
PDF files are widely used over the internet for information and data sharing. They are quite popular because they maintain the fidelity of documents when viewing on any platform. However, we do not have control over the source and some files are shared in scanned format. Sometimes you capture an image as a PDF and later you need to extract the content from the file. So a viable solution is to perform an OCR operation and extract the text. However, after the OCR operation, if you need to preserve the file, then conversion to PDF format is a viable solution. In this article, we are going to discuss the steps on how to convert a scanned PDF to Text PDF using Python.
OCR PDF API
Aspose.PDF Cloud SDK for Python is a wrapper around Aspose.PDF Cloud. It enables you to perform all PDF file processing capabilities within the Python application. Manipulate PDF files without Adobe Acrobat or any other application. So in order to use the SDK, the first step is its installation, and it’s available for download over PIP and GitHub repository. Now execute the following command on the terminal/command prompt to install the latest version of SDK on the system.
pip install asposepdfcloud
MS Visual Studio
You may also directly add the reference in your Python project within the Visual Studio project. Please search asposepdfcloud as a package under the Python environment window. Please follow the steps numbered in the image below to complete the installation process.
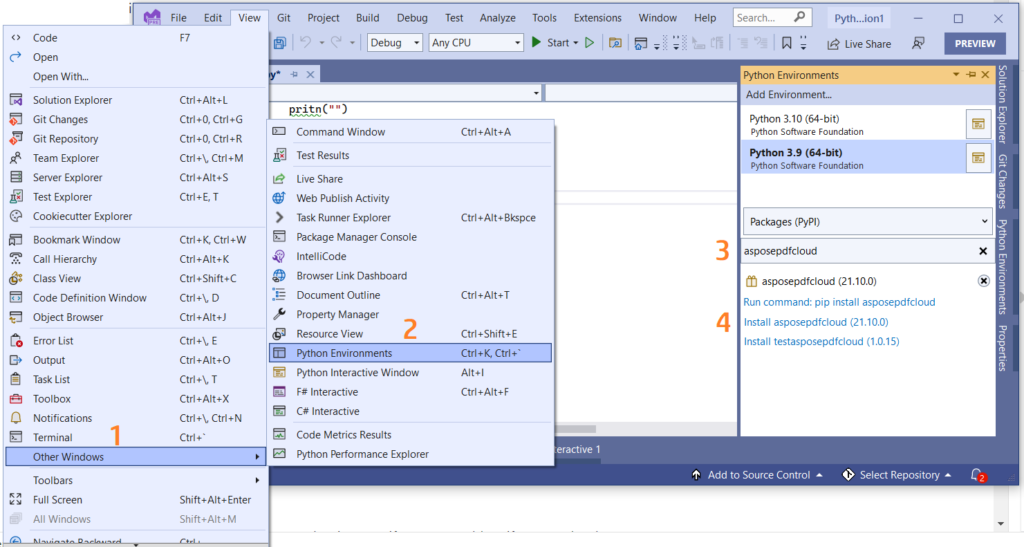
Image 1:- Aspose.PDF Cloud SDK for Python package.
Aspose.Cloud Dashboard
Since our APIs are only accessible to authorized persons, so the next step is to create an account on Aspose.Cloud dashboard. If you have GitHub or Google account, simply Sign Up or, click on the Create a new Account button and provide the required information. Now login to the dashboard using credentials and expand the Applications section from the dashboard and scroll down towards the Client Credentials section to see Client ID and Client Secret details.

Image 2:- Client credentials on Aspose.Cloud dashboard.
Image PDF to Searchable PDF in Python
Please follow the steps given below to perform OCR operation on a scanned PDF document and then save it as a searchable (make pdf searchable). These steps help us to develop free online OCR using Python.
- First, we need to create an instance of ApiClient class while providing Client ID Client Secret as arguments
- Secondly, create an instance of PdfApi class which takes ApiClient object as input argument
- Now call the put_searchable_document(..) method of PdfApi class which takes input PDF name and an optional parameter indicating the language of OCR engine.
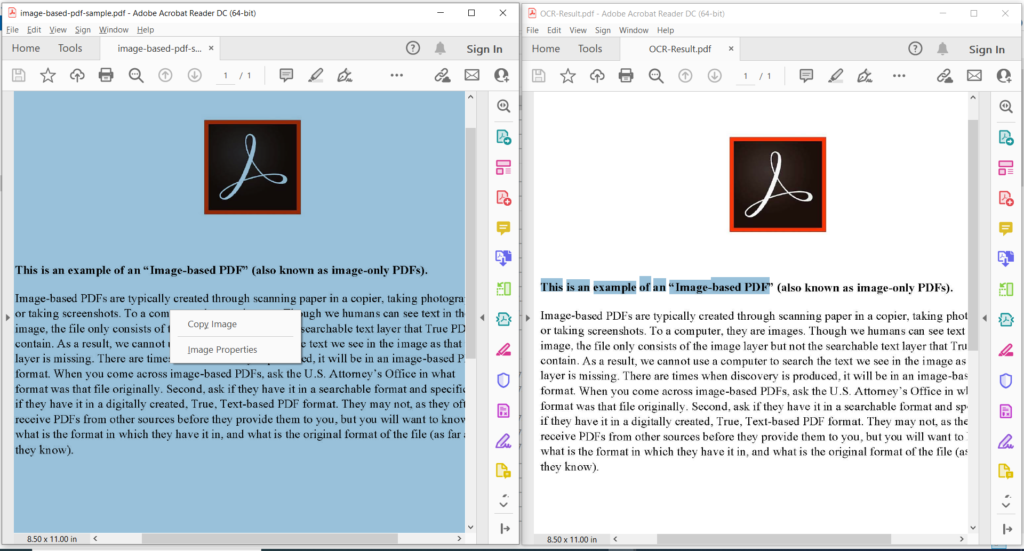
Image 3:- Preview of PDF OCR operation.
In the image above, the left portion denotes the input scanned PDF file and the portion on the right side shows a preview of the resultant text-based PDF. The sample files used in the above example can be downloaded from image-based-pdf-sample.pdf and OCR-Result.pdf.
OCR online using cURL Commands
The REST APIs can also be accessed via cURL commands and as our Cloud APIs are based on REST architecture, so we can also use the cURL command to perform PDF OCR online. However, before proceeding with conversion operation, we need to generate a JSON Web Token (JWT) based on your individual client credentials specified over Aspose.Cloud dashboard. It is mandatory because our APIs are only accessible to registered users. Please execute the following command to generate the JWT token.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=88d1cda8-b12c-4a80-b1ad-c85ac483c5c5&client_secret=406b404b2df649611e508bbcfcd2a77f" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Once we have the JWT token, please execute the following command to perform the OCR operation and save the output in the same cloud storage.
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/image-based-pdf-sample.pdf/ocr" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Conclusion
In this article, we have discussed the steps to Image PDF to Searchable PDF using Python code snippet. We have also explored the details on how to perform OCR Online using the cURL commands. As our cloud SDKs are developed under MIT license, so you may download the complete code snippet from GitHub and update it as per your requirements. We highly recommend you to explore the Developer Guide to learn more about other exciting features currently being offered by Cloud API.
In case you have any related queries or you encounter any issues while using our APIs, please feel free to contact us via the free customer support forum.
Related Articles
We also suggest going through the following articles to learn more about