
PDF filer er meget brugt over internettet til information og datadeling. De er ret populære, fordi de bevarer dokumenternes troværdighed, når de vises på enhver platform. Vi har dog ikke kontrol over kilden, og nogle filer deles i scannet format. Nogle gange tager du et billede som PDF, og senere skal du udpakke indholdet fra filen. Så en brugbar løsning er at udføre en OCR-operation og udtrække teksten. Men efter OCR-operationen, hvis du har brug for at bevare filen, så er konvertering til PDF-format en levedygtig løsning. I denne artikel vil vi diskutere trinene til, hvordan man konverterer en scannet PDF til tekst PDF ved hjælp af Python.
OCR PDF API
Aspose.PDF Cloud SDK for Python er en indpakning omkring Aspose.PDF Cloud. Det giver dig mulighed for at udføre alle PDF-filbehandlingsfunktioner i Python-applikationen. Manipuler PDF-filer uden Adobe Acrobat eller andre programmer. Så for at bruge SDK’et er det første trin dets installation, og det er tilgængeligt til download over PIP og GitHub repository. Udfør nu følgende kommando på terminalen/kommandoprompten for at installere den seneste version af SDK på systemet.
pip install asposepdfcloud
MS Visual Studio
Du kan også tilføje referencen direkte i dit Python-projekt i Visual Studio-projektet. Søg venligst asposepdfcloud som en pakke under Python-miljøvinduet. Følg venligst trinene nummereret på billedet nedenfor for at fuldføre installationsprocessen.
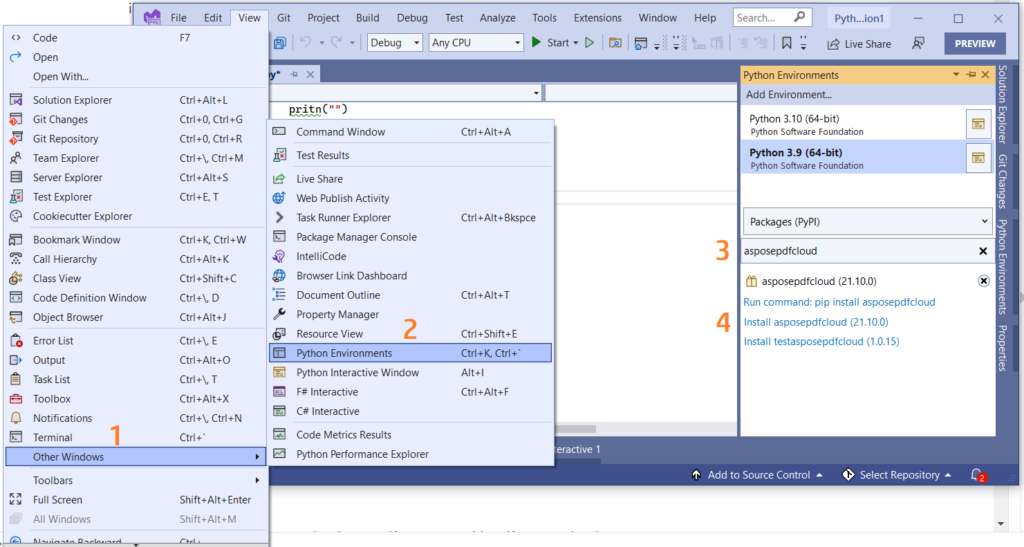
Billede 1:- Aspose.PDF Cloud SDK til Python-pakke.
Aspose.Cloud Dashboard
Da vores API’er kun er tilgængelige for autoriserede personer, så er næste skridt at oprette en konto på Aspose.Cloud dashboard. Hvis du har en GitHub- eller Google-konto, skal du blot tilmelde dig eller klikke på knappen Opret en ny konto og angive de nødvendige oplysninger. Log nu ind på dashboardet ved hjælp af legitimationsoplysninger og udvid applikationssektionen fra dashboardet, og rul ned mod sektionen Klientlegitimationsoplysninger for at se Client ID og Client Secret detaljer.
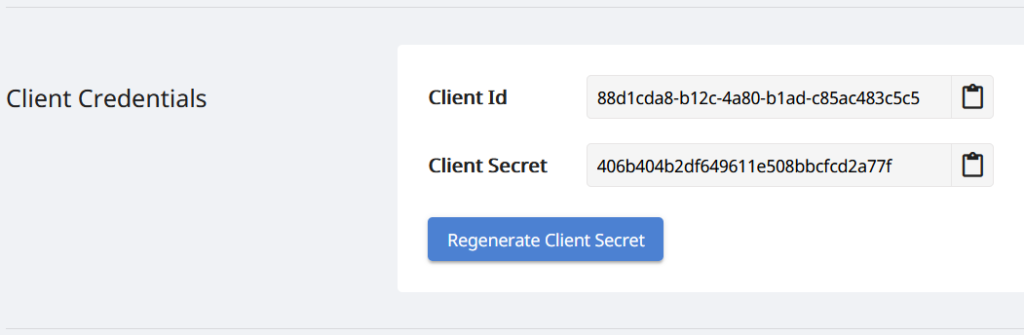
Billede 2:- Klientoplysninger på Aspose.Cloud-dashboard.
Billed-PDF til søgbar PDF i Python
Følg venligst nedenstående trin for at udføre OCR-handling på et scannet PDF-dokument og derefter gemme det som et søgbart (gør pdf søgbart). Disse trin hjælper os med at udvikle gratis online OCR ved hjælp af Python.
- Først skal vi oprette en forekomst af ApiClient-klassen, mens vi giver Client ID Client Secret som argumenter
- For det andet skal du oprette en forekomst af PdfApi-klassen, som tager ApiClient-objektet som input-argument
- Kald nu putsearchabledocument(..)-metoden for PdfApi-klassen, som tager input-PDF-navn og en valgfri parameter, der angiver sproget for OCR-motoren.
def ocrPDF():
try:
#Client credentials
client_secret = "406b404b2df649611e508bbcfcd2a77f"
client_id = "88d1cda8-b12c-4a80-b1ad-c85ac483c5c5"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# opret PdfApi-instans, mens du sender PdfApiClient som argument
pdf_api = PdfApi(pdf_api_client)
#input PDF file name
input_file = 'image-based-pdf-sample.pdf'
# kalde API'et for at udføre OCR-operation og gemme output i skylager
response = pdf_api.put_searchable_document(name=input_file,lang='eng')
# udskriv besked i konsollen (valgfrit)
print('Image PDF successfully converted to Text PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
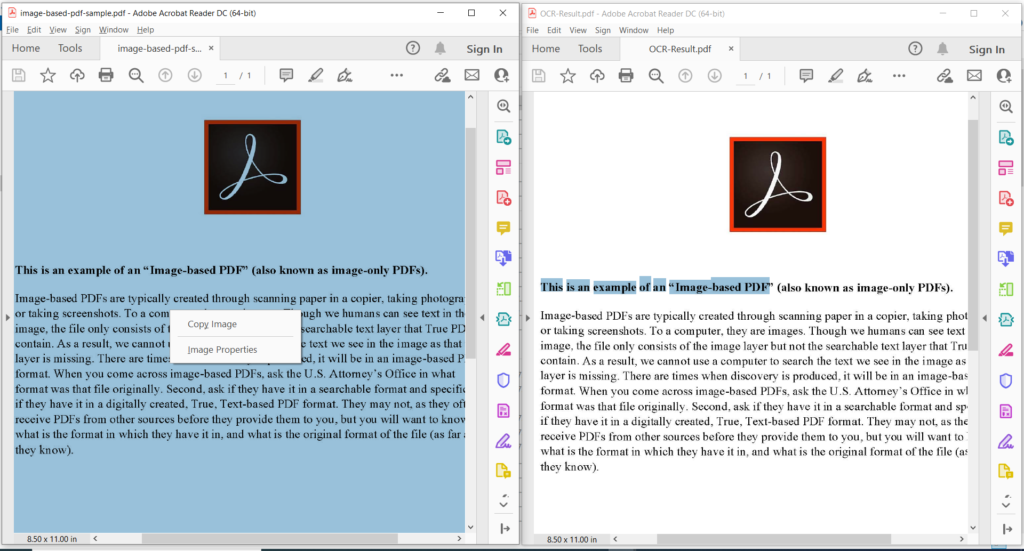
Billede 3:- Forhåndsvisning af PDF OCR-drift.
På billedet ovenfor angiver den venstre del den indlæste scannede PDF-fil, og delen på højre side viser en forhåndsvisning af den resulterende tekstbaserede PDF. Eksempelfilerne brugt i ovenstående eksempel kan downloades fra image-based-pdf-sample.pdf og OCR-Result.pdf.
OCR online ved hjælp af cURL-kommandoer
REST API’erne kan også tilgås via cURL-kommandoer, og da vores Cloud API’er er baseret på REST-arkitektur, så kan vi også bruge cURL-kommandoen til at udføre PDF OCR online. Men før vi fortsætter med konverteringsoperationen, skal vi generere et JSON Web Token (JWT) baseret på dine individuelle klientoplysninger angivet over Aspose.Cloud dashboard. Det er obligatorisk, fordi vores API’er kun er tilgængelige for registrerede brugere. Udfør venligst følgende kommando for at generere JWT-tokenet.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=88d1cda8-b12c-4a80-b1ad-c85ac483c5c5&client_secret=406b404b2df649611e508bbcfcd2a77f" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Når vi har JWT-tokenet, skal du udføre følgende kommando for at udføre OCR-operationen og gemme outputtet i det samme skylager.
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/image-based-pdf-sample.pdf/ocr" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Konklusion
I denne artikel har vi diskuteret trinene til billed-PDF til søgbar PDF ved hjælp af Python-kodestykket. Vi har også undersøgt detaljerne om, hvordan man udfører OCR online ved hjælp af cURL-kommandoer. Da vores cloud-SDK’er er udviklet under MIT-licens, kan du downloade det komplette kodestykke fra GitHub og opdatere det i henhold til dine krav. Vi anbefaler dig stærkt at udforske Udviklervejledningen for at lære mere om andre spændende funktioner, der i øjeblikket tilbydes af Cloud API.
Hvis du har relaterede spørgsmål, eller du støder på problemer, mens du bruger vores API’er, er du velkommen til at kontakte os via gratis kundesupportforum.
relaterede artikler
Vi foreslår også, at du går gennem de følgende artikler for at lære mere om