
Konverter billed-PDF til søgbar PDF
I nutidens datadrevne verden er PDF’er blevet et uundværligt format til lagring og deling af dokumenter. Det er dog ikke alle PDF’er, der er let søgbare eller redigerbare, især dem, der er billedbaserede. Når man beskæftiger sig med dokumenter, er det virkelig svært at kopiere/udtrække tekstinformation til yderligere manipulation. Heldigvis kan du med kraften fra OCR-teknologi (Optical Character Recognition) nemt konvertere billed-PDF’er til søgbare PDF’er. I denne tekniske blog vil vi undersøge, hvordan man konverterer OCR PDF til søgbar PDF ved hjælp af forskellige teknikker, med et specifikt fokus på REST API. Vi vil også diskutere, hvordan du udtrækker tekst fra OCR PDF’er, hvilket giver dig en omfattende forståelse af, hvordan du kan udnytte OCR-teknologi til at frigøre det fulde potentiale af dine PDF-dokumenter.
- OCR PDF ved hjælp af Java SDK
- Scannet PDF til søgbar PDF ved hjælp af Java
- OCR Online ved hjælp af cURL-kommandoer
OCR PDF ved hjælp af Java SDK
Aspose.PDF Cloud SDK til Java er en kraftfuld cloud-baseret API, der tilbyder en bred vifte af funktioner og muligheder til at arbejde med PDF-dokumenter. En af dens nøglefunktioner er evnen til at udføre OCR på PDF’er, hvilket i høj grad kan forenkle processen med at udtrække tekst fra billedbaserede PDF’er og skabe søgbare PDF’er. Med sin brugervenlige grænseflade og omfattende dokumentation gør denne SDK det nemt at automatisere processen med at udføre OCR på PDF’er, hvilket sparer tid og øger produktiviteten.
Ydermere er denne cloud-baserede API designet til at håndtere en lang række inputformater og kan endda genkende håndskrevet tekst, hvilket gør den til et fremragende valg for virksomheder og udviklere, der ønsker at strømline deres dokumentarbejdsgang. Nu er det første skridt at tilføje sin reference i Java-projektet ved at tilføje følgende detaljer i pom.xml af maven build-projektet.
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>https://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
Hvis du ikke har en eksisterende konto, skal du oprette en gratis konto over Aspose Cloud. Log ind med en nyoprettet konto, og find/opret klient-id og klienthemmelighed på Cloud Dashboard. Disse detaljer er påkrævet i de efterfølgende afsnit.
Scannet PDF til søgbar PDF ved hjælp af Java
Dette afsnit forklarer detaljerne om, hvordan man konverterer scannet PDF til søgbar PDF ved hjælp af Java-kodestykke. Bemærk venligst, at Java Cloud SDK understøtter genkendelse af følgende sprog: eng, ara, bel, ben, bul, ces, dan, deu, ell, fin, fra, heb, hin, ind, isl, ita, jpn, kor, nld , nor, pol, por, ron, rus, spa, swe, tha, tur, ukr, vie, chisim, chitra eller deres kombination f.eks. eng,rus.
- Først skal vi oprette et objekt af PdfApi, hvor vi sender ClientID og Client hemmelige detaljer som argumenter
- For det andet skal du oprette en forekomst af File-klassen for at indlæse billed-PDF’en
- For det tredje skal du kalde metoden uploadFile(…) for at uploade input-PDFen til skylageret
- Da vores billed-PDF indeholder engelsk tekst, skal vi oprette et strengobjekt med værdien “eng”
- Kald endelig metoden putSearchableDocument(…), som kræver en input-PDF og en sprogkode som argumenter.
Når koden er eksekveret, gemmes den søgbare PDF i skylageret
try
{
// Få ClientID og ClientSecret fra https://dashboard.aspose.cloud/
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// oprette PdfApi instans
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// input billede PDF-dokument
String name = "ScannedPDF.pdf";
// Indlæs filen fra det lokale system
File file = new File(name);
// uploade filen til cloud storage
FilesUploadResult uploadResponse = pdfApi.uploadFile(name, file, null);
// de sprog, der bruges i billed-PDF
String lang = "eng";
// udføre OCR på billede PDF-dokument
AsposeResponse response = pdfApi.putSearchableDocument(name, null, null, lang);
// udskriv succesmeddelelse
System.out.println("OCR PDF successfull !");
}catch(Exception ex)
{
System.out.println(ex.getMessage());
}
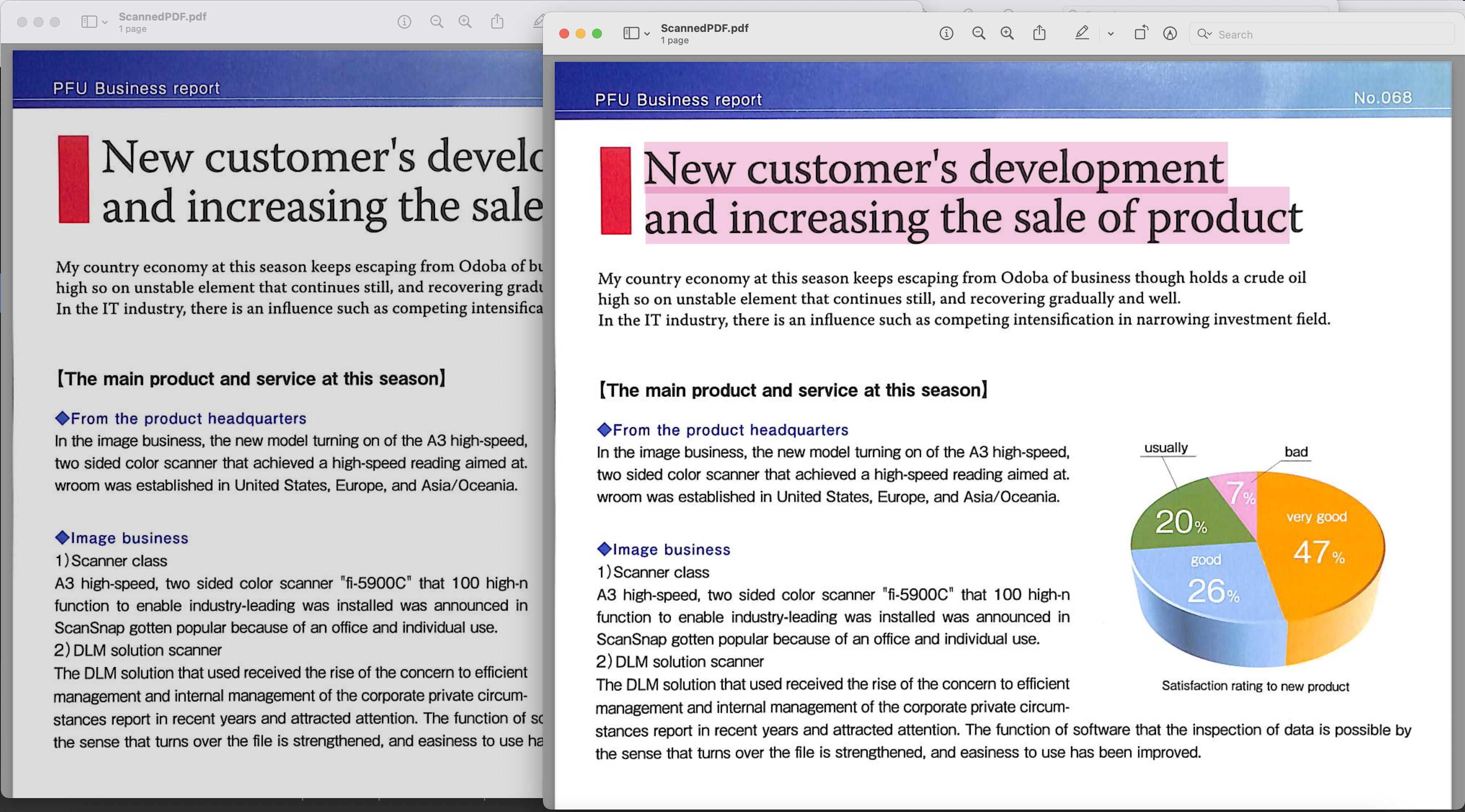
Billede 1: - Søgbar PDF-forhåndsvisning
Den scannede PDF, der er brugt i ovenstående eksempel, kan downloades fra BusinessReport.pdf og den resulterende søgbare PDF fra Converted.pdf
OCR Online ved hjælp af cURL-kommandoer
cURL-kommandoerne er en af de bekvemme metoder til at kalde REST API’erne. Så i dette afsnit skal vi bruge cURL-kommandoerne til OCR online. Nu, som en forudsætning, skal vi først generere et JWT-adgangstoken (baseret på klientoplysninger), mens vi udfører følgende kommando.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Når vi har JWT-token, bedes du bruge følgende kommando for at udføre OCR online og konvertere billed-PDF til søgbart PDF-dokument. Den resulterende fil gemmes derefter i skylageret.
curl -v -X GET "https://api.aspose.cloud/v4.0/words/Resultant.docx?format=TIFF&outPath=converted.tiff" \
-H "accept: application/octet-stream" \
-H "Authorization: Bearer <JWT Token>"
Konklusion
Udførelse af OCR på PDF’er er en kritisk proces for at frigøre det fulde potentiale af disse dokumenter. Ved hjælp af cloud-baserede OCR-værktøjer som Aspose.PDF Cloud SDK til Java kan denne proces forenkles og automatiseres, hvilket sparer tid og øger produktiviteten. Ved at udnytte kraften i OCR kan virksomheder og udviklere transformere billedbaserede PDF’er til søgbare PDF’er, hvilket gør dem nemmere at søge, redigere og dele. Det er tydeligt, at denne API tilbyder en række kraftfulde funktioner og muligheder for at arbejde med PDF’er. Ved at følge de trinvise vejledninger i denne tekniske blog, kan du komme i gang med OCR på PDF’er og tage din dokumentarbejdsgang til næste niveau.
Du kan overveje at få adgang til API’en i en webbrowser ved hjælp af swagger-grænsefladen. Da vores SDK’er er bygget under en MIT-licens, så kan den komplette kildekode downloades fra GitHub. Hvis du støder på problemer, mens du bruger API’en, er du velkommen til at kontakte os via gratis produktsupportforum.
relaterede artikler
Vi anbefaler stærkt, at du besøger følgende links for at lære mere om: