
Преобразование PDF-файла изображения в PDF-файл с возможностью поиска
В современном мире, управляемом данными, PDF стали незаменимым форматом для хранения документов и обмена ими. Однако не все PDF-файлы легко доступны для поиска или редактирования, особенно те, которые основаны на изображениях. При работе с документами очень сложно скопировать/извлечь любую текстовую информацию для дальнейшей обработки. К счастью, благодаря мощной технологии оптического распознавания символов (OCR) вы можете легко преобразовывать PDF-файлы с изображениями в PDF-файлы с возможностью поиска. В этом техническом блоге мы рассмотрим, как конвертировать OCR PDF в PDF с возможностью поиска, используя различные методы, уделяя особое внимание REST API. Мы также обсудим, как извлекать текст из PDF-файлов OCR, дав вам полное представление о том, как использовать технологию OCR, чтобы раскрыть весь потенциал ваших PDF-документов.
- OCR PDF с использованием Java SDK
- Отсканированный PDF в PDF с возможностью поиска с использованием Java
- OCR онлайн с использованием команд cURL
OCR PDF с использованием Java SDK
Aspose.PDF Cloud SDK для Java — это мощный облачный API, предлагающий широкий спектр функций и возможностей для работы с PDF-документами. Одной из его ключевых функций является возможность выполнять распознавание текста в PDF-файлах, что может значительно упростить процесс извлечения текста из PDF-файлов на основе изображений и создания PDF-файлов с возможностью поиска. Благодаря удобному интерфейсу и исчерпывающей документации этот пакет SDK позволяет легко автоматизировать процесс распознавания текста в PDF-файлах, экономя время и повышая производительность.
Кроме того, этот облачный API предназначен для работы с широким спектром форматов ввода и может даже распознавать рукописный текст, что делает его отличным выбором для предприятий и разработчиков, стремящихся оптимизировать рабочий процесс документов. Теперь первый шаг — добавить его ссылку в проект Java, добавив следующие сведения в pom.xml проекта сборки maven.
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>https://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
Если у вас нет существующей учетной записи, вам необходимо создать бесплатную учетную запись в Aspose Cloud. Войдите в систему, используя только что созданную учетную запись, и найдите/создайте идентификатор клиента и секрет клиента на Cloud Dashboard. Эти детали потребуются в последующих разделах.
Отсканированный PDF в PDF с возможностью поиска с использованием Java
В этом разделе объясняется, как преобразовать отсканированный PDF-файл в PDF-файл с возможностью поиска с помощью фрагмента кода Java. Обратите внимание, что Java Cloud SDK поддерживает распознавание следующих языков: eng, ara, bel, ben, bul, ces, dan, deu, ell, fin, fra, heb, hin, ind, isl, ita, jpn, kor, nld. , нор, пол, пор, рон, рус, спа, шве, та, тур, укр, ви, чисим, читра или их комбинация, например, англ, рус.
- Сначала нам нужно создать объект PdfApi, которому мы передаем ClientID и данные секрета клиента в качестве аргументов.
- Во-вторых, создайте экземпляр класса File для загрузки PDF-файла изображения.
- В-третьих, вызовите метод uploadFile(…) для загрузки входного PDF-файла в облачное хранилище.
- Поскольку наше изображение в формате PDF содержит текст на английском языке, нам нужно создать строковый объект со значением «eng».
- Наконец, вызовите метод putSearchableDocument(…), который требует входной PDF-файл и код языка в качестве аргументов.
После успешного выполнения кода PDF-файл с возможностью поиска сохраняется в облачном хранилище.
try
{
// Получите ClientID и ClientSecret с https://dashboard.aspose.cloud/
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// экземпляр createPdfApi
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// входное изображение PDF-документ
String name = "ScannedPDF.pdf";
// Загрузите файл из локальной системы
File file = new File(name);
// загрузить файл в облачное хранилище
FilesUploadResult uploadResponse = pdfApi.uploadFile(name, file, null);
// языки, используемые в изображении PDF
String lang = "eng";
// выполнить OCR на изображении PDF-документа
AsposeResponse response = pdfApi.putSearchableDocument(name, null, null, lang);
// распечатать сообщение об успешном завершении
System.out.println("OCR PDF successfull !");
}catch(Exception ex)
{
System.out.println(ex.getMessage());
}
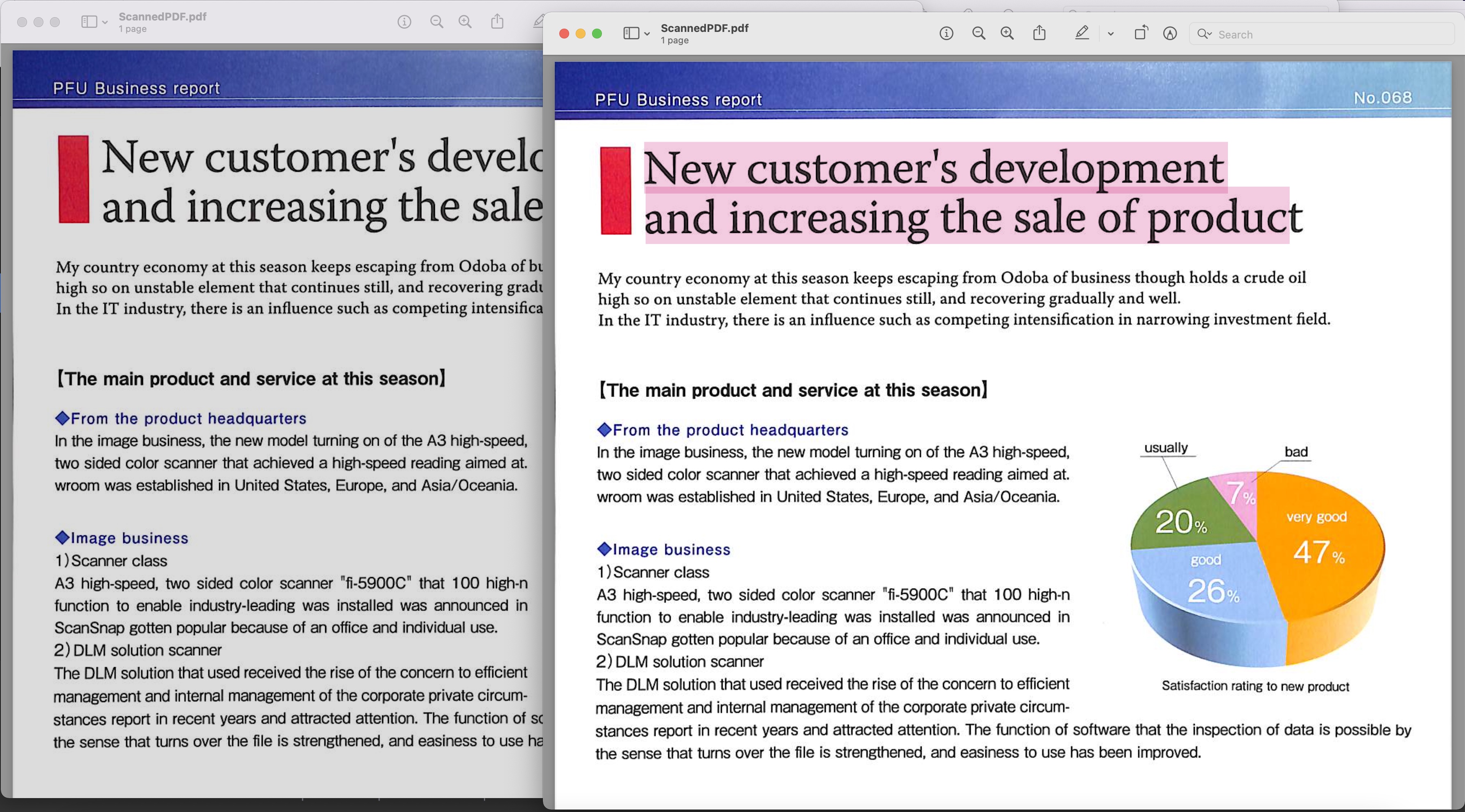
Изображение 1: предварительный просмотр PDF с возможностью поиска
Отсканированный PDF-файл, использованный в приведенном выше примере, можно загрузить из BusinessReport.pdf, а результирующий PDF-файл с возможностью поиска из Converted.pdf.
OCR онлайн с использованием команд cURL
Команды cURL — это один из удобных подходов к вызову REST API. Итак, в этом разделе мы собираемся использовать команды cURL для OCR в Интернете. Теперь, в качестве предварительного условия, нам нужно сначала сгенерировать токен доступа JWT (на основе учетных данных клиента) при выполнении следующей команды.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Как только у нас будет токен JWT, выполните следующую команду, чтобы выполнить распознавание текста онлайн и преобразовать PDF-файл изображения в PDF-документ с возможностью поиска. Полученный файл затем сохраняется в облачном хранилище.
curl -v -X GET "https://api.aspose.cloud/v4.0/words/Resultant.docx?format=TIFF&outPath=converted.tiff" \
-H "accept: application/octet-stream" \
-H "Authorization: Bearer <JWT Token>"
Заключение
Выполнение оптического распознавания символов в PDF-файлах является важным процессом для раскрытия всего потенциала этих документов. С помощью облачных инструментов OCR, таких как Aspose.PDF Cloud SDK для Java, этот процесс можно упростить и автоматизировать, экономя время и повышая производительность. Используя возможности OCR, предприятия и разработчики могут преобразовывать PDF-файлы на основе изображений в PDF-файлы с возможностью поиска, упрощая их поиск, редактирование и обмен. Понятно, что этот API предлагает ряд мощных функций и возможностей для работы с PDF-файлами. Следуя пошаговым руководствам, приведенным в этом техническом блоге, вы сможете начать работу с распознаванием текста в PDF-файлах и вывести рабочий процесс на новый уровень.
Вы можете получить доступ к API в веб-браузере, используя интерфейс swagger. Кроме того, поскольку наши SDK создаются под лицензией MIT, полный исходный код можно загрузить с GitHub. Если у вас возникнут какие-либо проблемы при использовании API, свяжитесь с нами через бесплатный форум поддержки продуктов.
Статьи по Теме
Мы настоятельно рекомендуем посетить следующие ссылки, чтобы узнать больше о: