
Các tệp PDF được sử dụng rộng rãi trên internet để chia sẻ thông tin và dữ liệu. Chúng khá phổ biến vì chúng duy trì độ trung thực của tài liệu khi xem trên bất kỳ nền tảng nào. Tuy nhiên, chúng tôi không có quyền kiểm soát nguồn và một số tệp được chia sẻ ở định dạng được quét. Đôi khi bạn chụp ảnh dưới dạng PDF và sau đó bạn cần trích xuất nội dung từ tệp. Vì vậy, một giải pháp khả thi là thực hiện thao tác OCR và trích xuất văn bản. Tuy nhiên, sau thao tác OCR, nếu bạn cần bảo toàn tệp thì chuyển đổi sang định dạng PDF là một giải pháp khả thi. Trong bài viết này, chúng ta sẽ thảo luận về các bước về cách chuyển đổi PDF được quét thành PDF văn bản bằng Python.
API OCR PDF
Aspose.PDF Cloud SDK for Python là một trình bao bọc xung quanh Aspose.PDF Cloud. Nó cho phép bạn thực hiện tất cả các khả năng xử lý tệp PDF trong ứng dụng Python. Thao tác với các tệp PDF mà không cần Adobe Acrobat hoặc bất kỳ ứng dụng nào khác. Vì vậy, để sử dụng SDK, bước đầu tiên là cài đặt SDK và SDK có sẵn để tải xuống qua kho lưu trữ PIP và GitHub. Bây giờ hãy thực hiện lệnh sau trên dấu nhắc lệnh/thiết bị đầu cuối để cài đặt phiên bản SDK mới nhất trên hệ thống.
pip install asposepdfcloud
MS Visual Studio
Bạn cũng có thể trực tiếp thêm tham chiếu vào dự án Python của mình trong dự án Visual Studio. Vui lòng tìm kiếm asposepdfcloud dưới dạng gói trong cửa sổ môi trường Python. Vui lòng làm theo các bước được đánh số trong hình bên dưới để hoàn tất quá trình cài đặt.
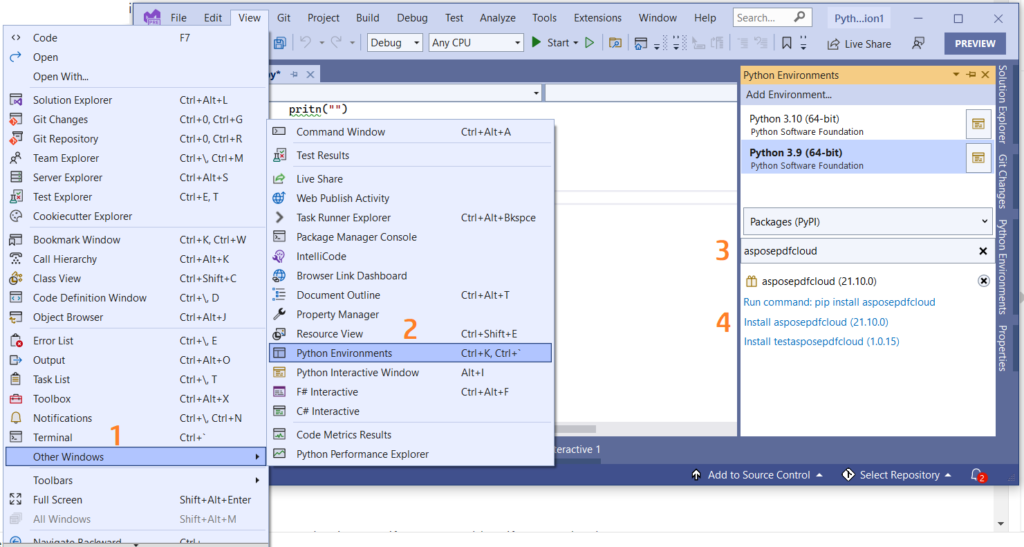
Hình ảnh 1:- Aspose.PDF Cloud SDK cho gói Python.
Bảng điều khiển Aspose.Cloud
Vì chỉ những người được ủy quyền mới có thể truy cập API của chúng tôi, nên bước tiếp theo là tạo một tài khoản trên Bảng điều khiển Aspose.Cloud. Nếu bạn có tài khoản GitHub hoặc Google, chỉ cần Đăng ký hoặc nhấp vào nút Tạo tài khoản mới và cung cấp thông tin được yêu cầu. Bây giờ, hãy đăng nhập vào bảng điều khiển bằng thông tin đăng nhập và mở rộng phần Ứng dụng từ bảng điều khiển và cuộn xuống phần Thông tin xác thực của khách hàng để xem chi tiết ID khách hàng và Bí mật khách hàng.
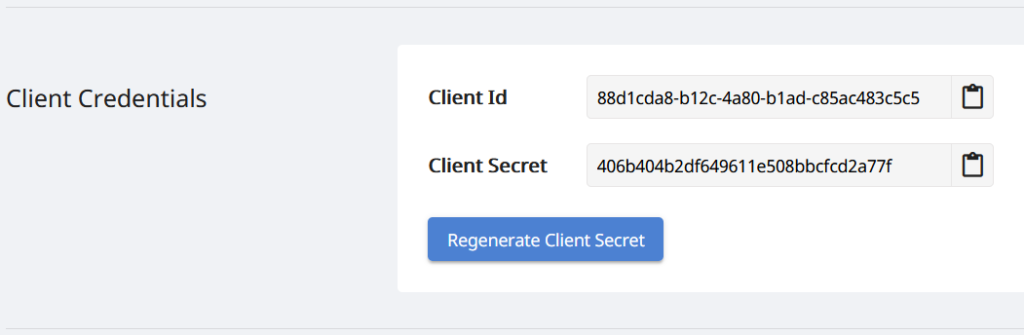
Hình ảnh 2:- Thông tin đăng nhập của khách hàng trên bảng điều khiển Aspose.Cloud.
Hình ảnh PDF sang PDF có thể tìm kiếm bằng Python
Vui lòng làm theo các bước dưới đây để thực hiện thao tác OCR trên tài liệu PDF được quét và sau đó lưu nó dưới dạng có thể tìm kiếm được (làm cho pdf có thể tìm kiếm được). Các bước này giúp chúng tôi phát triển OCR trực tuyến miễn phí bằng Python.
- Đầu tiên, chúng ta cần tạo một thể hiện của lớp ApiClient trong khi cung cấp Client ID Client Secret làm đối số
- Thứ hai, tạo một thể hiện của lớp PdfApi lấy đối tượng ApiClient làm đối số đầu vào
- Bây giờ, hãy gọi phương thức putsearchabledocument(..) của lớp PdfApi lấy tên PDF đầu vào và một tham số tùy chọn cho biết ngôn ngữ của công cụ OCR.
def ocrPDF():
try:
#Client credentials
client_secret = "406b404b2df649611e508bbcfcd2a77f"
client_id = "88d1cda8-b12c-4a80-b1ad-c85ac483c5c5"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# tạo phiên bản PdfApi trong khi chuyển PdfApiClient làm đối số
pdf_api = PdfApi(pdf_api_client)
#input PDF file name
input_file = 'image-based-pdf-sample.pdf'
# gọi API để thực hiện thao tác OCR và lưu đầu ra trong bộ nhớ đám mây
response = pdf_api.put_searchable_document(name=input_file,lang='eng')
# in tin nhắn trong bảng điều khiển (tùy chọn)
print('Image PDF successfully converted to Text PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)

Hình ảnh 3:- Xem trước thao tác PDF OCR.
Trong hình trên, phần bên trái biểu thị tệp PDF được quét đầu vào và phần ở bên phải hiển thị bản xem trước của tệp PDF dựa trên văn bản kết quả. Có thể tải xuống các tệp mẫu được sử dụng trong ví dụ trên từ image-based-pdf-sample.pdf và OCR-Result.pdf.
OCR trực tuyến bằng Lệnh cURL
API REST cũng có thể được truy cập thông qua các lệnh cURL và vì API đám mây của chúng tôi dựa trên kiến trúc REST nên chúng tôi cũng có thể sử dụng lệnh cURL để thực hiện PDF OCR trực tuyến. Tuy nhiên, trước khi tiến hành thao tác chuyển đổi, chúng tôi cần tạo Mã thông báo web JSON (JWT) dựa trên thông tin đăng nhập khách hàng cá nhân của bạn được chỉ định trên bảng điều khiển Aspose.Cloud. Điều này là bắt buộc vì API của chúng tôi chỉ có thể truy cập được đối với người dùng đã đăng ký. Vui lòng thực hiện lệnh sau để tạo mã thông báo JWT.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=88d1cda8-b12c-4a80-b1ad-c85ac483c5c5&client_secret=406b404b2df649611e508bbcfcd2a77f" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Sau khi chúng tôi có mã thông báo JWT, vui lòng thực hiện lệnh sau để thực hiện thao tác OCR và lưu đầu ra trong cùng một bộ lưu trữ đám mây.
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/image-based-pdf-sample.pdf/ocr" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Phần kết luận
Trong bài viết này, chúng ta đã thảo luận về các bước chuyển Image PDF thành PDF có thể tìm kiếm bằng cách sử dụng đoạn mã Python. Chúng tôi cũng đã khám phá chi tiết về cách thực hiện OCR Online bằng các lệnh cURL. Vì SDK đám mây của chúng tôi được phát triển theo giấy phép MIT, nên bạn có thể tải xuống đoạn mã hoàn chỉnh từ GitHub và cập nhật đoạn mã theo yêu cầu của mình. Chúng tôi thực sự khuyên bạn nên khám phá Hướng dẫn dành cho nhà phát triển để tìm hiểu thêm về các tính năng thú vị khác hiện đang được Cloud API cung cấp.
Trong trường hợp bạn có bất kỳ thắc mắc nào liên quan hoặc bạn gặp phải bất kỳ sự cố nào khi sử dụng API của chúng tôi, vui lòng liên hệ với chúng tôi qua diễn đàn hỗ trợ khách hàng miễn phí.
Những bài viết liên quan
Chúng tôi cũng khuyên bạn nên xem qua các bài viết sau để tìm hiểu thêm về