
PDF failai internete plačiai naudojami informacijai ir duomenims dalytis. Jie yra gana populiarūs, nes išlaiko dokumentų patikimumą žiūrint bet kurioje platformoje. Tačiau mes nevaldome šaltinio ir kai kurie failai bendrinami nuskaitytu formatu. Kartais vaizdą užfiksuojate kaip PDF, o vėliau reikia išgauti turinį iš failo. Taigi tinkamas sprendimas yra atlikti OCR operaciją ir išgauti tekstą. Tačiau po OCR operacijos, jei reikia išsaugoti failą, konvertavimas į PDF formatą yra perspektyvus sprendimas. Šiame straipsnyje aptarsime veiksmus, kaip konvertuoti nuskaitytą PDF į tekstinį PDF naudojant Python.
OCR PDF API
Aspose.PDF Cloud SDK, skirtas Python yra Aspose.PDF Cloud įvyniojimas. Tai leidžia atlikti visas PDF failų apdorojimo galimybes Python programoje. Manipuliuokite PDF failais nenaudodami „Adobe Acrobat“ ar kitos programos. Taigi, norint naudoti SDK, pirmiausia reikia jį įdiegti ir jį galima atsisiųsti per PIP ir GitHub saugyklas. Dabar vykdykite šią komandą terminale / komandų eilutėje, kad sistemoje įdiegtumėte naujausią SDK versiją.
pip install asposepdfcloud
MS Visual Studio
Taip pat galite tiesiogiai pridėti nuorodą į savo Python projektą „Visual Studio“ projekte. Ieškokite asposepdfcloud kaip paketo Python aplinkos lange. Atlikite toliau esančiame paveikslėlyje sunumeruotus veiksmus, kad užbaigtumėte diegimo procesą.
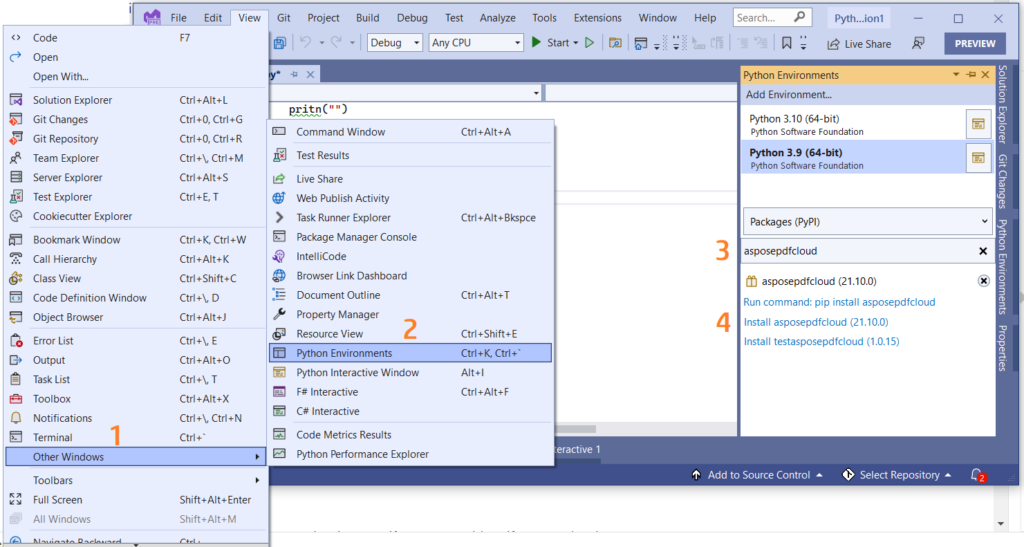
1 vaizdas: Aspose.PDF Cloud SDK, skirtas Python paketui.
Aspose.Cloud Dashboard
Kadangi mūsų API gali pasiekti tik įgalioti asmenys, kitas žingsnis yra sukurti paskyrą Aspose.Cloud dashboard. Jei turite „GitHub“ arba „Google“ paskyrą, tiesiog prisiregistruokite arba spustelėkite mygtuką Sukurti naują paskyrą ir pateikite reikiamą informaciją. Dabar prisijunkite prie prietaisų skydelio naudodami kredencialus ir išskleiskite skyrių Programos iš prietaisų skydelio ir slinkite žemyn link Kliento kredencialų skyriaus, kad pamatytumėte išsamią kliento ID ir kliento paslapties informaciją.
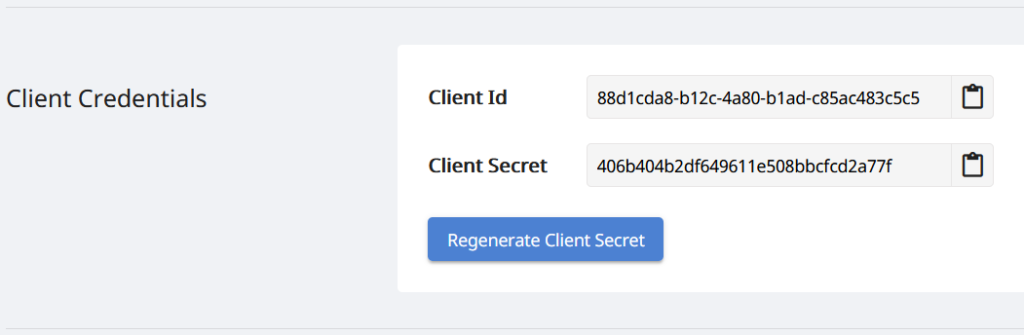
2 vaizdas: – kliento kredencialai Aspose.Cloud prietaisų skydelyje.
Vaizdo PDF į ieškomą PDF formatą Python
Atlikite toliau nurodytus veiksmus, kad atliktumėte OCR operaciją nuskaitytame PDF dokumente ir išsaugokite jį kaip ieškomą (padarykite pdf formatą, kad būtų galima ieškoti). Šie veiksmai padeda mums sukurti nemokamą internetinį OCR naudojant Python.
- Pirmiausia turime sukurti „ApiClient“ klasės egzempliorių, kaip argumentus pateikdami „Client ID Client Secret“
- Antra, sukurkite PdfApi klasės egzempliorių, kuris naudoja ApiClient objektą kaip įvesties argumentą
- Dabar iškvieskite PdfApi klasės metodą putsearchabledocument(..), kuris paima įvesties PDF pavadinimą ir pasirenkamą parametrą, nurodantį OCR variklio kalbą.
def ocrPDF():
try:
#Client credentials
client_secret = "406b404b2df649611e508bbcfcd2a77f"
client_id = "88d1cda8-b12c-4a80-b1ad-c85ac483c5c5"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# sukurti PdfApi egzempliorių, perduodant PdfApiClient kaip argumentą
pdf_api = PdfApi(pdf_api_client)
#input PDF file name
input_file = 'image-based-pdf-sample.pdf'
# paskambinkite API, kad atliktumėte OCR operaciją ir išsaugotumėte išvestį debesies saugykloje
response = pdf_api.put_searchable_document(name=input_file,lang='eng')
# spausdinti pranešimą konsolėje (pasirinktinai)
print('Image PDF successfully converted to Text PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
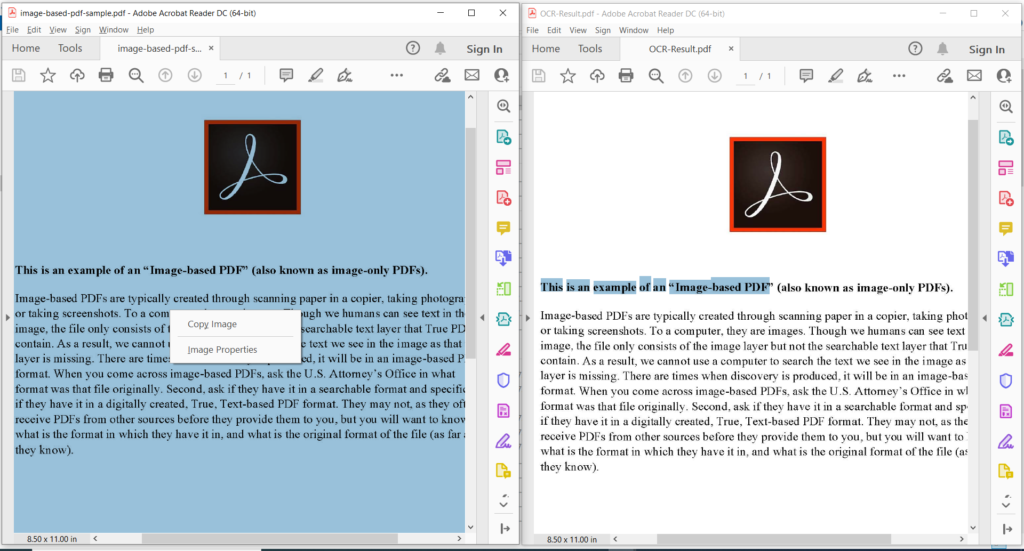
3 vaizdas: PDF OCR operacijos peržiūra.
Aukščiau esančiame paveikslėlyje kairioji dalis žymi įvestą nuskaitytą PDF failą, o dešinėje pusėje rodoma gauto tekstinio PDF peržiūra. Anksčiau pateiktame pavyzdyje naudotus pavyzdinius failus galima atsisiųsti iš image-based-pdf-sample.pdf ir OCR-Result.pdf.
OCR internete naudojant cURL komandas
REST API taip pat galima pasiekti naudojant cURL komandas, o mūsų debesies API yra pagrįstos REST architektūra, todėl galime naudoti cURL komandą PDF OCR internete atlikti. Tačiau prieš tęsdami konvertavimo operaciją, turime sugeneruoti JSON žiniatinklio prieigos raktą (JWT), pagrįstą jūsų individualiais kliento kredencialais, nurodytais Aspose.Cloud prietaisų skydelyje. Tai privaloma, nes mūsų API gali pasiekti tik registruoti vartotojai. Vykdykite šią komandą, kad sugeneruotumėte JWT prieigos raktą.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=88d1cda8-b12c-4a80-b1ad-c85ac483c5c5&client_secret=406b404b2df649611e508bbcfcd2a77f" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Kai turėsime JWT prieigos raktą, vykdykite šią komandą, kad atliktumėte OCR operaciją ir išsaugotumėte išvestį toje pačioje debesies saugykloje.
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/image-based-pdf-sample.pdf/ocr" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Išvada
Šiame straipsnyje aptarėme žingsnius, kaip vaizdo PDF paversti ieškomu PDF naudojant Python kodo fragmentą. Taip pat ištyrėme išsamią informaciją, kaip atlikti OCR internete naudojant cURL komandas. Kadangi mūsų debesies SDK yra sukurti pagal MIT licenciją, galite atsisiųsti visą kodo fragmentą iš GitHub ir atnaujinti jį pagal savo poreikius. Labai rekomenduojame peržiūrėti Kūrėjo vadovą, kad sužinotumėte daugiau apie kitas įdomias funkcijas, kurias šiuo metu siūlo debesies API.
Jei turite kokių nors susijusių užklausų arba naudodami API, susisiekite su mumis per nemokamą klientų aptarnavimo forumą.
susiję straipsniai
Taip pat siūlome perskaityti šiuos straipsnius, kad sužinotumėte daugiau