
છબી પીડીએફને શોધી શકાય તેવી પીડીએફમાં કન્વર્ટ કરો
આજના ડેટા-સંચાલિત વિશ્વમાં, PDFs દસ્તાવેજોને સ્ટોર કરવા અને શેર કરવા માટે અનિવાર્ય ફોર્મેટ બની ગયા છે. જો કે, બધી પીડીએફ સરળતાથી શોધી શકાય અથવા સંપાદન કરી શકાય તેવી હોતી નથી, ખાસ કરીને તે જે છબી-આધારિત હોય છે. દસ્તાવેજો સાથે કામ કરતી વખતે, વધુ હેરાફેરી માટે કોઈપણ ટેક્સ્ટની માહિતીને કૉપિ/એક્સટ્રેક્ટ કરવી ખરેખર મુશ્કેલ છે. સદનસીબે, ઓપ્ટિકલ કેરેક્ટર રેકગ્નિશન (OCR) ટેક્નોલોજીની શક્તિ સાથે, તમે ઇમેજ PDF ને સરળતાથી શોધી શકાય તેવી PDF માં કન્વર્ટ કરી શકો છો. આ તકનીકી બ્લોગમાં, અમે REST API પર ચોક્કસ ધ્યાન કેન્દ્રિત કરીને, વિવિધ તકનીકોનો ઉપયોગ કરીને OCR PDF ને શોધી શકાય તેવી PDF માં કેવી રીતે રૂપાંતરિત કરવું તે શોધીશું. તમારા પીડીએફ દસ્તાવેજોની સંપૂર્ણ સંભાવનાને અનલૉક કરવા માટે OCR ટેક્નોલોજીનો લાભ કેવી રીતે લેવો તેની વ્યાપક સમજ આપીને અમે OCR PDF માંથી ટેક્સ્ટ કેવી રીતે બહાર કાઢવું તેની પણ ચર્ચા કરીશું.
- Java SDK નો ઉપયોગ કરીને OCR PDF
- જાવા નો ઉપયોગ કરીને શોધી શકાય તેવી PDF માટે સ્કેન કરેલ PDF
- CURL આદેશોનો ઉપયોગ કરીને OCR ઓનલાઈન
Java SDK નો ઉપયોગ કરીને OCR PDF
[Aspose.PDF ક્લાઉડ SDK for Java2 એ એક શક્તિશાળી ક્લાઉડ-આધારિત API છે જે PDF દસ્તાવેજો સાથે કામ કરવા માટે સુવિધાઓ અને ક્ષમતાઓની વિશાળ શ્રેણી પ્રદાન કરે છે. તેની મુખ્ય કાર્યક્ષમતાઓમાંની એક PDFs પર OCR કરવાની ક્ષમતા છે, જે ઈમેજ-આધારિત PDF માંથી ટેક્સ્ટ કાઢવાની અને શોધી શકાય તેવી PDF બનાવવાની પ્રક્રિયાને મોટા પ્રમાણમાં સરળ બનાવી શકે છે. તેના વપરાશકર્તા મૈત્રીપૂર્ણ ઈન્ટરફેસ અને વ્યાપક દસ્તાવેજીકરણ સાથે, આ SDK પીડીએફ પર OCR કરવા, સમય બચાવવા અને ઉત્પાદકતા વધારવાની પ્રક્રિયાને સ્વચાલિત કરવાનું સરળ બનાવે છે.
વધુમાં, આ ક્લાઉડ-આધારિત API વિવિધ પ્રકારના ઇનપુટ ફોર્મેટ્સને હેન્ડલ કરવા માટે રચાયેલ છે અને હસ્તલિખિત ટેક્સ્ટને પણ ઓળખી શકે છે, જે વ્યવસાયો અને વિકાસકર્તાઓ માટે તેમના દસ્તાવેજ વર્કફ્લોને સુવ્યવસ્થિત કરવા માટે એક ઉત્તમ પસંદગી બનાવે છે. હવે પ્રથમ પગલું એ મેવન બિલ્ડ પ્રોજેક્ટના pom.xml માં નીચેની વિગતો ઉમેરીને Java પ્રોજેક્ટમાં તેનો સંદર્ભ ઉમેરવાનો છે.
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>http://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
જો તમારી પાસે હાલનું એકાઉન્ટ નથી, તો તમારે Aspose Cloud પર એક મફત એકાઉન્ટ બનાવવાની જરૂર છે. નવા બનાવેલા એકાઉન્ટનો ઉપયોગ કરીને લૉગિન કરો અને [ક્લાઉડ ડેશબોર્ડ] પર ક્લાયંટ આઈડી અને ક્લાયન્ટ સિક્રેટ જુઓ/બનાવો5. આ વિગતો અનુગામી વિભાગોમાં જરૂરી છે.
જાવા નો ઉપયોગ કરીને શોધી શકાય તેવી PDF માટે સ્કેન કરેલ PDF
આ વિભાગ જાવા કોડ સ્નિપેટનો ઉપયોગ કરીને સ્કેન કરેલી પીડીએફને શોધી શકાય તેવી પીડીએફમાં કેવી રીતે કન્વર્ટ કરવું તેની વિગતો સમજાવે છે. કૃપા કરીને નોંધો કે Java Cloud SDK નીચેની ભાષાઓની ઓળખને સમર્થન આપે છે: eng, ara, bel, ben, bul, ces, dan, deu, ell, fin, fra, heb, hin, ind, isl, ita, jpn, kor, nld , અથવા, પોલ, પોર, રોન, રુસ, સ્પા, સ્વે, થા, તુર, ઉક્ર, વિયે, ચિસિમ, ચિત્રા અથવા તેમનું સંયોજન દા.ત. eng,rus.
- સૌપ્રથમ આપણે PdfApi નો એક ઑબ્જેક્ટ બનાવવાની જરૂર છે, જ્યાં આપણે દલીલો તરીકે ClientID અને ક્લાયન્ટની ગુપ્ત વિગતો પસાર કરીએ છીએ.
- બીજું, ઇમેજ પીડીએફ લોડ કરવા માટે ફાઇલ ક્લાસનો એક દાખલો બનાવો
- ત્રીજે સ્થાને, ક્લાઉડ સ્ટોરેજમાં ઇનપુટ પીડીએફ અપલોડ કરવા માટે અપલોડફાઇલ(…) પદ્ધતિને કૉલ કરો
- જેમ કે અમારી ઇમેજ PDF માં અંગ્રેજી ટેક્સ્ટ હોય છે, તેથી આપણે “eng” વેલ્યુ ધરાવતું સ્ટ્રિંગ ઑબ્જેક્ટ બનાવવાની જરૂર છે.
- છેલ્લે, પદ્ધતિને કૉલ કરો putSearchableDocument(…), જેને ઇનપુટ PDF અને દલીલો તરીકે ભાષા કોડની જરૂર છે.
એકવાર કોડ સફળતાપૂર્વક એક્ઝિક્યુટ થઈ જાય પછી, શોધી શકાય તેવી PDF ક્લાઉડ સ્ટોરેજમાં સંગ્રહિત થાય છે
try
{
// https://dashboard.aspose.cloud/ પરથી ClientID અને ClientSecret મેળવો
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// બનાવોPdfApi ઉદાહરણ
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// ઇનપુટ છબી PDF દસ્તાવેજ
String name = "ScannedPDF.pdf";
// સ્થાનિક સિસ્ટમમાંથી ફાઇલ લોડ કરો
File file = new File(name);
// ક્લાઉડ સ્ટોરેજ પર ફાઇલ અપલોડ કરો
FilesUploadResult uploadResponse = pdfApi.uploadFile(name, file, null);
// ઇમેજ PDF માં વપરાતી ભાષાઓ
String lang = "eng";
// છબી પીડીએફ દસ્તાવેજ પર OCR કરો
AsposeResponse response = pdfApi.putSearchableDocument(name, null, null, lang);
// સફળતા સંદેશ છાપો
System.out.println("OCR PDF successfull !");
}catch(Exception ex)
{
System.out.println(ex.getMessage());
}
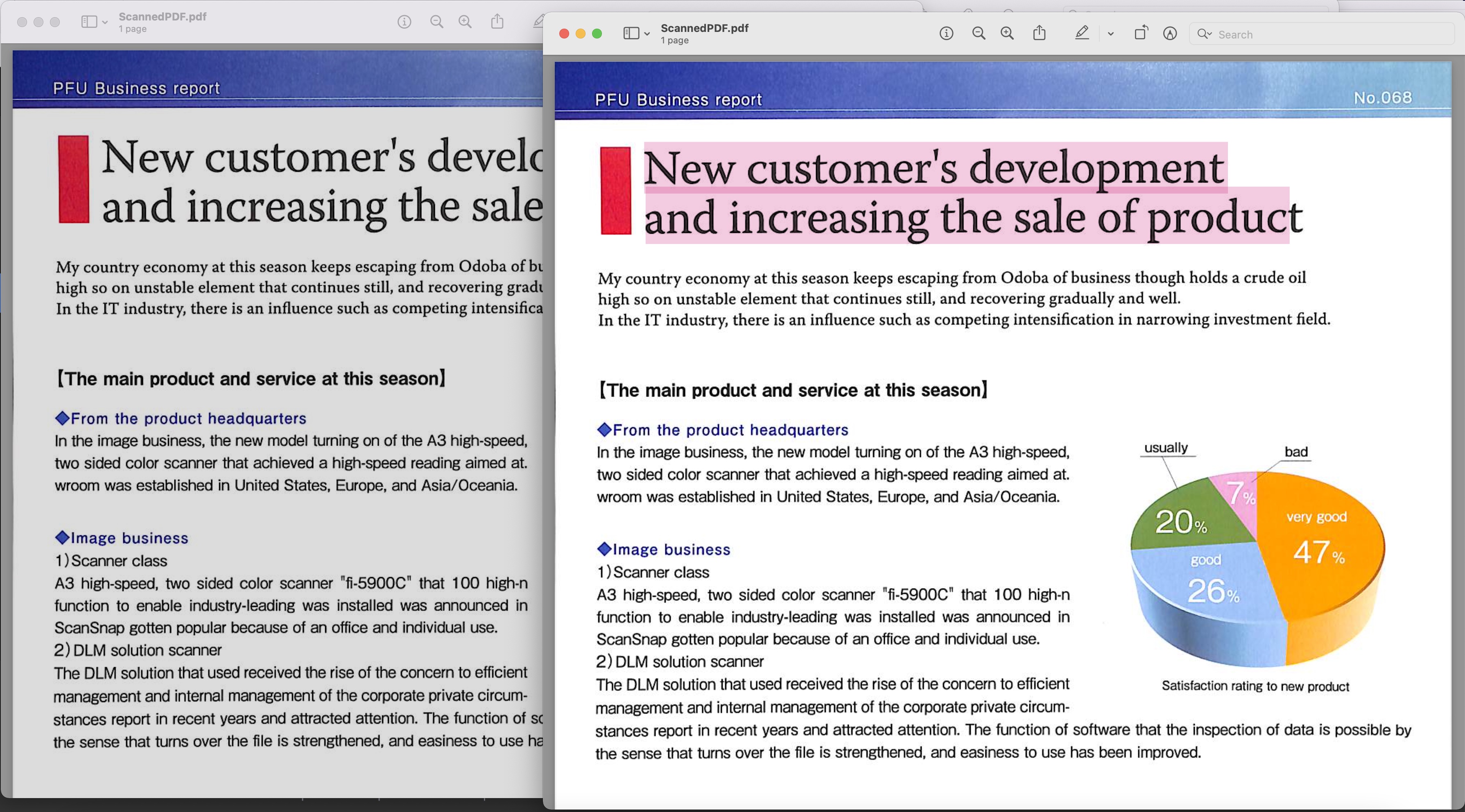
છબી 1:- શોધી શકાય તેવું પીડીએફ પૂર્વાવલોકન
ઉપરોક્ત ઉદાહરણમાં વપરાયેલ સ્કેન કરેલ PDF BusinessReport.pdf પરથી ડાઉનલોડ કરી શકાય છે અને પરિણામે શોધી શકાય તેવી PDF Converted.pdf પરથી ડાઉનલોડ કરી શકાય છે.
CURL આદેશોનો ઉપયોગ કરીને OCR ઓનલાઈન
CURL આદેશો એ REST API ને કૉલ કરવા માટે અનુકૂળ અભિગમોમાંનો એક છે. તો આ વિભાગમાં, અમે ઓસીઆર ઓનલાઈન માટે cURL આદેશોનો ઉપયોગ કરવા જઈ રહ્યા છીએ. હવે, પૂર્વશરત તરીકે, નીચે આપેલા આદેશને એક્ઝિક્યુટ કરતી વખતે આપણે પહેલા JWT એક્સેસ ટોકન (ક્લાયન્ટ ઓળખપત્ર પર આધારિત) જનરેટ કરવાની જરૂર છે.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
એકવાર અમારી પાસે JWT ટોકન થઈ જાય, OCR ઓનલાઈન કરવા અને ઈમેજ પીડીએફને શોધી શકાય તેવા PDF દસ્તાવેજમાં કન્વર્ટ કરવા માટે કૃપા કરીને નીચેનો આદેશ આપો. પરિણામી ફાઇલ પછી ક્લાઉડ સ્ટોરેજમાં સંગ્રહિત થાય છે.
curl -v -X GET "https://api.aspose.cloud/v4.0/words/Resultant.docx?format=TIFF&outPath=converted.tiff" \
-H "accept: application/octet-stream" \
-H "Authorization: Bearer <JWT Token>"
નિષ્કર્ષ
પીડીએફ પર OCR કરવું એ આ દસ્તાવેજોની સંપૂર્ણ સંભાવનાને અનલૉક કરવા માટે એક મહત્વપૂર્ણ પ્રક્રિયા છે. જાવા માટે Aspose.PDF ક્લાઉડ SDK જેવા ક્લાઉડ-આધારિત OCR ટૂલ્સની મદદથી, આ પ્રક્રિયાને સરળ અને સ્વચાલિત કરી શકાય છે, સમયની બચત થાય છે અને ઉત્પાદકતામાં વધારો થાય છે. OCR ની શક્તિનો ઉપયોગ કરીને, વ્યવસાયો અને વિકાસકર્તાઓ છબી-આધારિત PDF ને શોધી શકાય તેવી PDF માં પરિવર્તિત કરી શકે છે, જે તેમને શોધવા, સંપાદિત કરવા અને શેર કરવાનું સરળ બનાવે છે. તે સ્પષ્ટ છે કે આ API પીડીએફ સાથે કામ કરવા માટે શક્તિશાળી સુવિધાઓ અને ક્ષમતાઓની શ્રેણી પ્રદાન કરે છે. આ ટેકનિકલ બ્લોગમાં આપેલ સ્ટેપ-બાય-સ્ટેપ ગાઈડ્સને અનુસરીને, તમે PDF પર OCR સાથે પ્રારંભ કરી શકો છો અને તમારા દસ્તાવેજ વર્કફ્લોને આગલા સ્તર પર લઈ જઈ શકો છો.
તમે સ્વેગર ઈન્ટરફેસ નો ઉપયોગ કરીને વેબ બ્રાઉઝરમાં API ને ઍક્સેસ કરવાનું વિચારી શકો છો. વધુમાં, કારણ કે અમારા SDKs MIT લાયસન્સ હેઠળ બનાવવામાં આવ્યા છે, તેથી સંપૂર્ણ સ્રોત કોડ GitHub પરથી ડાઉનલોડ કરી શકાય છે. જો તમને API નો ઉપયોગ કરતી વખતે કોઈ સમસ્યા આવે તો, કૃપા કરીને ફ્રી પ્રોડક્ટ સપોર્ટ ફોરમ દ્વારા અમારો સંપર્ક કરવા માટે નિઃસંકોચ કરો.
સંબંધિત લેખો
અમે આ વિશે વધુ જાણવા માટે નીચેની લિંક્સની મુલાકાત લેવાની ખૂબ ભલામણ કરીએ છીએ: