
Os arquivos PDF são amplamente utilizados na Internet para compartilhamento de informações e dados. Eles são bastante populares porque mantêm a fidelidade dos documentos ao visualizá-los em qualquer plataforma. No entanto, não temos controle sobre a origem e alguns arquivos são compartilhados em formato digitalizado. Às vezes você captura uma imagem como um PDF e depois precisa extrair o conteúdo do arquivo. Portanto, uma solução viável é realizar uma operação de OCR e extrair o texto. No entanto, após a operação de OCR, se você precisar preservar o arquivo, a conversão para o formato PDF é uma solução viável. Neste artigo, discutiremos as etapas de como converter um PDF digitalizado em PDF de texto usando Python.
API PDF de OCR
Aspose.PDF Cloud SDK para Python é um wrapper em torno de Aspose.PDF Cloud. Ele permite que você execute todos os recursos de processamento de arquivos PDF no aplicativo Python. Manipule arquivos PDF sem Adobe Acrobat ou qualquer outro aplicativo. Assim, para utilizar o SDK, o primeiro passo é a sua instalação, estando disponível para download nos repositórios PIP e GitHub. Agora execute o seguinte comando no terminal/prompt de comando para instalar a versão mais recente do SDK no sistema.
pip install asposepdfcloud
MS Visual Studio
Você também pode adicionar diretamente a referência em seu projeto Python dentro do projeto do Visual Studio. Pesquise asposepdfcloud como um pacote na janela do ambiente Python. Siga as etapas numeradas na imagem abaixo para concluir o processo de instalação.

Imagem 1:- Pacote Aspose.PDF Cloud SDK para Python.
Painel do Aspose.Cloud
Como nossas APIs só podem ser acessadas por pessoas autorizadas, o próximo passo é criar uma conta no painel do Aspose.Cloud. Se você tiver uma conta do GitHub ou do Google, basta se inscrever ou clicar no botão Criar uma nova conta e fornecer as informações necessárias. Agora faça login no painel usando credenciais e expanda a seção Aplicativos no painel e role para baixo até a seção Credenciais do cliente para ver os detalhes de ID e Segredo do cliente.
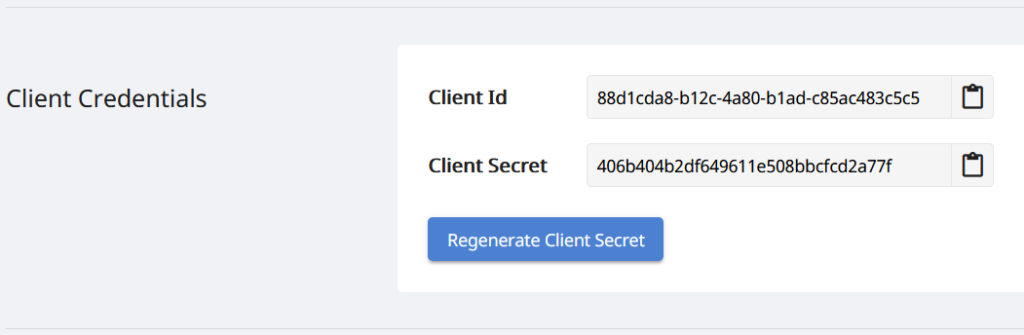
Imagem 2:- Credenciais do cliente no painel do Aspose.Cloud.
PDF de imagem para PDF pesquisável em Python
Siga as etapas abaixo para executar a operação de OCR em um documento PDF digitalizado e salve-o como pesquisável (tornar o PDF pesquisável). Essas etapas nos ajudam a desenvolver OCR online gratuito usando Python.
- Primeiro, precisamos criar uma instância da classe ApiClient enquanto fornecemos Client ID Client Secret como argumentos
- Em segundo lugar, crie uma instância da classe PdfApi que usa o objeto ApiClient como argumento de entrada
- Agora chame o método putsearchabledocument(..) da classe PdfApi, que recebe o nome do PDF de entrada e um parâmetro opcional que indica o idioma do mecanismo de OCR.
def ocrPDF():
try:
#Client credentials
client_secret = "406b404b2df649611e508bbcfcd2a77f"
client_id = "88d1cda8-b12c-4a80-b1ad-c85ac483c5c5"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# criar instância PdfApi ao passar PdfApiClient como argumento
pdf_api = PdfApi(pdf_api_client)
#input PDF file name
input_file = 'image-based-pdf-sample.pdf'
# chame a API para executar a operação de OCR e salve a saída no armazenamento em nuvem
response = pdf_api.put_searchable_document(name=input_file,lang='eng')
# imprimir mensagem no console (opcional)
print('Image PDF successfully converted to Text PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
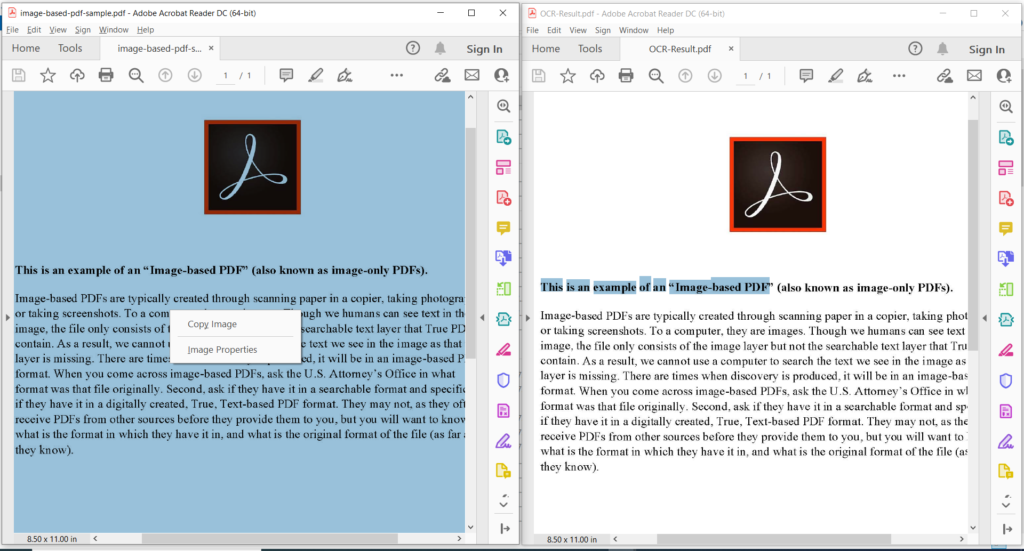
Imagem 3:- Pré-visualização da operação PDF OCR.
Na imagem acima, a parte esquerda denota o arquivo PDF digitalizado de entrada e a parte do lado direito mostra uma visualização do PDF baseado em texto resultante. Os arquivos de amostra usados no exemplo acima podem ser baixados de image-based-pdf-sample.pdf e OCR-Result.pdf.
OCR online usando comandos cURL
As APIs REST também podem ser acessadas por meio de comandos cURL e, como nossas APIs de nuvem são baseadas na arquitetura REST, também podemos usar o comando cURL para executar PDF OCR online. No entanto, antes de prosseguir com a operação de conversão, precisamos gerar um JSON Web Token (JWT) com base nas credenciais individuais do cliente especificadas no painel do Aspose.Cloud. É obrigatório porque nossas APIs são acessíveis apenas para usuários registrados. Execute o seguinte comando para gerar o token JWT.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=88d1cda8-b12c-4a80-b1ad-c85ac483c5c5&client_secret=406b404b2df649611e508bbcfcd2a77f" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Assim que tivermos o token JWT, execute o seguinte comando para executar a operação de OCR e salve a saída no mesmo armazenamento em nuvem.
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/image-based-pdf-sample.pdf/ocr" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Conclusão
Neste artigo, discutimos as etapas para PDF de imagem para PDF pesquisável usando o trecho de código Python. Também exploramos os detalhes de como executar o OCR Online usando os comandos cURL. Como nossos SDKs de nuvem são desenvolvidos sob licença do MIT, você pode baixar o snippet de código completo do GitHub e atualizá-lo de acordo com seus requisitos. É altamente recomendável que você explore o Guia do desenvolvedor para saber mais sobre outros recursos interessantes atualmente oferecidos pela Cloud API.
Caso você tenha alguma dúvida relacionada ou encontre algum problema ao usar nossas APIs, sinta-se à vontade para nos contatar por meio do fórum gratuito de suporte ao cliente.
Artigos relacionados
Também sugerimos ler os seguintes artigos para saber mais sobre