
PDF faili tiek plaši izmantoti internetā informācijas un datu koplietošanai. Tie ir diezgan populāri, jo saglabā dokumentu uzticamību, skatoties jebkurā platformā. Tomēr mēs nevaram kontrolēt avotu, un daži faili tiek koplietoti skenētā formātā. Dažreiz jūs uzņemat attēlu kā PDF, un vēlāk jums ir jāizņem saturs no faila. Tāpēc dzīvotspējīgs risinājums ir veikt OCR darbību un izvilkt tekstu. Tomēr pēc OCR operācijas, ja jums ir jāsaglabā fails, pārveidošana PDF formātā ir dzīvotspējīgs risinājums. Šajā rakstā mēs apspriedīsim darbības, kā pārveidot skenētu PDF failu par teksta PDF, izmantojot Python.
- OCR PDF API
- Attēls no PDF uz meklējamu PDF programmā Python
- OCR tiešsaistē, izmantojot cURL komandas
OCR PDF API
Aspose.PDF Cloud SDK for Python ir iesaiņojums ap Aspose.PDF Cloud. Tas ļauj veikt visas PDF failu apstrādes iespējas Python lietojumprogrammā. Manipulējiet ar PDF failiem bez Adobe Acrobat vai citas lietojumprogrammas. Tātad, lai izmantotu SDK, pirmais solis ir tā instalēšana, un tas ir pieejams lejupielādei, izmantojot PIP un GitHub repozitoriju. Tagad terminālī/komandu uzvednē izpildiet šo komandu, lai sistēmā instalētu jaunāko SDK versiju.
pip install asposepdfcloud
MS Visual Studio
Varat arī tieši pievienot atsauci savā Python projektā Visual Studio projektā. Lūdzu, meklējiet asposepdfcloud kā pakotni zem Python vides loga. Lai pabeigtu instalēšanas procesu, lūdzu, veiciet tālāk redzamajā attēlā norādītās darbības.
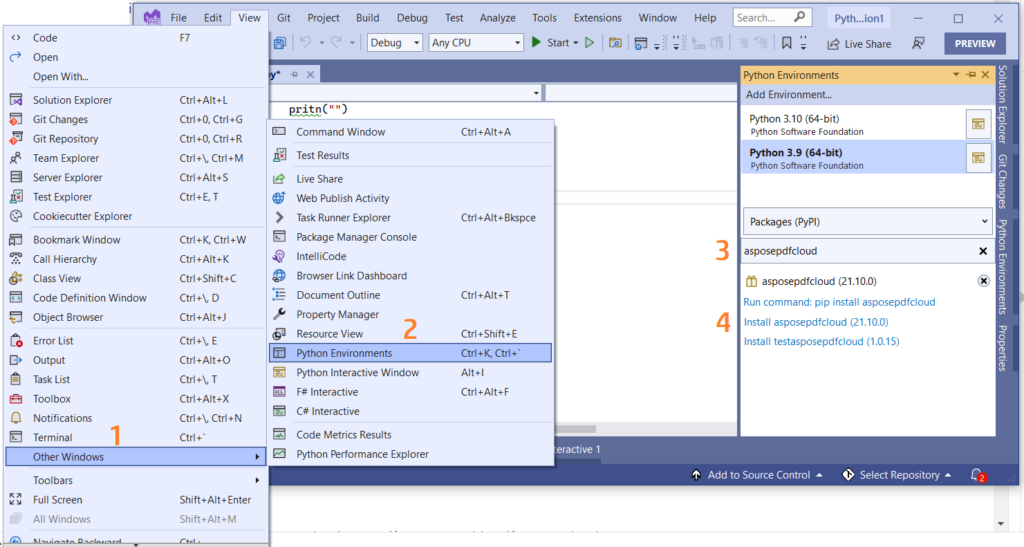
- attēls: Aspose.PDF Cloud SDK Python pakotnei.
Aspose.Cloud Dashboard
Tā kā mūsu API ir pieejamas tikai pilnvarotām personām, nākamais solis ir izveidot kontu vietnē Aspose.Cloud dashboard. Ja jums ir GitHub vai Google konts, vienkārši reģistrējieties vai noklikšķiniet uz pogas Izveidot jaunu kontu un sniedziet nepieciešamo informāciju. Tagad piesakieties informācijas panelī, izmantojot akreditācijas datus, un no informācijas paneļa izvērsiet sadaļu Lietojumprogrammas un ritiniet uz leju līdz sadaļai Klienta akreditācijas dati, lai skatītu informāciju par klienta ID un klienta noslēpumu.

- attēls: klienta akreditācijas dati Aspose.Cloud informācijas panelī.
Attēls no PDF uz meklējamu PDF programmā Python
Lūdzu, izpildiet tālāk norādītās darbības, lai veiktu OCR darbību skenētajam PDF dokumentam un pēc tam saglabājiet to kā meklējamu (padariet pdf meklējamu). Šīs darbības palīdz mums izstrādāt bezmaksas tiešsaistes OCR, izmantojot Python.
- Pirmkārt, mums ir jāizveido ApiClient klases gadījums, vienlaikus nodrošinot klienta ID klienta noslēpumu kā argumentus.
- Otrkārt, izveidojiet PdfApi klases gadījumu, kas izmanto ApiClient objektu kā ievades argumentu
- Tagad izsauciet PdfApi klases metodi putsearchabledocument(..), kas ņem ievades PDF nosaukumu un izvēles parametru, kas norāda OCR dzinēja valodu.
def ocrPDF():
try:
#Client credentials
client_secret = "406b404b2df649611e508bbcfcd2a77f"
client_id = "88d1cda8-b12c-4a80-b1ad-c85ac483c5c5"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# izveidot PdfApi instanci, vienlaikus nododot PdfApiClient kā argumentu
pdf_api = PdfApi(pdf_api_client)
#input PDF file name
input_file = 'image-based-pdf-sample.pdf'
# izsauciet API, lai veiktu OCR darbību un saglabātu izvadi mākoņkrātuvē
response = pdf_api.put_searchable_document(name=input_file,lang='eng')
# drukāt ziņojumu konsolē (pēc izvēles)
print('Image PDF successfully converted to Text PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
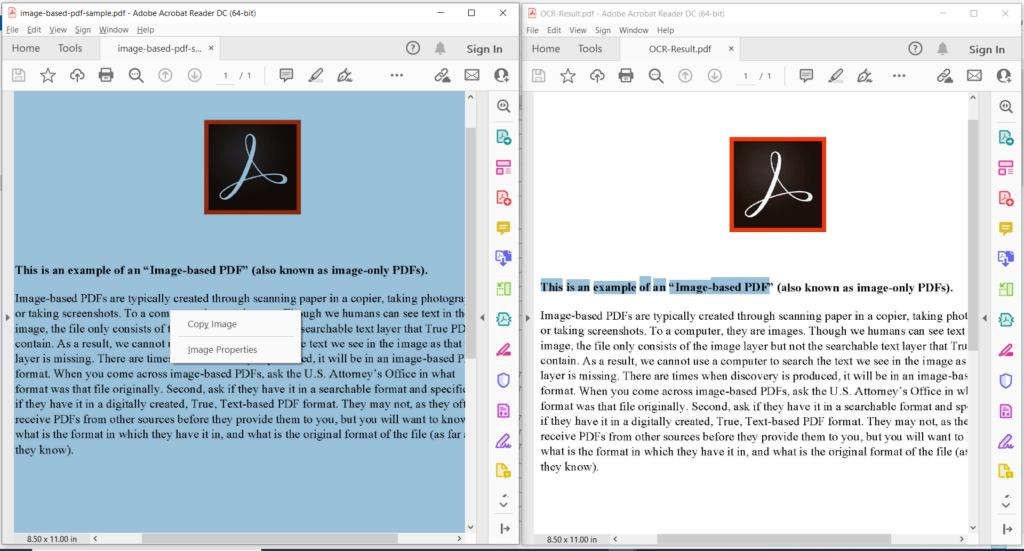
- attēls: PDF OCR darbības priekšskatījums.
Iepriekš redzamajā attēlā kreisā daļa apzīmē ievades skenēto PDF failu, bet labajā pusē redzams iegūtā teksta PDF priekšskatījums. Iepriekš minētajā piemērā izmantotos failu paraugus var lejupielādēt no image-based-pdf-sample.pdf un OCR-Result.pdf.
OCR tiešsaistē, izmantojot cURL komandas
REST API var piekļūt arī, izmantojot cURL komandas, un tā kā mūsu mākoņa API ir balstītas uz REST arhitektūru, mēs varam arī izmantot cURL komandu, lai tiešsaistē veiktu PDF OCR. Tomēr, pirms turpināt konvertēšanas darbību, mums ir jāģenerē JSON Web Token (JWT), pamatojoties uz jūsu individuālajiem klienta akreditācijas datiem, kas norādīti Aspose.Cloud informācijas panelī. Tas ir obligāti, jo mūsu API ir pieejamas tikai reģistrētiem lietotājiem. Lūdzu, izpildiet šo komandu, lai ģenerētu JWT marķieri.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=88d1cda8-b12c-4a80-b1ad-c85ac483c5c5&client_secret=406b404b2df649611e508bbcfcd2a77f" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Kad esam ieguvuši JWT marķieri, lūdzu, izpildiet šo komandu, lai veiktu OCR darbību un saglabātu izvadi tajā pašā mākoņkrātuvē.
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/image-based-pdf-sample.pdf/ocr" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Secinājums
Šajā rakstā mēs esam apsprieduši darbības, kas jāveic, lai attēlu PDF formātā izveidotu meklējamu PDF failu, izmantojot Python koda fragmentu. Mēs esam arī izpētījuši detalizētu informāciju par to, kā veikt OCR tiešsaistē, izmantojot cURL komandas. Tā kā mūsu mākoņa SDK ir izstrādāti saskaņā ar MIT licenci, varat lejupielādēt visu koda fragmentu no GitHub un atjaunināt to atbilstoši savām prasībām. Mēs ļoti iesakām izpētīt izstrādātāja rokasgrāmatu, lai uzzinātu vairāk par citām aizraujošām funkcijām, ko pašlaik piedāvā Cloud API.
Ja jums ir kādi saistīti jautājumi vai rodas problēmas, izmantojot mūsu API, lūdzu, sazinieties ar mums, izmantojot bezmaksas klientu atbalsta forumu.
Saistītie raksti
Mēs arī iesakām izlasīt tālāk norādītos rakstus, lai uzzinātu vairāk par