
Convertir PDF de imagen a PDF con capacidad de búsqueda
En el mundo actual basado en datos, los PDF se han convertido en un formato indispensable para almacenar y compartir documentos. Sin embargo, no todos los archivos PDF se pueden buscar o editar fácilmente, especialmente aquellos que están basados en imágenes. Cuando se trata de documentos, es realmente difícil copiar/extraer cualquier información textual para su posterior manipulación. Afortunadamente, con el poder de la tecnología de reconocimiento óptico de caracteres (OCR), puede convertir archivos PDF de imagen en archivos PDF con capacidad de búsqueda con facilidad. En este blog técnico, exploraremos cómo convertir PDF con OCR a PDF con capacidad de búsqueda utilizando varias técnicas, con un enfoque específico en la API REST. También analizaremos cómo extraer texto de archivos PDF OCR, lo que le brindará una comprensión integral de cómo aprovechar la tecnología OCR para desbloquear todo el potencial de sus documentos PDF.
- OCR PDF usando Java SDK
- PDF escaneado a PDF con capacidad de búsqueda usando Java
- OCR en línea usando comandos cURL
OCR PDF usando Java SDK
Aspose.PDF Cloud SDK for Java es una potente API basada en la nube que ofrece una amplia gama de funciones y capacidades para trabajar con documentos PDF. Una de sus funcionalidades clave es la capacidad de realizar OCR en archivos PDF, lo que puede simplificar enormemente el proceso de extracción de texto de archivos PDF basados en imágenes y la creación de archivos PDF con capacidad de búsqueda. Con su interfaz fácil de usar y su documentación completa, este SDK facilita la automatización del proceso de realizar OCR en archivos PDF, ahorrando tiempo y aumentando la productividad.
Además, esta API basada en la nube está diseñada para manejar una amplia variedad de formatos de entrada e incluso puede reconocer texto escrito a mano, lo que la convierte en una excelente opción para empresas y desarrolladores que buscan optimizar su flujo de trabajo de documentos. Ahora, el primer paso es agregar su referencia en el proyecto Java agregando los siguientes detalles en pom.xml del proyecto de compilación maven.
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>https://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
Si no tiene una cuenta existente, debe crear una cuenta gratuita en Aspose Cloud. Inicie sesión con una cuenta recién creada y busque/cree el ID del cliente y el secreto del cliente en Cloud Dashboard. Estos detalles son necesarios en las secciones siguientes.
PDF escaneado a PDF con capacidad de búsqueda usando Java
Esta sección explica los detalles sobre cómo convertir un PDF escaneado a un PDF con capacidad de búsqueda usando un fragmento de código Java. Tenga en cuenta que Java Cloud SDK admite el reconocimiento de los siguientes idiomas: eng, ara, bel, ben, bul, ces, dan, deu, ell, fin, fra, heb, hin, ind, isl, ita, jpn, kor, nld , nor, pol, por, ron, rus, spa, swe, tha, tur, ukr, vie, chisim, chitra o su combinación, por ejemplo, eng,rus.
- Primero necesitamos crear un objeto de PdfApi, donde pasamos los detalles de ClientID y Client secret como argumentos
- En segundo lugar, cree una instancia de la clase Archivo para cargar la imagen PDF
- En tercer lugar, llame al método uploadFile(…) para cargar el PDF de entrada en el almacenamiento en la nube.
- Como nuestra imagen PDF contiene texto en inglés, necesitamos crear un objeto de cadena que contenga un valor “eng”
- Finalmente, llame al método putSearchableDocument(…), que requiere un PDF de entrada y un código de idioma como argumentos.
Una vez que el código se ejecuta con éxito, el PDF buscable se almacena en el almacenamiento en la nube
try
{
// Obtenga ClientID y ClientSecret de https://dashboard.aspose.cloud/
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// instancia createPdfApi
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// imagen de entrada documento PDF
String name = "ScannedPDF.pdf";
// Cargue el archivo desde el sistema local
File file = new File(name);
// sube el archivo al almacenamiento en la nube
FilesUploadResult uploadResponse = pdfApi.uploadFile(name, file, null);
// los idiomas utilizados en la imagen PDF
String lang = "eng";
// realizar el OCR en un documento PDF de imagen
AsposeResponse response = pdfApi.putSearchableDocument(name, null, null, lang);
// mensaje de éxito de impresión
System.out.println("OCR PDF successfull !");
}catch(Exception ex)
{
System.out.println(ex.getMessage());
}
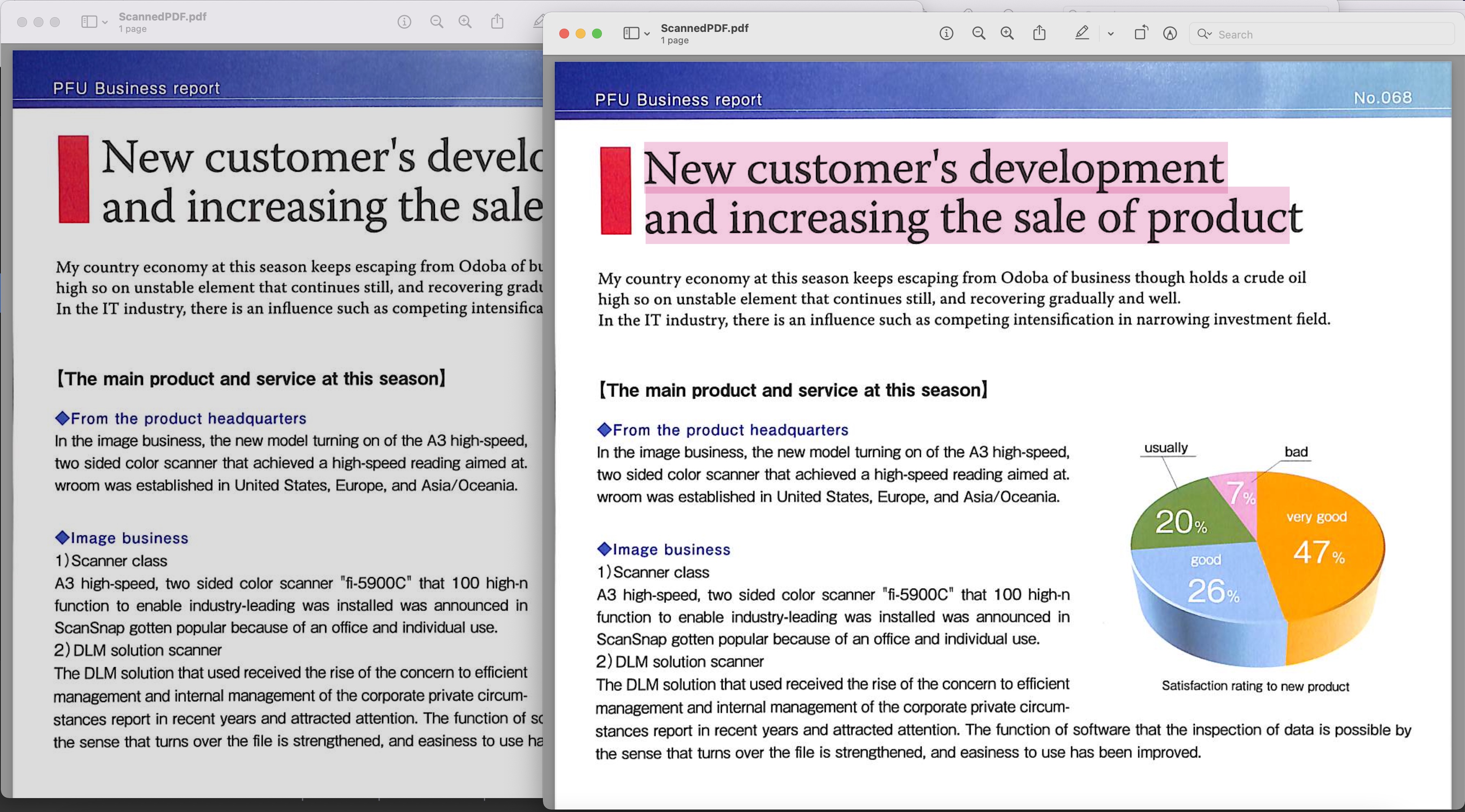
Imagen 1: - Vista previa de PDF con capacidad de búsqueda
El PDF escaneado utilizado en el ejemplo anterior se puede descargar de BusinessReport.pdf y el PDF de búsqueda resultante de Converted.pdf
OCR en línea usando comandos cURL
Los comandos cURL son uno de los enfoques convenientes para llamar a las API REST. Entonces, en esta sección, vamos a usar los comandos cURL para OCR en línea. Ahora, como requisito previo, primero debemos generar un token de acceso JWT (basado en las credenciales del cliente) mientras ejecutamos el siguiente comando.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Una vez que tengamos el token JWT, utilice el siguiente comando para realizar OCR en línea y convertir la imagen PDF en un documento PDF con capacidad de búsqueda. El archivo resultante se almacena en el almacenamiento en la nube.
curl -v -X GET "https://api.aspose.cloud/v4.0/words/Resultant.docx?format=TIFF&outPath=converted.tiff" \
-H "accept: application/octet-stream" \
-H "Authorization: Bearer <JWT Token>"
Conclusión
Realizar OCR en archivos PDF es un proceso crítico para desbloquear todo el potencial de estos documentos. Con la ayuda de herramientas de OCR basadas en la nube como Aspose.PDF Cloud SDK para Java, este proceso se puede simplificar y automatizar, ahorrando tiempo y aumentando la productividad. Al aprovechar el poder de OCR, las empresas y los desarrolladores pueden transformar archivos PDF basados en imágenes en archivos PDF con capacidad de búsqueda, lo que facilita su búsqueda, edición y uso compartido. Está claro que esta API ofrece una gama de potentes funciones y capacidades para trabajar con archivos PDF. Si sigue las guías paso a paso proporcionadas en este blog técnico, puede comenzar a usar OCR en archivos PDF y llevar su flujo de trabajo de documentos al siguiente nivel.
Puede considerar acceder a la API dentro de un navegador web usando la interfaz swagger. Además, como nuestros SDK se crean con una licencia MIT, el código fuente completo se puede descargar desde GitHub. En caso de que tenga algún problema al usar la API, no dude en comunicarse con nosotros a través del foro gratuito de soporte de productos.
Artículos relacionados
Recomendamos encarecidamente visitar los siguientes enlaces para obtener más información sobre: