
PDF-tiedostoja käytetään laajasti Internetissä tiedon jakamiseen. Ne ovat melko suosittuja, koska ne säilyttävät asiakirjojen uskollisuuden, kun niitä tarkastellaan millä tahansa alustalla. Emme kuitenkaan voi hallita lähdettä, ja jotkin tiedostot jaetaan skannatussa muodossa. Joskus otat kuvan PDF-muodossa ja myöhemmin sinun on purettava sisältö tiedostosta. Joten toteuttamiskelpoinen ratkaisu on suorittaa OCR-toiminto ja purkaa teksti. Kuitenkin tekstintunnistustoiminnon jälkeen, jos sinun on säilytettävä tiedosto, muuntaminen PDF-muotoon on varteenotettava ratkaisu. Tässä artikkelissa aiomme keskustella vaiheista, joilla skannattu PDF muunnetaan teksti-PDF:ksi Pythonin avulla.
OCR PDF API
Aspose.PDF Cloud SDK Pythonille on kääre Aspose.PDF Cloud:n ympärille. Sen avulla voit suorittaa kaikki PDF-tiedostojen käsittelyominaisuudet Python-sovelluksessa. Käsittele PDF-tiedostoja ilman Adobe Acrobatia tai muita sovelluksia. Joten SDK:n käyttämiseksi ensimmäinen vaihe on sen asennus, ja se on ladattavissa PIP- ja GitHub-arkiston kautta. Asenna SDK:n uusin versio järjestelmään suorittamalla seuraava komento pääte-/komentokehotteessa.
pip install asposepdfcloud
MS Visual Studio
Voit myös lisätä viitteen suoraan Python-projektiisi Visual Studio -projektissa. Hae asposepdfcloud pakettina Python-ympäristöikkunan alta. Suorita asennus loppuun noudattamalla alla olevassa kuvassa numeroituja vaiheita.
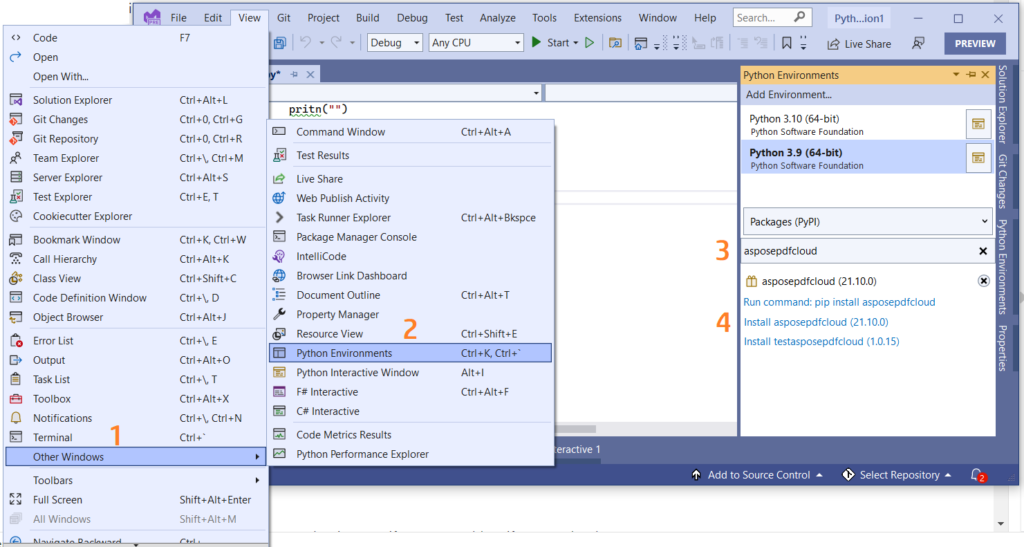
Kuva 1: - Aspose.PDF Cloud SDK Pythonille.
Aspose.Cloud Dashboard
Koska sovellusliittymiemme ovat vain valtuutettujen henkilöiden käytettävissä, seuraava vaihe on luoda tili Aspose.Cloud dashboardissa. Jos sinulla on GitHub- tai Google-tili, rekisteröidy tai napsauta Luo uusi tili -painiketta ja anna tarvittavat tiedot. Kirjaudu nyt kojelautaan valtuustiedoilla ja laajenna kojelaudan Sovellukset-osio ja vieritä alas kohti Asiakastunnukset-osiota nähdäksesi asiakastunnuksen ja asiakassalaisuuden tiedot.
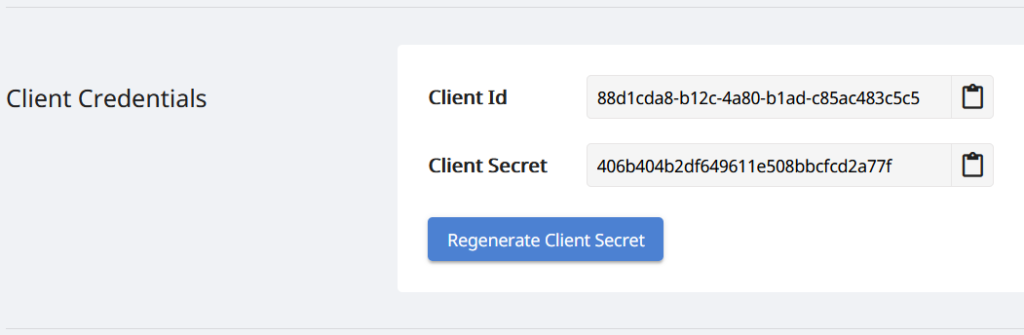
Kuva 2: - Asiakkaan kirjautumistiedot Aspose.Cloud-hallintapaneelissa.
Kuva-PDF haettavaksi PDF-tiedostoksi Pythonissa
Suorita tekstintunnistustoiminto skannatulle PDF-asiakirjalle alla annettujen ohjeiden mukaisesti ja tallenna se sitten haettavaksi (tee pdf-tiedostosta haettavaksi). Nämä vaiheet auttavat meitä kehittämään ilmaisen online-OCR:n Pythonilla.
- Ensin meidän on luotava ApiClient-luokan esiintymä ja annettava Client ID Client Secret -argumentteina
- Toiseksi luo PdfApi-luokan esiintymä, joka ottaa ApiClient-objektin syöteargumenttina
- Kutsu nyt putsearchabledocument(..) PdfApi-luokan menetelmää, joka ottaa syötetyn PDF-nimen ja valinnaisen parametrin, joka ilmaisee OCR-moottorin kielen.
def ocrPDF():
try:
#Client credentials
client_secret = "406b404b2df649611e508bbcfcd2a77f"
client_id = "88d1cda8-b12c-4a80-b1ad-c85ac483c5c5"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# luo PdfApi-ilmentymä ja välitä PdfApiClient argumenttina
pdf_api = PdfApi(pdf_api_client)
#input PDF file name
input_file = 'image-based-pdf-sample.pdf'
# kutsu API suorittaaksesi OCR-toiminnon ja tallentaaksesi tulosteen pilvitallennustilaan
response = pdf_api.put_searchable_document(name=input_file,lang='eng')
# tulosta viesti konsolissa (valinnainen)
print('Image PDF successfully converted to Text PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
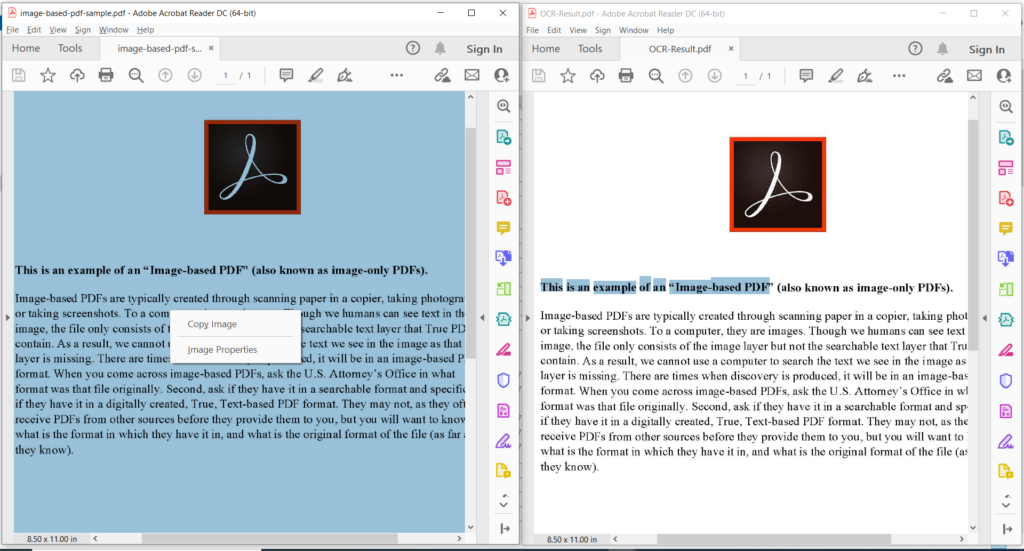
Kuva 3: - Esikatselu PDF-tekstintunnistustoiminnosta.
Yllä olevassa kuvassa vasen osa tarkoittaa syötettyä skannattua PDF-tiedostoa ja oikealla puolella oleva osa näyttää esikatselun tuloksena olevasta tekstipohjaisesta PDF-tiedostosta. Yllä olevassa esimerkissä käytetyt mallitiedostot voidaan ladata osoitteesta image-based-pdf-sample.pdf ja OCR-Result.pdf.
OCR verkossa cURL-komentojen avulla
REST-sovellusliittymiä voidaan käyttää myös cURL-komennoilla, ja koska pilvisovellusliittymämme perustuvat REST-arkkitehtuuriin, voimme myös käyttää cURL-komentoa PDF-tunnistuksen suorittamiseen verkossa. Ennen kuin jatkamme muunnostoimintoa, meidän on kuitenkin luotava JSON Web Token (JWT) Aspose.Cloud-hallintapaneelissa määritettyjen yksittäisten asiakastietojesi perusteella. Se on pakollinen, koska sovellusliittymämme ovat vain rekisteröityneiden käyttäjien käytettävissä. Suorita seuraava komento luodaksesi JWT-tunnus.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=88d1cda8-b12c-4a80-b1ad-c85ac483c5c5&client_secret=406b404b2df649611e508bbcfcd2a77f" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Kun meillä on JWT-tunnus, suorita OCR-toiminto ja tallenna tulos samaan pilvitallennustilaan suorittamalla seuraava komento.
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/image-based-pdf-sample.pdf/ocr" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Johtopäätös
Tässä artikkelissa olemme keskustelleet vaiheista, joilla voit muuttaa PDF-kuvan haettavaksi PDF-tiedostoksi Python-koodinpätkän avulla. Olemme myös tutkineet yksityiskohtia OCR Onlinen suorittamisesta cURL-komentojen avulla. Koska pilvi-SDK:mme on kehitetty MIT-lisenssillä, voit ladata täydellisen koodinpätkän GitHubista ja päivittää sen tarpeidesi mukaan. Suosittelemme tutustumaan Kehittäjäoppaaseen saadaksesi lisätietoja muista Cloud API:n tällä hetkellä tarjoamista jännittävistä ominaisuuksista.
Jos sinulla on aiheeseen liittyviä kysymyksiä tai kohtaat ongelmia sovellusliittymiemme käytössä, ota meihin yhteyttä ilmaisen asiakastukifoorumin kautta.
Aiheeseen liittyvät artikkelit
Suosittelemme myös tutustumaan seuraaviin artikkeleihin saadaksesi lisätietoja