
Convertir un PDF image en PDF consultable
Dans le monde actuel axé sur les données, les PDF sont devenus un format indispensable pour stocker et partager des documents. Cependant, tous les fichiers PDF ne sont pas facilement consultables ou modifiables, en particulier ceux qui sont basés sur des images. Lorsqu’il s’agit de documents, il est vraiment difficile de copier/extraire des informations textuelles pour une manipulation ultérieure. Heureusement, grâce à la puissance de la technologie de reconnaissance optique de caractères (OCR), vous pouvez facilement convertir des images PDF en fichiers PDF interrogeables. Dans ce blog technique, nous explorerons comment convertir un PDF OCR en PDF consultable à l’aide de diverses techniques, avec un accent particulier sur l’API REST. Nous discuterons également de la façon d’extraire du texte à partir de PDF OCR, vous donnant une compréhension complète de la façon d’exploiter la technologie OCR pour libérer le plein potentiel de vos documents PDF.
- OCR PDF à l’aide du SDK Java
- PDF numérisé en PDF consultable à l’aide de Java
- OCR en ligne à l’aide des commandes cURL
OCR PDF à l’aide du SDK Java
Aspose.PDF Cloud SDK for Java est une puissante API basée sur le cloud qui offre un large éventail de fonctionnalités et de capacités pour travailler avec des documents PDF. L’une de ses fonctionnalités clés est la possibilité d’effectuer une OCR sur des PDF, ce qui peut grandement simplifier le processus d’extraction de texte à partir de PDF à base d’images et de création de PDF consultables. Avec son interface conviviale et sa documentation complète, ce SDK facilite l’automatisation du processus d’exécution de l’OCR sur les PDF, ce qui permet de gagner du temps et d’augmenter la productivité.
De plus, cette API basée sur le cloud est conçue pour gérer une grande variété de formats d’entrée et peut même reconnaître le texte manuscrit, ce qui en fait un excellent choix pour les entreprises et les développeurs qui cherchent à rationaliser leur flux de travail de documents. Maintenant, la première étape consiste à ajouter sa référence dans le projet Java en ajoutant les détails suivants dans pom.xml du projet de construction maven.
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>https://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
Si vous n’avez pas de compte existant, vous devez créer un compte gratuit sur Aspose Cloud. Connectez-vous à l’aide d’un compte nouvellement créé et recherchez/créez un ID client et un secret client sur Cloud Dashboard. Ces détails sont requis dans les sections suivantes.
PDF numérisé en PDF consultable à l’aide de Java
Cette section explique en détail comment convertir un PDF numérisé en PDF consultable à l’aide d’un extrait de code Java. Veuillez noter que Java Cloud SDK prend en charge la reconnaissance des langues suivantes : eng, ara, bel, ben, bul, ces, dan, deu, ell, fin, fra, heb, hin, ind, isl, ita, jpn, kor, nld , ni, pol, por, ron, rus, spa, swe, tha, tur, ukr, vie, chisim, chitra ou leur combinaison, par exemple eng, rus.
- Nous devons d’abord créer un objet de PdfApi, où nous transmettons les détails du client ID et du secret client comme arguments
- Deuxièmement, créez une instance de la classe File pour charger l’image PDF
- Troisièmement, appelez la méthode uploadFile(…) pour télécharger le PDF d’entrée sur le stockage cloud
- Comme notre image PDF contient du texte anglais, nous devons donc créer un objet chaîne contenant une valeur “eng”
- Enfin, appelez la méthode putSearchableDocument(…), qui nécessite un PDF d’entrée et un code de langue comme arguments.
Une fois le code exécuté avec succès, le PDF consultable est stocké dans le stockage en nuage
try
{
// Obtenez ClientID et ClientSecret à partir de https://dashboard.aspose.cloud/
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// instance createPdfApi
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// image d'entrée document PDF
String name = "ScannedPDF.pdf";
// Charger le fichier depuis le système local
File file = new File(name);
// télécharger le fichier sur le stockage en nuage
FilesUploadResult uploadResponse = pdfApi.uploadFile(name, file, null);
// les langues utilisées dans l'image PDF
String lang = "eng";
// effectuer l'OCR sur un document PDF image
AsposeResponse response = pdfApi.putSearchableDocument(name, null, null, lang);
// imprimer le message de réussite
System.out.println("OCR PDF successfull !");
}catch(Exception ex)
{
System.out.println(ex.getMessage());
}
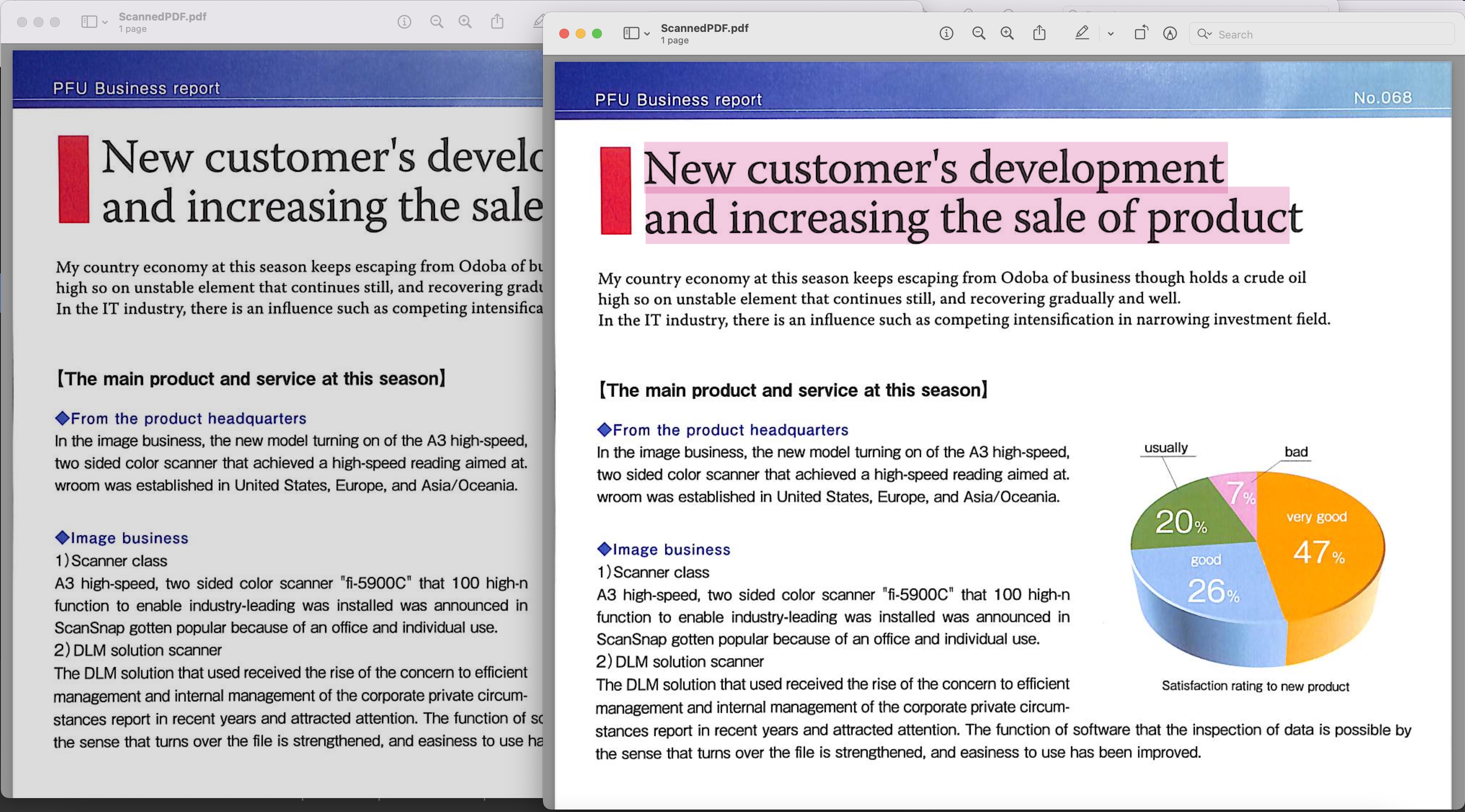
Image1 :- Aperçu PDF consultable
Le PDF scanné utilisé dans l’exemple ci-dessus peut être téléchargé depuis BusinessReport.pdf et le PDF consultable résultant depuis Converted.pdf
OCR en ligne à l’aide des commandes cURL
Les commandes cURL sont l’une des approches pratiques pour appeler les API REST. Donc, dans cette section, nous allons utiliser les commandes cURL pour l’OCR en ligne. Maintenant, comme condition préalable, nous devons d’abord générer un jeton d’accès JWT (basé sur les informations d’identification du client) lors de l’exécution de la commande suivante.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Une fois que nous avons le jeton JWT, veuillez utiliser la commande suivante pour effectuer l’OCR en ligne et convertir le PDF image en document PDF consultable. Le fichier résultant est ensuite stocké dans le stockage en nuage.
curl -v -X GET "https://api.aspose.cloud/v4.0/words/Resultant.docx?format=TIFF&outPath=converted.tiff" \
-H "accept: application/octet-stream" \
-H "Authorization: Bearer <JWT Token>"
Conclusion
L’exécution d’OCR sur des PDF est un processus essentiel pour libérer tout le potentiel de ces documents. Avec l’aide d’outils OCR basés sur le cloud comme Aspose.PDF Cloud SDK pour Java, ce processus peut être simplifié et automatisé, ce qui permet de gagner du temps et d’augmenter la productivité. En tirant parti de la puissance de l’OCR, les entreprises et les développeurs peuvent transformer des PDF basés sur des images en PDF consultables, ce qui facilite la recherche, la modification et le partage. Il est clair que cette API offre une gamme de fonctionnalités et de capacités puissantes pour travailler avec des PDF. En suivant les guides étape par étape fournis dans ce blog technique, vous pouvez démarrer avec l’OCR sur les PDF et faire passer votre flux de travail de documents au niveau supérieur.
Vous pouvez envisager d’accéder à l’API dans un navigateur Web à l’aide de l’interface swagger. De plus, comme nos SDK sont construits sous une licence MIT, le code source complet peut être téléchargé depuis GitHub. Si vous rencontrez des problèmes lors de l’utilisation de l’API, n’hésitez pas à nous contacter via forum d’assistance produit gratuit.
Articles Liés
Nous vous recommandons vivement de visiter les liens suivants pour en savoir plus sur :