
PDF ファイルは、情報とデータ共有のためにインターネット上で広く使用されています。どのプラットフォームで表示してもドキュメントの忠実度が維持されるため、非常に人気があります。ただし、ソースを制御することはできず、一部のファイルはスキャンされた形式で共有されます。画像を PDF としてキャプチャし、後でファイルからコンテンツを抽出する必要がある場合があります。したがって、実行可能な解決策は、OCR 操作を実行してテキストを抽出することです。ただし、OCR 操作の後、ファイルを保持する必要がある場合は、PDF 形式への変換が実行可能なソリューションです。この記事では、Python を使用してスキャンした PDF をテキスト PDF に変換する手順について説明します。
OCR PDF API
Aspose.PDF Cloud SDK for Python は Aspose.PDF Cloud のラッパーです。これにより、Python アプリケーション内ですべての PDF ファイル処理機能を実行できます。 Adobe Acrobat やその他のアプリケーションを使用せずに PDF ファイルを操作します。したがって、SDK を使用するための最初のステップはそのインストールであり、PIP および GitHub リポジトリからダウンロードできます。ターミナル/コマンド プロンプトで次のコマンドを実行して、システムに最新バージョンの SDK をインストールします。
pip install asposepdfcloud
MS ビジュアル スタジオ
Visual Studio プロジェクト内の Python プロジェクトに参照を直接追加することもできます。 Python 環境ウィンドウで asposepdfcloud をパッケージとして検索してください。インストールプロセスを完了するには、下の画像に番号が付けられた手順に従ってください。
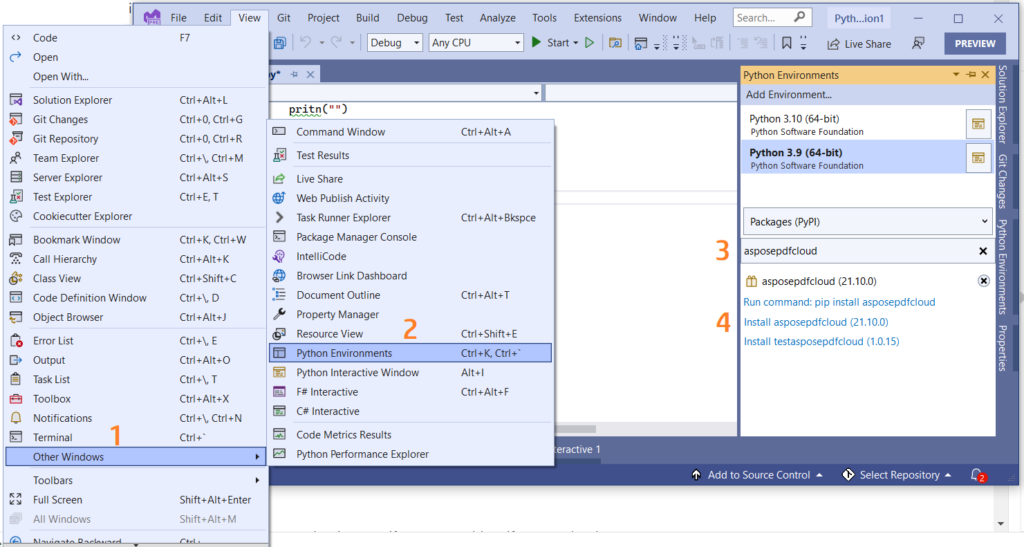
画像 1:- Aspose.PDF Cloud SDK for Python パッケージ。
Aspose.Cloud ダッシュボード
私たちの API は許可された人のみがアクセスできるため、次のステップは Aspose.Cloud ダッシュボード でアカウントを作成することです。 GitHub または Google アカウントをお持ちの場合は、サインアップするか、Create a new Account ボタンをクリックして必要な情報を入力してください。資格情報を使用してダッシュボードにログインし、ダッシュボードから [アプリケーション] セクションを展開し、[クライアント資格情報] セクションまで下にスクロールして、クライアント ID とクライアント シークレットの詳細を表示します。
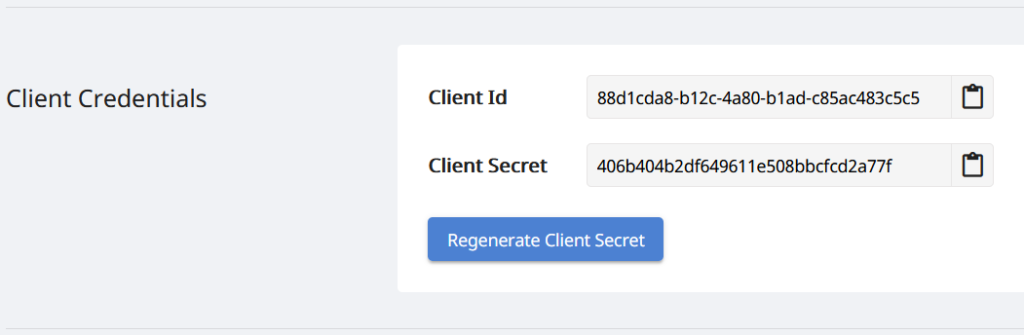
画像 2:- Aspose.Cloud ダッシュボードのクライアント資格情報。
Pythonで画像PDFから検索可能なPDFへ
以下の手順に従って、スキャンした PDF ドキュメントに対して OCR 操作を実行し、検索可能として保存します (PDF を検索可能にします)。これらの手順は、Python を使用して無料のオンライン OCR を開発するのに役立ちます。
- まず、Client ID Client Secret を引数として提供しながら、ApiClient クラスのインスタンスを作成する必要があります。
- 次に、ApiClient オブジェクトを入力引数として受け取る PdfApi クラスのインスタンスを作成します。
- ここで、入力 PDF 名と OCR エンジンの言語を示すオプションのパラメーターを受け取る PdfApi クラスの putsearchabledocument(..) メソッドを呼び出します。
def ocrPDF():
try:
#Client credentials
client_secret = "406b404b2df649611e508bbcfcd2a77f"
client_id = "88d1cda8-b12c-4a80-b1ad-c85ac483c5c5"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# 引数として PdfApiClient を渡しながら PdfApi インスタンスを作成する
pdf_api = PdfApi(pdf_api_client)
#input PDF file name
input_file = 'image-based-pdf-sample.pdf'
# API を呼び出して OCR 操作を実行し、出力をクラウド ストレージに保存する
response = pdf_api.put_searchable_document(name=input_file,lang='eng')
# コンソールにメッセージを表示 (オプション)
print('Image PDF successfully converted to Text PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
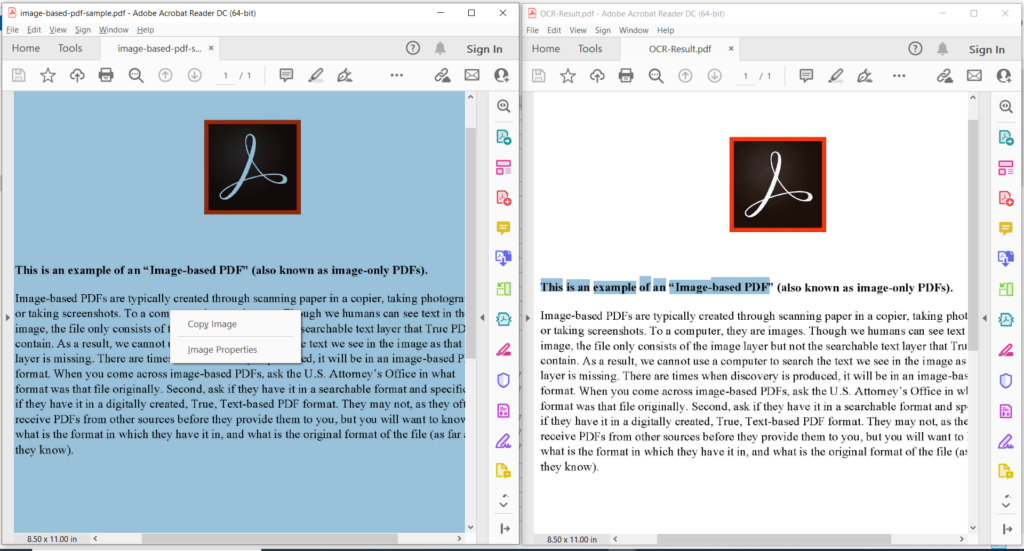
画像 3:- PDF OCR 操作のプレビュー。
上の画像では、左側の部分は入力されたスキャン PDF ファイルを示し、右側の部分は結果のテキストベースの PDF のプレビューを示しています。上記の例で使用されているサンプル ファイルは、image-based-pdf-sample.pdf および OCR-Result.pdf からダウンロードできます。
cURL コマンドを使用した OCR オンライン
REST API には cURL コマンドを介してアクセスすることもできます。クラウド API は REST アーキテクチャに基づいているため、cURL コマンドを使用してオンラインで PDF OCR を実行することもできます。ただし、変換操作に進む前に、Aspose.Cloud ダッシュボードで指定された個々のクライアント資格情報に基づいて JSON Web トークン (JWT) を生成する必要があります。 API は登録ユーザーのみがアクセスできるため、これは必須です。以下のコマンドを実行して JWT トークンを生成してください。
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=88d1cda8-b12c-4a80-b1ad-c85ac483c5c5&client_secret=406b404b2df649611e508bbcfcd2a77f" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
JWT トークンを取得したら、次のコマンドを実行して OCR 操作を実行し、出力を同じクラウド ストレージに保存してください。
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/image-based-pdf-sample.pdf/ocr" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
結論
この記事では、Python コード スニペットを使用して画像 PDF を検索可能な PDF にする手順について説明しました。また、cURL コマンドを使用して OCR オンラインを実行する方法についても詳しく説明しました。当社のクラウド SDK は MIT ライセンスの下で開発されているため、GitHub から完全なコード スニペットをダウンロードして、要件に従って更新することができます。 デベロッパー ガイド を調べて、Cloud API で現在提供されているその他の興味深い機能について詳しく知ることを強くお勧めします。
関連する質問がある場合、または API の使用中に問題が発生した場合は、無料のカスタマー サポート フォーラム からお気軽にお問い合わせください。
関連記事
また、次の記事を読んで詳細を確認することをお勧めします。