
PDF file banyak digunakan melalui internet untuk berbagi informasi dan data. Mereka cukup populer karena mempertahankan kesetiaan dokumen saat dilihat di platform apa pun. Namun, kami tidak memiliki kendali atas sumber dan beberapa file dibagikan dalam format pindaian. Terkadang Anda mengambil gambar sebagai PDF dan nanti Anda perlu mengekstrak konten dari file tersebut. Jadi solusi yang layak adalah melakukan operasi OCR dan mengekstrak teksnya. Namun, setelah operasi OCR, jika Anda perlu menyimpan file, konversi ke format PDF adalah solusi yang layak. Pada artikel ini, kita akan membahas langkah-langkah tentang cara mengonversi PDF yang dipindai menjadi PDF Teks menggunakan Python.
API PDF OCR
Aspose.PDF Cloud SDK untuk Python adalah pembungkus dari Aspose.PDF Cloud. Ini memungkinkan Anda untuk melakukan semua kemampuan pemrosesan file PDF dalam aplikasi Python. Memanipulasi file PDF tanpa Adobe Acrobat atau aplikasi lainnya. Jadi untuk menggunakan SDK, langkah pertama adalah penginstalannya, dan SDK tersedia untuk diunduh melalui repositori PIP dan GitHub. Sekarang jalankan perintah berikut pada terminal/command prompt untuk menginstal versi terbaru SDK pada sistem.
pip install asposepdfcloud
M.Visual Studio
Anda juga dapat langsung menambahkan referensi dalam proyek Python Anda di dalam proyek Visual Studio. Silakan cari asposepdfcloud sebagai paket di bawah jendela lingkungan Python. Silakan ikuti langkah-langkah bernomor pada gambar di bawah ini untuk menyelesaikan proses instalasi.
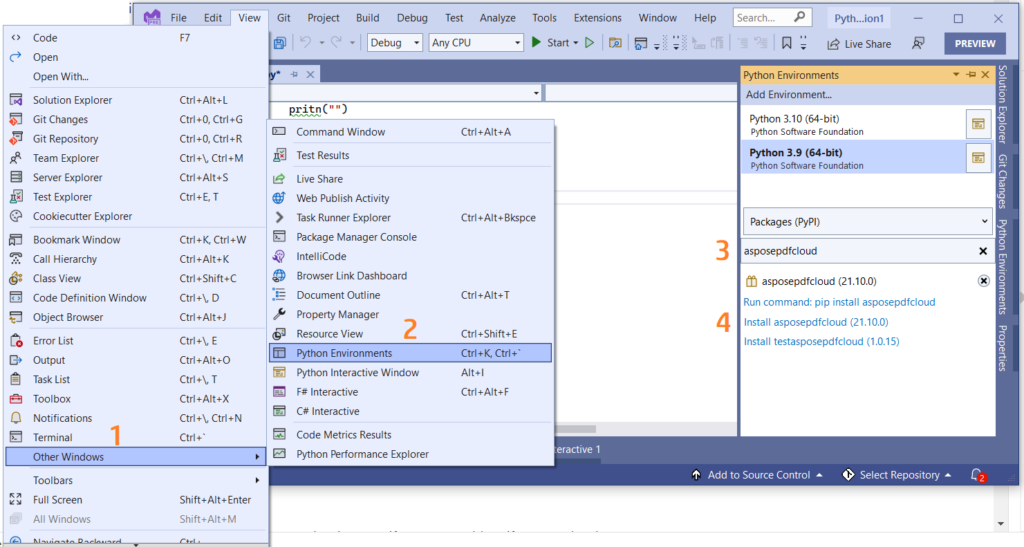
Gambar 1:- Aspose.PDF Cloud SDK untuk paket Python.
Dasbor Aspose.Cloud
Karena API kami hanya dapat diakses oleh orang yang berwenang, maka langkah selanjutnya adalah membuat akun di Dasbor Aspose.Cloud. Jika Anda memiliki akun GitHub atau Google, cukup Daftar atau, klik tombol Buat Akun baru dan berikan informasi yang diperlukan. Sekarang masuk ke dasbor menggunakan kredensial dan perluas bagian Aplikasi dari dasbor dan gulir ke bawah ke bagian Kredensial Klien untuk melihat detail ID Klien dan Rahasia Klien.

Gambar 2:- Kredensial klien di dasbor Aspose.Cloud.
Gambar PDF ke PDF yang Dapat Dicari dengan Python
Silakan ikuti langkah-langkah yang diberikan di bawah ini untuk melakukan operasi OCR pada dokumen PDF yang dipindai dan kemudian simpan sebagai dapat dicari (jadikan pdf dapat dicari). Langkah-langkah ini membantu kami mengembangkan OCR online gratis menggunakan Python.
- Pertama, kita perlu membuat instance kelas ApiClient sambil memberikan Client ID Client Secret sebagai argumen
- Kedua, buat instance kelas PdfApi yang menggunakan objek ApiClient sebagai argumen masukan
- Sekarang panggil metode putsearchabledocument(..) dari kelas PdfApi yang mengambil nama input PDF dan parameter opsional yang menunjukkan bahasa mesin OCR.
def ocrPDF():
try:
#Client credentials
client_secret = "406b404b2df649611e508bbcfcd2a77f"
client_id = "88d1cda8-b12c-4a80-b1ad-c85ac483c5c5"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# buat instance PdfApi sambil meneruskan PdfApiClient sebagai argumen
pdf_api = PdfApi(pdf_api_client)
#input PDF file name
input_file = 'image-based-pdf-sample.pdf'
# memanggil API untuk melakukan operasi OCR dan menyimpan hasilnya di penyimpanan cloud
response = pdf_api.put_searchable_document(name=input_file,lang='eng')
# cetak pesan di konsol (opsional)
print('Image PDF successfully converted to Text PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)

Gambar 3: - Pratinjau operasi PDF OCR.
Pada gambar di atas, bagian kiri menunjukkan input file PDF yang dipindai dan bagian di sisi kanan menunjukkan pratinjau PDF berbasis teks yang dihasilkan. File sampel yang digunakan dalam contoh di atas dapat diunduh dari image-based-pdf-sample.pdf dan OCR-Result.pdf.
OCR online menggunakan Perintah cURL
REST API juga dapat diakses melalui perintah cURL dan karena Cloud API kami didasarkan pada arsitektur REST, maka kami juga dapat menggunakan perintah cURL untuk menjalankan PDF OCR online. Namun, sebelum melanjutkan operasi konversi, kami perlu membuat JSON Web Token (JWT) berdasarkan kredensial klien individual Anda yang ditentukan melalui dasbor Aspose.Cloud. Wajib karena API kami hanya dapat diakses oleh pengguna terdaftar. Silakan jalankan perintah berikut untuk menghasilkan token JWT.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=88d1cda8-b12c-4a80-b1ad-c85ac483c5c5&client_secret=406b404b2df649611e508bbcfcd2a77f" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Setelah kami memiliki token JWT, harap jalankan perintah berikut untuk melakukan operasi OCR dan simpan hasilnya di penyimpanan cloud yang sama.
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/image-based-pdf-sample.pdf/ocr" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Kesimpulan
Pada artikel ini, kami telah membahas langkah-langkah Image PDF to Searchable PDF menggunakan potongan kode Python. Kami juga telah menjelajahi detail tentang cara melakukan OCR Online menggunakan perintah cURL. Karena cloud SDK kami dikembangkan di bawah lisensi MIT, maka Anda dapat mengunduh cuplikan kode lengkap dari GitHub dan memperbaruinya sesuai kebutuhan Anda. Kami sangat menyarankan Anda untuk menjelajahi Panduan Pengembang untuk mempelajari lebih lanjut tentang fitur menarik lainnya yang saat ini ditawarkan oleh Cloud API.
Jika Anda memiliki pertanyaan terkait atau mengalami masalah saat menggunakan API kami, jangan ragu untuk menghubungi kami melalui forum dukungan pelanggan gratis.
Artikel Terkait
Kami juga menyarankan untuk membaca artikel berikut untuk mempelajari lebih lanjut