
将图像 PDF 转换为可搜索的 PDF
在当今数据驱动的世界中,PDF 已成为存储和共享文档不可或缺的格式。但是,并非所有 PDF 都易于搜索或编辑,尤其是那些基于图像的 PDF。在处理文档时,复制/提取任何文本信息以进行进一步操作确实很困难。幸运的是,借助光学字符识别 (OCR) 技术的强大功能,您可以轻松地将图像 PDF 转换为可搜索的 PDF。在此技术博客中,我们将探讨如何使用各种技术将 OCR PDF 转换为可搜索的 PDF,并特别关注 REST API。我们还将讨论如何从 OCR PDF 中提取文本,让您全面了解如何利用 OCR 技术来释放 PDF 文档的全部潜力。
使用 Java SDK 的 OCR PDF
Aspose.PDF Cloud SDK for Java 是一个强大的基于云的 API,它提供了广泛的处理 PDF 文档的特性和功能。其关键功能之一是能够对 PDF 执行 OCR,这可以大大简化从基于图像的 PDF 中提取文本和创建可搜索 PDF 的过程。凭借其友好的用户界面和全面的文档,此 SDK 可以轻松地自动执行对 PDF 执行 OCR 的过程,从而节省时间并提高工作效率。
此外,这个基于云的 API 旨在处理各种输入格式,甚至可以识别手写文本,使其成为希望简化文档工作流程的企业和开发人员的绝佳选择。现在第一步是通过在 maven 构建项目的 pom.xml 中添加以下详细信息来在 Java 项目中添加它的引用。
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>https://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
如果您没有现有帐户,则需要通过 Aspose Cloud 创建一个免费帐户。使用新创建的帐户登录,并在 Cloud Dashboard 中查找/创建客户端 ID 和客户端密码。后续部分需要这些详细信息。
使用 Java 将扫描的 PDF 转换为可搜索的 PDF
本节详细介绍了如何使用 Java 代码片段将扫描的 PDF 转换为可搜索的 PDF。请注意,Java Cloud SDK 支持识别以下语言:eng、ara、bel、ben、bul、ces、dan、deu、ell、fin、fra、heb、hin、ind、isl、ita、jpn、kor、nld , nor, pol, por, ron, rus, spa, swe, tha, tur, ukr, vie, chisim, chitra 或其组合,例如 eng,rus。
- 首先我们需要创建一个 PdfApi 对象,我们将 ClientID 和 Client secret 详细信息作为参数传递给它
- 其次,创建一个 File 类的实例来加载 Image PDF
- 第三,调用uploadFile(…)方法将输入的PDF上传到云存储
- 由于我们的图像 PDF 包含英文文本,因此我们需要创建一个字符串对象,其值为“eng”
- 最后,调用方法 putSearchableDocument(…),它需要一个输入 PDF 和一个语言代码作为参数。
一旦成功执行代码,可搜索的 PDF 将存储在云存储中
try
{
// 从 https://dashboard.aspose.cloud/ 获取 ClientID 和 ClientSecret
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// 创建PdfApi实例
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// 输入图像 PDF 文档
String name = "ScannedPDF.pdf";
// 从本地系统加载文件
File file = new File(name);
// 上传文件到云存储
FilesUploadResult uploadResponse = pdfApi.uploadFile(name, file, null);
// 图片PDF中使用的语言
String lang = "eng";
// 对图像 PDF 文档执行 OCR
AsposeResponse response = pdfApi.putSearchableDocument(name, null, null, lang);
// 打印成功信息
System.out.println("OCR PDF successfull !");
}catch(Exception ex)
{
System.out.println(ex.getMessage());
}
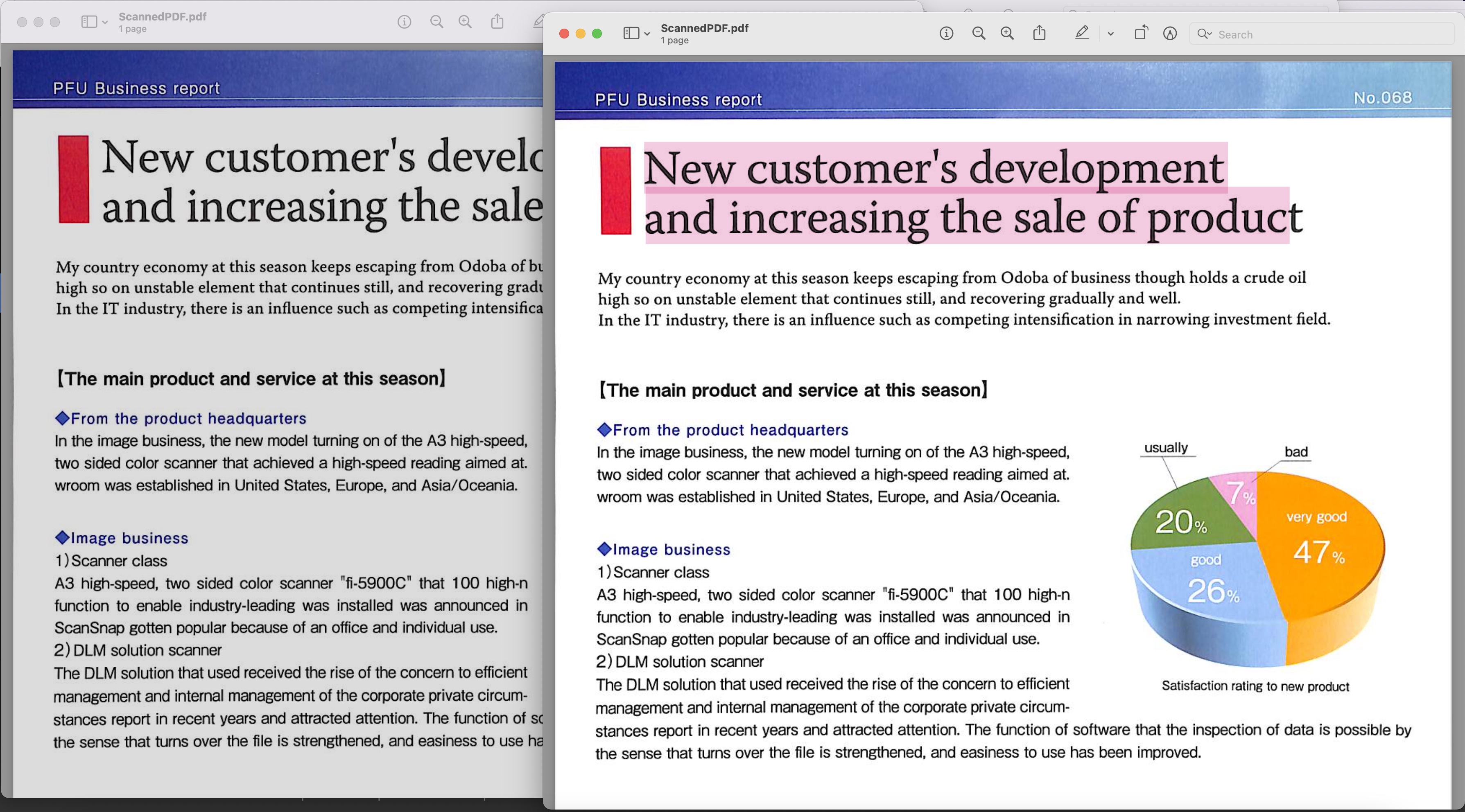
图 1:- 可搜索的 PDF 预览
上例中使用的扫描 PDF 可从 BusinessReport.pdf 下载,生成的可搜索 PDF 可从 Converted.pdf 下载
OCR Online 使用 cURL 命令
cURL 命令是调用 REST API 的便捷方法之一。因此,在本节中,我们将使用 cURL 命令在线进行 OCR。现在,作为先决条件,我们需要在执行以下命令时首先生成 JWT 访问令牌(基于客户端凭据)。
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
一旦我们有了 JWT 令牌,请执行以下命令在线执行 OCR 并将图像 PDF 转换为可搜索的 PDF 文档。然后将生成的文件存储在云存储中。
curl -v -X GET "https://api.aspose.cloud/v4.0/words/Resultant.docx?format=TIFF&outPath=converted.tiff" \
-H "accept: application/octet-stream" \
-H "Authorization: Bearer <JWT Token>"
结论
对 PDF 执行 OCR 是释放这些文档全部潜力的关键过程。借助 Aspose.PDF Cloud SDK for Java 等基于云的 OCR 工具,可以简化和自动化此过程,从而节省时间并提高工作效率。通过利用 OCR 的强大功能,企业和开发人员可以将基于图像的 PDF 转换为可搜索的 PDF,使它们更易于搜索、编辑和共享。很明显,此 API 提供了一系列处理 PDF 的强大特性和功能。按照本技术博客中提供的分步指南,您可以开始在 PDF 上使用 OCR,并将您的文档工作流程提升到一个新的水平。
您可以考虑使用 swagger 界面 在 Web 浏览器中访问 API。此外,由于我们的 SDK 是在 MIT 许可证下构建的,因此可以从 GitHub 下载完整的源代码。如果您在使用 API 时遇到任何问题,请随时通过免费产品支持论坛 与我们联系。
相关文章
我们强烈建议访问以下链接以了解更多信息: