
Bild-PDF in durchsuchbares PDF konvertieren
In der heutigen datengesteuerten Welt sind PDFs zu einem unverzichtbaren Format zum Speichern und Teilen von Dokumenten geworden. Allerdings sind nicht alle PDFs leicht durchsuchbar oder bearbeitbar, insbesondere diejenigen, die bildbasiert sind. Beim Umgang mit Dokumenten ist es wirklich schwierig, Textinformationen zur weiteren Bearbeitung zu kopieren/extrahieren. Glücklicherweise können Sie mit der leistungsstarken OCR-Technologie (Optical Character Recognition) Bild-PDFs ganz einfach in durchsuchbare PDFs konvertieren. In diesem technischen Blog werden wir untersuchen, wie OCR-PDF mithilfe verschiedener Techniken in durchsuchbare PDF konvertiert werden kann, mit besonderem Schwerpunkt auf der REST-API. Wir werden auch besprechen, wie Sie Text aus OCR-PDFs extrahieren, und Ihnen ein umfassendes Verständnis dafür vermitteln, wie Sie die OCR-Technologie nutzen können, um das volle Potenzial Ihrer PDF-Dokumente auszuschöpfen.
- OCR-PDF mit Java SDK
- Gescanntes PDF in durchsuchbares PDF mit Java umwandeln
- OCR Online mit cURL-Befehlen
OCR-PDF mit Java SDK
Aspose.PDF Cloud SDK for Java ist eine leistungsstarke Cloud-basierte API, die eine breite Palette von Funktionen und Möglichkeiten für die Arbeit mit PDF-Dokumenten bietet. Eine der wichtigsten Funktionen ist die Möglichkeit, OCR auf PDFs durchzuführen, was den Prozess des Extrahierens von Text aus bildbasierten PDFs und das Erstellen durchsuchbarer PDFs erheblich vereinfachen kann. Mit seiner benutzerfreundlichen Oberfläche und umfassenden Dokumentation erleichtert dieses SDK die Automatisierung des OCR-Prozesses für PDFs, wodurch Zeit gespart und die Produktivität gesteigert wird.
Darüber hinaus ist diese Cloud-basierte API für eine Vielzahl von Eingabeformaten ausgelegt und kann sogar handgeschriebenen Text erkennen, was sie zu einer ausgezeichneten Wahl für Unternehmen und Entwickler macht, die ihren Dokumenten-Workflow optimieren möchten. Der erste Schritt besteht nun darin, seine Referenz im Java-Projekt hinzuzufügen, indem die folgenden Details in pom.xml des Maven-Build-Projekts hinzugefügt werden.
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>https://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
Wenn Sie noch kein Konto haben, müssen Sie ein kostenloses Konto über Aspose Cloud erstellen. Melden Sie sich mit dem neu erstellten Konto an und suchen/erstellen Sie die Client-ID und das Client-Geheimnis unter Cloud Dashboard. Diese Angaben sind in den nachfolgenden Abschnitten erforderlich.
Gescanntes PDF in durchsuchbares PDF mit Java umwandeln
In diesem Abschnitt wird ausführlich erläutert, wie Sie gescannte PDF-Dateien mithilfe von Java-Code-Snippets in durchsuchbare PDF-Dateien konvertieren. Bitte beachten Sie, dass das Java Cloud SDK die Erkennung der folgenden Sprachen unterstützt: eng, ara, bel, ben, bul, ces, dan, deu, ell, fin, fra, heb, hin, ind, isl, ita, jpn, kor, nld , nor, pol, por, ron, rus, spa, swe, tha, tur, ukr, vie, chisim, chitra oder deren Kombination, zB eng,rus.
- Zuerst müssen wir ein PdfApi-Objekt erstellen, in dem wir ClientID- und Client-Secret-Details als Argumente übergeben
- Erstellen Sie zweitens eine Instanz der Dateiklasse, um das Bild-PDF zu laden
- Rufen Sie drittens die Methode uploadFile(…) auf, um das Eingabe-PDF in den Cloud-Speicher hochzuladen
- Da unser Bild-PDF englischen Text enthält, müssen wir ein String-Objekt mit dem Wert „eng“ erstellen.
- Rufen Sie abschließend die Methode putSearchableDocument(…) auf, die als Argumente ein Eingabe-PDF und einen Sprachcode benötigt.
Sobald der Code erfolgreich ausgeführt wurde, wird das durchsuchbare PDF im Cloud-Speicher gespeichert
try
{
// Holen Sie sich ClientID und ClientSecret von https://dashboard.aspose.cloud/
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// createPdfApi-Instanz
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// Eingabebild PDF-Dokument
String name = "ScannedPDF.pdf";
// Laden Sie die Datei vom lokalen System
File file = new File(name);
// Laden Sie die Datei in den Cloud-Speicher hoch
FilesUploadResult uploadResponse = pdfApi.uploadFile(name, file, null);
// die im Bild-PDF verwendeten Sprachen
String lang = "eng";
// Führen Sie die OCR für das Bild-PDF-Dokument durch
AsposeResponse response = pdfApi.putSearchableDocument(name, null, null, lang);
// Erfolgsmeldung drucken
System.out.println("OCR PDF successfull !");
}catch(Exception ex)
{
System.out.println(ex.getMessage());
}
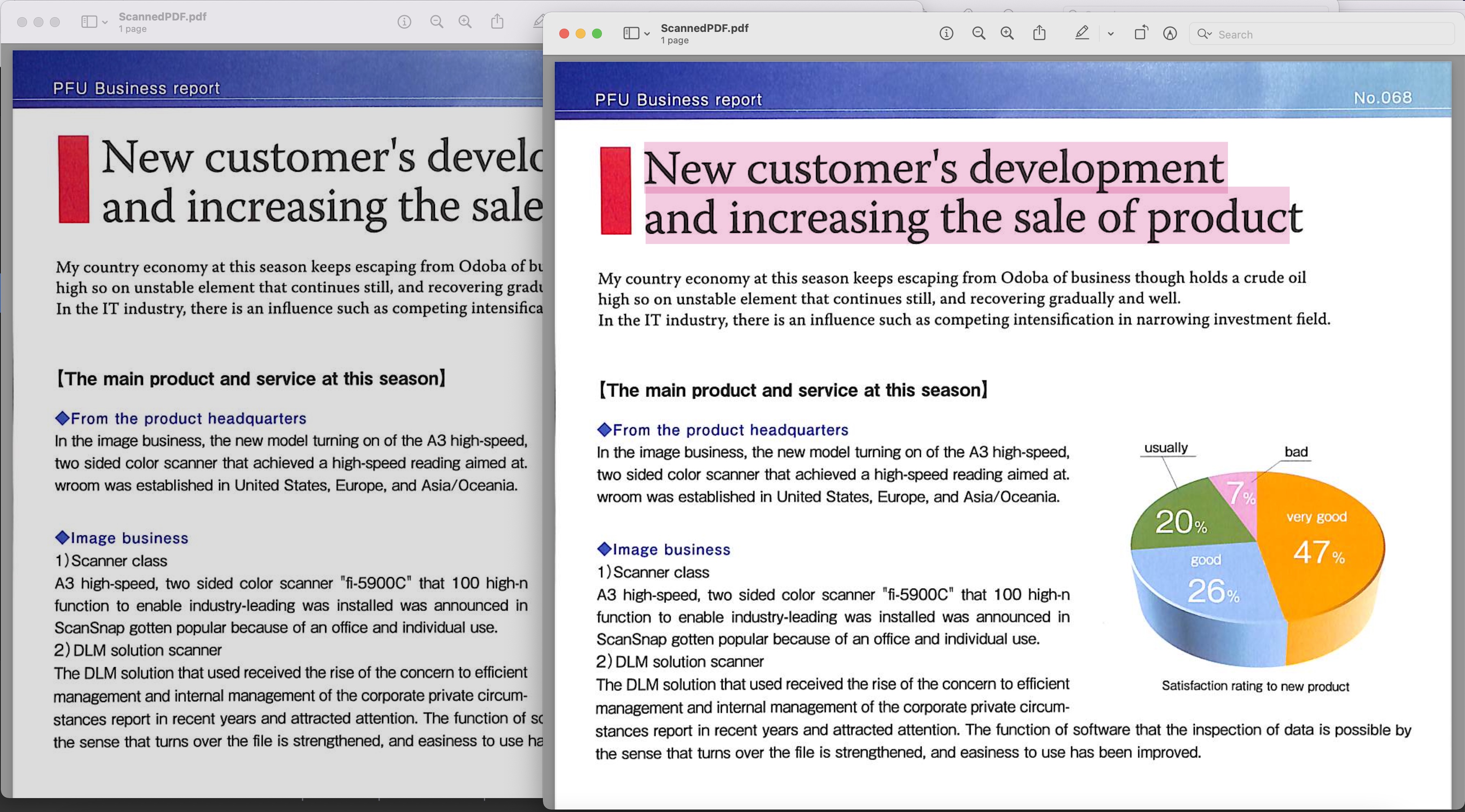
Image1:- Durchsuchbare PDF-Vorschau
Das im obigen Beispiel verwendete gescannte PDF kann von BusinessReport.pdf und das resultierende durchsuchbare PDF von Converted.pdf heruntergeladen werden.
OCR Online mit cURL-Befehlen
Die cURL-Befehle sind einer der bequemen Ansätze zum Aufrufen der REST-APIs. In diesem Abschnitt werden wir also die cURL-Befehle für OCR online verwenden. Als Voraussetzung müssen wir nun zunächst ein JWT-Zugriffstoken (basierend auf Client-Anmeldeinformationen) generieren, während wir den folgenden Befehl ausführen.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Sobald wir das JWT-Token haben, führen Sie bitte den folgenden Befehl aus, um OCR online durchzuführen und Bild-PDF in ein durchsuchbares PDF-Dokument zu konvertieren. Die resultierende Datei wird dann im Cloud-Speicher gespeichert.
curl -v -X GET "https://api.aspose.cloud/v4.0/words/Resultant.docx?format=TIFF&outPath=converted.tiff" \
-H "accept: application/octet-stream" \
-H "Authorization: Bearer <JWT Token>"
Abschluss
Das Durchführen von OCR auf PDFs ist ein kritischer Prozess, um das volle Potenzial dieser Dokumente auszuschöpfen. Mit Hilfe von Cloud-basierten OCR-Tools wie Aspose.PDF Cloud SDK für Java kann dieser Prozess vereinfacht und automatisiert werden, wodurch Zeit gespart und die Produktivität gesteigert wird. Durch die Nutzung der Leistungsfähigkeit von OCR können Unternehmen und Entwickler bildbasierte PDFs in durchsuchbare PDFs umwandeln, wodurch sie einfacher zu durchsuchen, zu bearbeiten und zu teilen sind. Es ist klar, dass diese API eine Reihe leistungsstarker Funktionen und Fähigkeiten für die Arbeit mit PDFs bietet. Indem Sie die Schritt-für-Schritt-Anleitungen in diesem technischen Blog befolgen, können Sie mit OCR in PDFs beginnen und Ihren Dokumenten-Workflow auf die nächste Stufe bringen.
Sie können in Betracht ziehen, über die Swagger-Schnittstelle in einem Webbrowser auf die API zuzugreifen. Da unsere SDKs außerdem unter einer MIT-Lizenz erstellt werden, kann der vollständige Quellcode von GitHub heruntergeladen werden. Falls Sie bei der Verwendung der API auf Probleme stoßen, können Sie uns gerne über das kostenlose Produktsupport-Forum kontaktieren.
In Verbindung stehende Artikel
Wir empfehlen dringend, die folgenden Links zu besuchen, um mehr darüber zu erfahren: