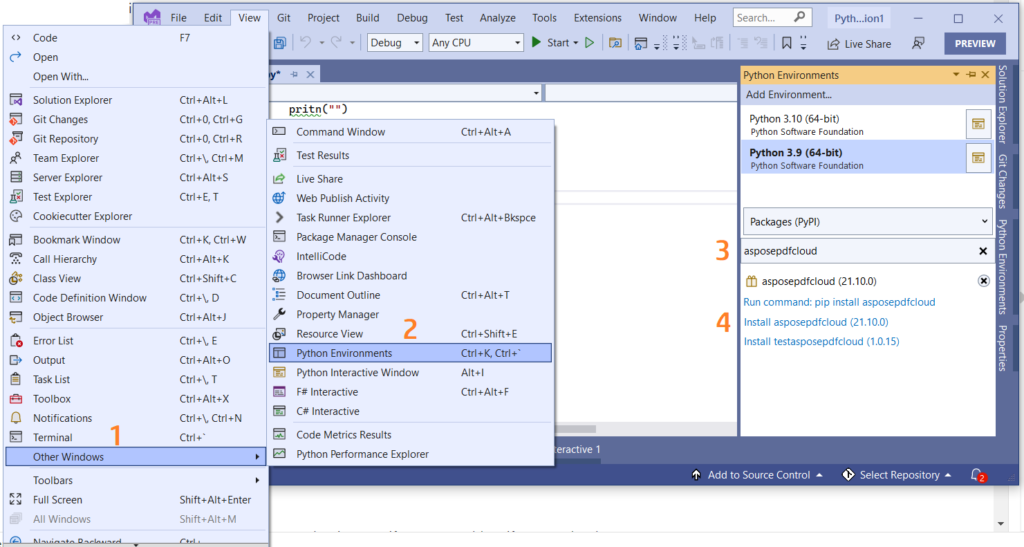
Slika 1:- Aspose.PDF Cloud SDK za paket Python.
Nadzorna plošča Aspose.Cloud
Ker so naši API-ji dostopni samo pooblaščenim osebam, je naslednji korak ustvarjanje računa na nadzorni plošči Aspose.Cloud. Če imate račun GitHub ali Google, se preprosto prijavite ali kliknite gumb Ustvari nov račun in vnesite zahtevane podatke. Zdaj se prijavite na nadzorno ploščo s poverilnicami in razširite razdelek z aplikacijami na nadzorni plošči ter se pomaknite navzdol do razdelka Poverilnice odjemalca, da si ogledate podrobnosti o ID-ju odjemalca in skrivnosti odjemalca.
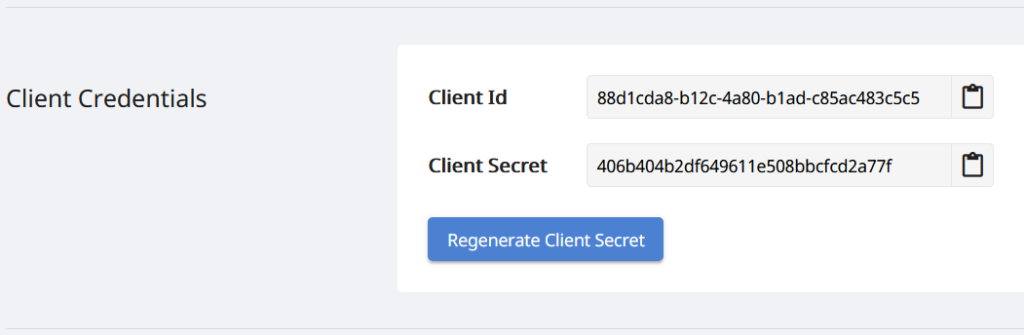
Slika 2: – Poverilnice odjemalca na nadzorni plošči Aspose.Cloud.
Slikovni PDF v PDF z možnostjo iskanja v Pythonu
Prosimo, sledite spodnjim korakom, da izvedete operacijo OCR na skeniranem dokumentu PDF in ga nato shranite kot iskalno (naredite pdf iskalno). Ti koraki nam pomagajo razviti brezplačno spletno OCR z uporabo Pythona.
- Najprej moramo ustvariti primerek razreda ApiClient, medtem ko kot argumente navedemo Client ID Client Secret
- Drugič, ustvarite primerek razreda PdfApi, ki sprejme objekt ApiClient kot vhodni argument
- Zdaj pokličite metodo putsearchabledocument(..) razreda PdfApi, ki sprejme vhodno ime PDF in izbirni parameter, ki označuje jezik mehanizma OCR.
def ocrPDF():
try:
#Client credentials
client_secret = "406b404b2df649611e508bbcfcd2a77f"
client_id = "88d1cda8-b12c-4a80-b1ad-c85ac483c5c5"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# ustvarite primerek PdfApi, medtem ko posredujete PdfApiClient kot argument
pdf_api = PdfApi(pdf_api_client)
#input PDF file name
input_file = 'image-based-pdf-sample.pdf'
# pokličite API za izvedbo operacije OCR in shranjevanje izhoda v shrambo v oblaku
response = pdf_api.put_searchable_document(name=input_file,lang='eng')
# natisni sporočilo v konzoli (neobvezno)
print('Image PDF successfully converted to Text PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
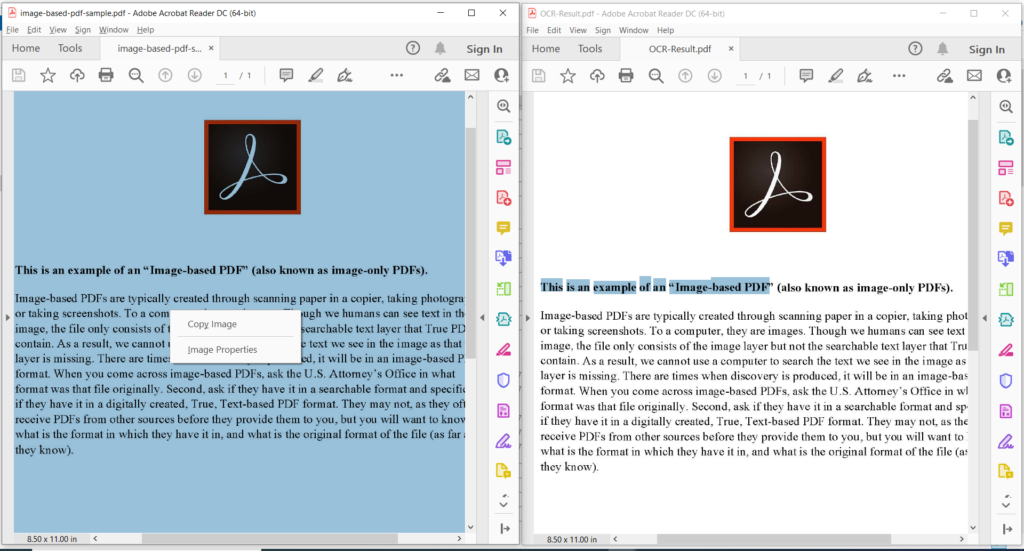
Slika 3: - Predogled delovanja PDF OCR.
Na zgornji sliki levi del označuje vhodno skenirano datoteko PDF, del na desni strani pa prikazuje predogled nastalega besedilnega PDF-ja. Vzorčne datoteke, uporabljene v zgornjem primeru, lahko prenesete iz image-based-pdf-sample.pdf in OCR-Result.pdf.
OCR na spletu z uporabo ukazov cURL
Do API-jev REST je mogoče dostopati tudi prek ukazov cURL in ker naši API-ji v oblaku temeljijo na arhitekturi REST, lahko uporabimo tudi ukaz cURL za spletno OCR PDF. Preden pa nadaljujemo s pretvorbo, moramo ustvariti spletni žeton JSON (JWT) na podlagi poverilnic vašega posameznega odjemalca, navedenih na nadzorni plošči Aspose.Cloud. To je obvezno, ker so naši API-ji dostopni samo registriranim uporabnikom. Izvedite naslednji ukaz, da ustvarite žeton JWT.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=88d1cda8-b12c-4a80-b1ad-c85ac483c5c5&client_secret=406b404b2df649611e508bbcfcd2a77f" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Ko imamo žeton JWT, izvedite naslednji ukaz, da izvedete operacijo OCR in shranite izhod v isto shrambo v oblaku.
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/image-based-pdf-sample.pdf/ocr" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Zaključek
V tem članku smo razpravljali o korakih za pretvorbo slikovnega PDF-ja v PDF, po katerem je mogoče iskati, z uporabo izrezka kode Python. Raziskali smo tudi podrobnosti o tem, kako izvesti OCR Online z uporabo ukazov cURL. Ker so naši SDK-ji v oblaku razviti pod licenco MIT, lahko prenesete celoten delček kode iz GitHub in ga posodobite v skladu s svojimi zahtevami. Toplo vam priporočamo, da raziščete Vodnik za razvijalce, če želite izvedeti več o drugih vznemirljivih funkcijah, ki jih trenutno ponuja Cloud API.
Če imate kakršne koli povezane poizvedbe ali naletite na kakršne koli težave pri uporabi naših API-jev, se obrnite na nas prek brezplačnega foruma za podporo strankam.
povezani članki
Predlagamo tudi, da preberete naslednje članke, če želite izvedeti več o tem