
Skakel prent-PDF om na soekbare PDF
In vandag se data-gedrewe wêreld het PDF’s ’n onontbeerlike formaat geword vir die stoor en deel van dokumente. Nie alle PDF’s is egter maklik soekbaar of redigeerbaar nie, veral dié wat beeldgebaseer is. Wanneer u met dokumente handel, is dit regtig moeilik om enige teksinligting te kopieer/onttrek vir verdere manipulasie. Gelukkig, met die krag van Optical Character Recognition (OCR)-tegnologie, kan jy beeld-PDF’s met gemak in soekbare PDF’s omskep. In hierdie tegniese blog sal ons ondersoek hoe om OCR PDF om te skakel na soekbare PDF deur verskeie tegnieke te gebruik, met ’n spesifieke fokus op REST API. Ons sal ook bespreek hoe om teks uit OCR PDF’s te onttrek, wat jou ’n omvattende begrip gee van hoe om OCR-tegnologie te benut om die volle potensiaal van jou PDF-dokumente te ontsluit.
- OCR PDF met behulp van Java SDK
- Geskandeerde PDF na soekbare PDF met Java
- OCR Aanlyn met behulp van cURL-opdragte
OCR PDF met behulp van Java SDK
Aspose.PDF Wolk SDK vir Java is ’n kragtige wolk-gebaseerde API wat ’n wye reeks kenmerke en vermoëns bied om met PDF-dokumente te werk. Een van sy sleutelfunksies is die vermoë om OCR op PDF’s uit te voer, wat die proses om teks uit beeldgebaseerde PDF’s te onttrek en deursoekbare PDF’s te skep, aansienlik kan vereenvoudig. Met sy gebruikersvriendelike koppelvlak en omvattende dokumentasie maak hierdie SDK dit maklik om die proses om OCR op PDF’s uit te voer, te outomatiseer, wat tyd bespaar en produktiwiteit verhoog.
Verder is hierdie wolk-gebaseerde API ontwerp om ’n wye verskeidenheid invoerformate te hanteer en kan selfs handgeskrewe teks herken, wat dit ’n uitstekende keuse maak vir besighede en ontwikkelaars wat hul dokumentwerkstroom wil stroomlyn. Nou is die eerste stap om sy verwysing in Java-projek by te voeg deur die volgende besonderhede by te voeg in pom.xml van maven bouprojek.
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>http://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
As jy nie ’n bestaande rekening het nie, moet jy ’n gratis rekening oor Aspose Cloud skep. Meld aan met nuutgeskepte rekening en soek/skep Kliënt-ID en Kliëntgeheim by Cloud Dashboard. Hierdie besonderhede word in die volgende afdelings vereis.
Geskandeerde PDF na soekbare PDF met Java
Hierdie afdeling verduidelik die besonderhede oor hoe om geskandeerde PDF na Soekbare PDF om te skakel met behulp van Java-kodebrokkie. Neem asseblief kennis dat Java Cloud SDK die herkenning van die volgende tale ondersteun: eng, ara, bel, ben, bul, ces, dan, deu, ell, fin, fra, heb, hin, ind, isl, ita, jpn, kor, nld , nor, pol, por, ron, rus, spa, swe, tha, tur, ukr, vie, chisim, chitra of hul kombinasie bv eng,rus.
- Eerstens moet ons ’n objek van PdfApi skep, waar ons ClientID en Client geheime besonderhede as argumente deurgee
- Tweedens, skep ’n instansie van lêerklas om die prent-PDF te laai
- Roep derdens die metode uploadFile(…) om die invoer-PDF na die wolkberging op te laai
- Aangesien ons beeld-PDF Engelse teks bevat, moet ons dus ’n stringvoorwerp skep met ’n waarde “eng”
- Laastens, noem die metode putSearchableDocument(…), wat ’n invoer-PDF en ’n taalkode as argumente vereis.
Sodra die kode suksesvol uitgevoer is, word die soekbare PDF in wolkberging gestoor
try
{
// Kry ClientID en ClientSecret vanaf https://dashboard.aspose.cloud/
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// skepPdfApi-instansie
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// invoer beeld PDF-dokument
String name = "ScannedPDF.pdf";
// Laai die lêer vanaf die plaaslike stelsel
File file = new File(name);
// laai die lêer op na wolkberging
FilesUploadResult uploadResponse = pdfApi.uploadFile(name, file, null);
// die tale wat in beeld-PDF gebruik word
String lang = "eng";
// voer die OCR op PDF-prentdokument uit
AsposeResponse response = pdfApi.putSearchableDocument(name, null, null, lang);
// druk suksesboodskap
System.out.println("OCR PDF successfull !");
}catch(Exception ex)
{
System.out.println(ex.getMessage());
}
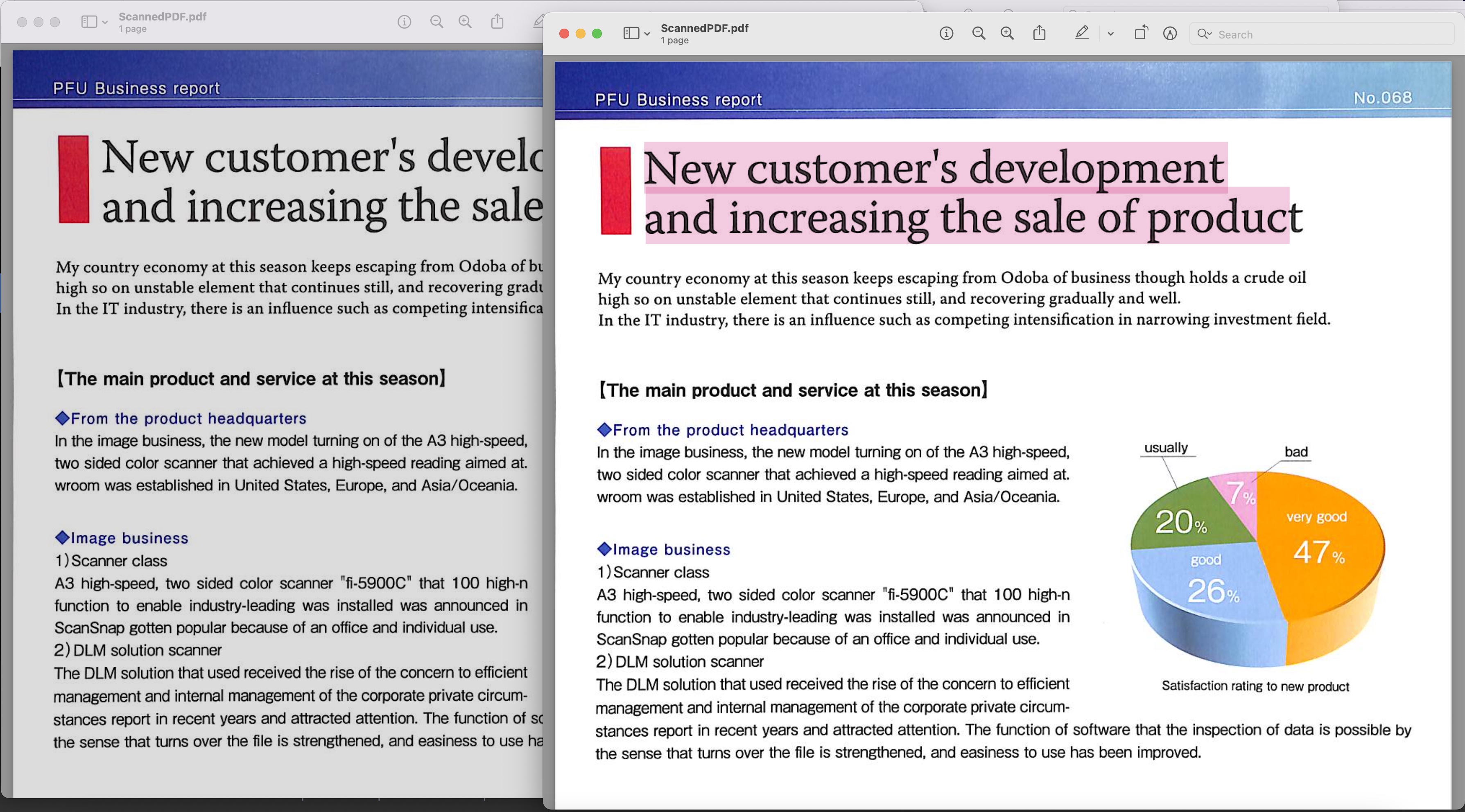
Beeld 1: - Soekbare PDF-voorskou
Die geskandeerde PDF wat in die voorbeeld hierbo gebruik is, kan afgelaai word vanaf BusinessReport.pdf en die gevolglike soekbare PDF vanaf Converted.pdf
OCR Aanlyn met behulp van cURL-opdragte
Die cURL-opdragte is een van die gerieflike benaderings om die REST API’s te noem. So in hierdie afdeling gaan ons die cURL-opdragte vir OCR aanlyn gebruik. Nou, as ’n voorvereiste, moet ons eers ’n JWT-toegangstoken genereer (gebaseer op kliëntgeloofsbriewe) terwyl ons die volgende opdrag uitvoer.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Sodra ons JWT-token het, die volgende opdrag om OCR aanlyn uit te voer en Image PDF om te skakel na soekbare PDF-dokument. Die resulterende lêer word dan in wolkberging gestoor.
curl -v -X GET "https://api.aspose.cloud/v4.0/words/Resultant.docx?format=TIFF&outPath=converted.tiff" \
-H "accept: application/octet-stream" \
-H "Authorization: Bearer <JWT Token>"
Afsluiting
Die uitvoering van OCR op PDF’s is ’n kritieke proses om die volle potensiaal van hierdie dokumente te ontsluit. Met die hulp van wolkgebaseerde OCR-instrumente soos Aspose.PDF Wolk SDK vir Java, kan hierdie proses vereenvoudig en geoutomatiseer word, wat tyd bespaar en produktiwiteit verhoog. Deur die krag van OCR te benut, kan besighede en ontwikkelaars beeldgebaseerde PDF’s omskep in soekbare PDF’s, wat dit makliker maak om te soek, te redigeer en te deel. Dit is duidelik dat hierdie API ’n reeks kragtige kenmerke en vermoëns bied om met PDF’s te werk. Deur die stap-vir-stap-gidse wat in hierdie tegniese blog verskaf word, te volg, kan jy met OCR op PDF’s begin en jou dokumentwerkvloei na die volgende vlak neem.
U kan dit oorweeg om toegang tot die API binne ’n webblaaier te verkry deur die swagger-koppelvlak te gebruik. Verder, aangesien ons SDK’s onder ’n MIT-lisensie gebou is, kan die volledige bronkode van GitHub afgelaai word. As jy enige probleme ondervind tydens die gebruik van die API, voel asseblief vry om ons te kontak via gratis produkondersteuningsforum.
verwante artikels
Ons beveel sterk aan om die volgende skakels te besoek om meer te wete te kom oor: