
PDF-filer används ofta över internet för information och datadelning. De är ganska populära eftersom de bibehåller dokumentens trohet när de visas på vilken plattform som helst. Vi har dock inte kontroll över källan och vissa filer delas i skannat format. Ibland tar du en bild som PDF och senare behöver du extrahera innehållet från filen. Så en gångbar lösning är att utföra en OCR-operation och extrahera texten. Men efter OCR-operationen, om du behöver bevara filen, är konvertering till PDF-format en hållbar lösning. I den här artikeln kommer vi att diskutera stegen för hur man konverterar en skannad PDF till Text PDF med Python.
OCR PDF API
Aspose.PDF Cloud SDK för Python är ett omslag runt Aspose.PDF Cloud. Det gör att du kan utföra alla funktioner för bearbetning av PDF-filer i Python-applikationen. Manipulera PDF-filer utan Adobe Acrobat eller något annat program. Så för att kunna använda SDK, är det första steget dess installation, och det är tillgängligt för nedladdning över PIP och GitHub repository. Kör nu följande kommando på terminalen/kommandotolken för att installera den senaste versionen av SDK på systemet.
pip install asposepdfcloud
MS Visual Studio
Du kan också direkt lägga till referensen i ditt Python-projekt i Visual Studio-projektet. Sök efter asposepdfcloud som ett paket under Python-miljöfönstret. Följ stegen numrerade i bilden nedan för att slutföra installationsprocessen.
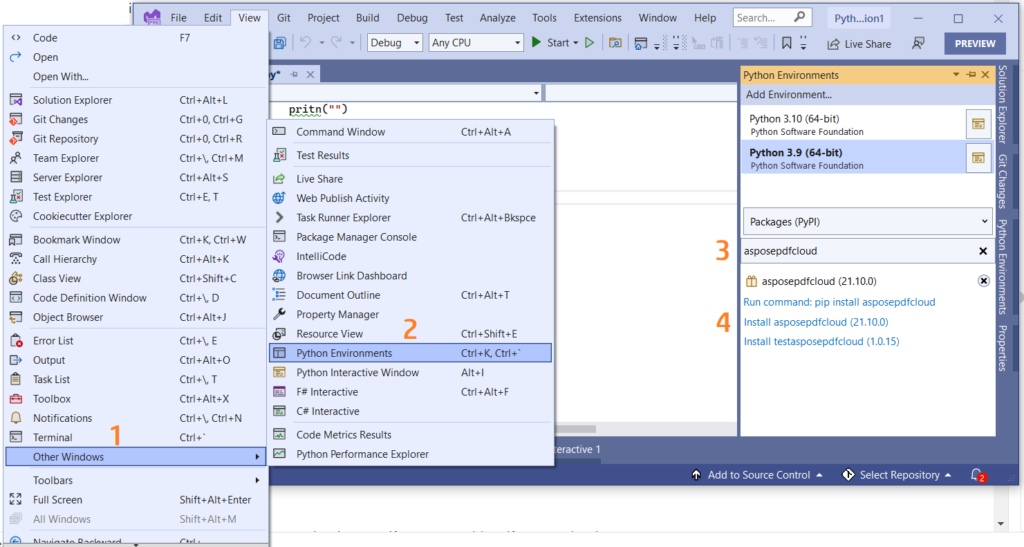
Bild 1:- Aspose.PDF Cloud SDK för Python-paket.
Aspose.Cloud Dashboard
Eftersom våra API:er endast är tillgängliga för behöriga personer, så nästa steg är att skapa ett konto på Aspose.Cloud dashboard. Om du har ett GitHub- eller Google-konto, registrera dig eller klicka på knappen Skapa ett nytt konto och ange den information som krävs. Logga nu in på instrumentpanelen med hjälp av autentiseringsuppgifter och expandera avsnittet Applikationer från instrumentpanelen och scrolla ner till avsnittet Klientuppgifter för att se klient-ID och klienthemlighetsdetaljer.
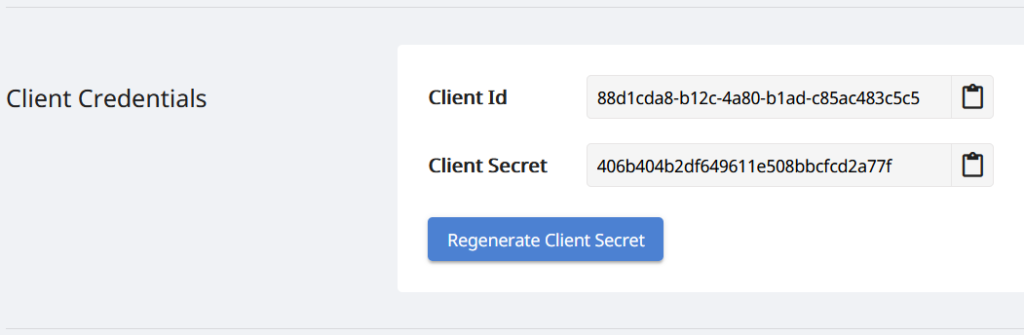
Bild 2:- Klientuppgifter på Aspose.Cloud-instrumentpanelen.
Bild PDF till sökbar PDF i Python
Följ stegen nedan för att utföra OCR-operation på ett skannat PDF-dokument och spara det sedan som ett sökbart (gör pdf-filen sökbar). Dessa steg hjälper oss att utveckla gratis OCR online med Python.
- Först måste vi skapa en instans av ApiClient-klassen samtidigt som vi tillhandahåller Client ID Client Secret som argument
- För det andra, skapa en instans av klassen PdfApi som tar ApiClient-objektet som inmatningsargument
- Anropa nu metoden putsearchabledocument(..) för PdfApi-klassen som tar in PDF-namn och en valfri parameter som anger språket för OCR-motorn.
def ocrPDF():
try:
#Client credentials
client_secret = "406b404b2df649611e508bbcfcd2a77f"
client_id = "88d1cda8-b12c-4a80-b1ad-c85ac483c5c5"
#initialize PdfApi client instance using client credetials
pdf_api_client = asposepdfcloud.api_client.ApiClient(client_secret, client_id)
# skapa PdfApi-instanser samtidigt som du skickar PdfApiClient som argument
pdf_api = PdfApi(pdf_api_client)
#input PDF file name
input_file = 'image-based-pdf-sample.pdf'
# anropa API:et för att utföra OCR-operation och spara utdata i molnlagring
response = pdf_api.put_searchable_document(name=input_file,lang='eng')
# skriv ut meddelande i konsolen (valfritt)
print('Image PDF successfully converted to Text PDF !')
except ApiException as e:
print("Exception while calling PdfApi: {0}".format(e))
print("Code:" + str(e.code))
print("Message:" + e.message)
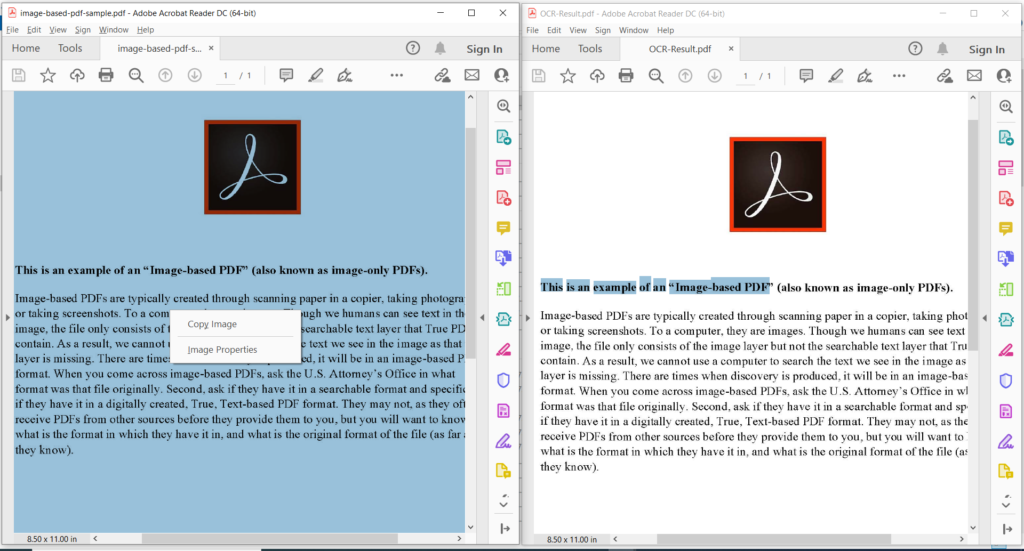
Bild 3:- Förhandsvisning av PDF OCR-operation.
I bilden ovan anger den vänstra delen den inskannade PDF-filen och delen till höger visar en förhandsvisning av den resulterande textbaserade PDF-filen. Exempelfilerna som används i exemplet ovan kan laddas ner från image-based-pdf-sample.pdf och OCR-Result.pdf.
OCR online med hjälp av cURL-kommandon
REST API:erna kan också nås via cURL-kommandon och eftersom våra Cloud API:er är baserade på REST-arkitektur, så kan vi också använda cURL-kommandot för att utföra PDF OCR online. Innan vi fortsätter med konverteringsoperationen måste vi dock generera en JSON Web Token (JWT) baserat på dina individuella klientuppgifter som specificeras över Aspose.Cloud-instrumentpanelen. Det är obligatoriskt eftersom våra API:er endast är tillgängliga för registrerade användare. Vänligen kör följande kommando för att generera JWT-token.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=88d1cda8-b12c-4a80-b1ad-c85ac483c5c5&client_secret=406b404b2df649611e508bbcfcd2a77f" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
När vi har JWT-token, vänligen kör följande kommando för att utföra OCR-operationen och spara utdata i samma molnlagring.
curl -v -X PUT "https://api.aspose.cloud/v3.0/pdf/image-based-pdf-sample.pdf/ocr" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Slutsats
I den här artikeln har vi diskuterat stegen för att avbilda PDF till sökbar PDF med Python-kodavsnitt. Vi har också utforskat detaljerna om hur man utför OCR Online med hjälp av cURL-kommandona. Eftersom våra moln-SDK:er är utvecklade under MIT-licens, så kan du ladda ner hela kodavsnittet från GitHub och uppdatera det enligt dina krav. Vi rekommenderar starkt att du utforskar Developer Guide för att lära dig mer om andra spännande funktioner som för närvarande erbjuds av Cloud API.
Om du har några relaterade frågor eller om du stöter på några problem när du använder våra API:er är du välkommen att kontakta oss via gratis kundsupportforum.
relaterade artiklar
Vi föreslår också att du går igenom följande artiklar för att lära dig mer om