
Pretvorite slikovni PDF u pretraživi PDF
U današnjem svijetu koji se temelji na podacima, PDF-ovi postali su nezamjenjiv format za pohranu i dijeljenje dokumenata. Međutim, nisu svi PDF-ovi lako pretraživi ili uređivani, osobito oni koji se temelje na slikama. Kada se radi o dokumentima, stvarno je teško kopirati/izdvojiti bilo koju tekstualnu informaciju za daljnju manipulaciju. Srećom, sa snagom tehnologije optičkog prepoznavanja znakova (OCR), možete s lakoćom pretvoriti slikovne PDF-ove u PDF-ove koji se mogu pretraživati. U ovom tehničkom blogu istražit ćemo kako pretvoriti OCR PDF u PDF koji se može pretraživati pomoću različitih tehnika, s posebnim fokusom na REST API. Također ćemo raspravljati o tome kako izdvojiti tekst iz OCR PDF-ova, dajući vam sveobuhvatno razumijevanje kako iskoristiti OCR tehnologiju da otključate puni potencijal svojih PDF dokumenata.
- OCR PDF pomoću Java SDK-a
- Skenirani PDF u PDF koji se može pretraživati pomoću Jave
- OCR na mreži pomoću cURL naredbi
OCR PDF pomoću Java SDK-a
Aspose.PDF Cloud SDK za Javu moćan je API temeljen na oblaku koji nudi širok raspon značajki i mogućnosti za rad s PDF dokumentima. Jedna od njegovih ključnih funkcionalnosti je mogućnost izvođenja OCR-a na PDF-ovima, što može uvelike pojednostaviti proces izdvajanja teksta iz PDF-ova temeljenih na slikama i stvaranje PDF-ova koji se mogu pretraživati. Sa svojim sučeljem prilagođenim korisniku i sveobuhvatnom dokumentacijom, ovaj SDK olakšava automatizaciju procesa izvođenja OCR-a na PDF-ovima, štedeći vrijeme i povećavajući produktivnost.
Nadalje, ovaj API temeljen na oblaku dizajniran je za rukovanje širokim spektrom formata unosa i može čak prepoznati rukom pisani tekst, što ga čini izvrsnim izborom za tvrtke i programere koji žele pojednostaviti tijek rada s dokumentima. Sada je prvi korak dodavanje njegove reference u Java projekt dodavanjem sljedećih detalja u pom.xml maven build projekta.
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>http://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
Ako nemate postojeći račun, trebate kreirati besplatni račun preko Aspose Cloud. Prijavite se pomoću novostvorenog računa i potražite/izradite ID klijenta i tajnu klijenta na Cloud Dashboard. Ovi detalji su potrebni u sljedećim odjeljcima.
Skenirani PDF u PDF koji se može pretraživati pomoću Jave
Ovaj odjeljak objašnjava pojedinosti o tome kako pretvoriti skenirani PDF u PDF koji se može pretraživati pomoću isječka Java koda. Imajte na umu da Java Cloud SDK podržava prepoznavanje sljedećih jezika: eng, ara, bel, ben, bul, ces, dan, deu, ell, fin, fra, heb, hin, ind, isl, ita, jpn, kor, nld , nor, pol, por, ron, rus, spa, swe, tha, tur, ukr, vie, chisim, chitra ili njihova kombinacija npr. eng,rus.
- Prvo moramo stvoriti objekt PdfApi, gdje prosljeđujemo ClientID i Client tajne detalje kao argumente
- Drugo, stvorite instancu klase File za učitavanje slikovnog PDF-a
- Treće, pozovite metodu uploadFile(…) za učitavanje ulaznog PDF-a u pohranu u oblaku
- Budući da naš slikovni PDF sadrži engleski tekst, moramo stvoriti string objekt koji ima vrijednost “eng”
- Na kraju, pozovite metodu putSearchableDocument(…), koja zahtijeva ulazni PDF i jezični kod kao argumente.
Nakon što se kôd uspješno izvrši, PDF koji se može pretraživati pohranjuje se u pohranu u oblaku
try
{
// Dobijte ClientID i ClientSecret s https://dashboard.aspose.cloud/
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// createPdfApi instanca
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// ulazna slika PDF dokument
String name = "ScannedPDF.pdf";
// Učitajte datoteku s lokalnog sustava
File file = new File(name);
// prenesite datoteku u pohranu u oblaku
FilesUploadResult uploadResponse = pdfApi.uploadFile(name, file, null);
// jezici koji se koriste u slikovnom PDF-u
String lang = "eng";
// izvršite OCR na slikovnom PDF dokumentu
AsposeResponse response = pdfApi.putSearchableDocument(name, null, null, lang);
// ispis poruke o uspjehu
System.out.println("OCR PDF successfull !");
}catch(Exception ex)
{
System.out.println(ex.getMessage());
}
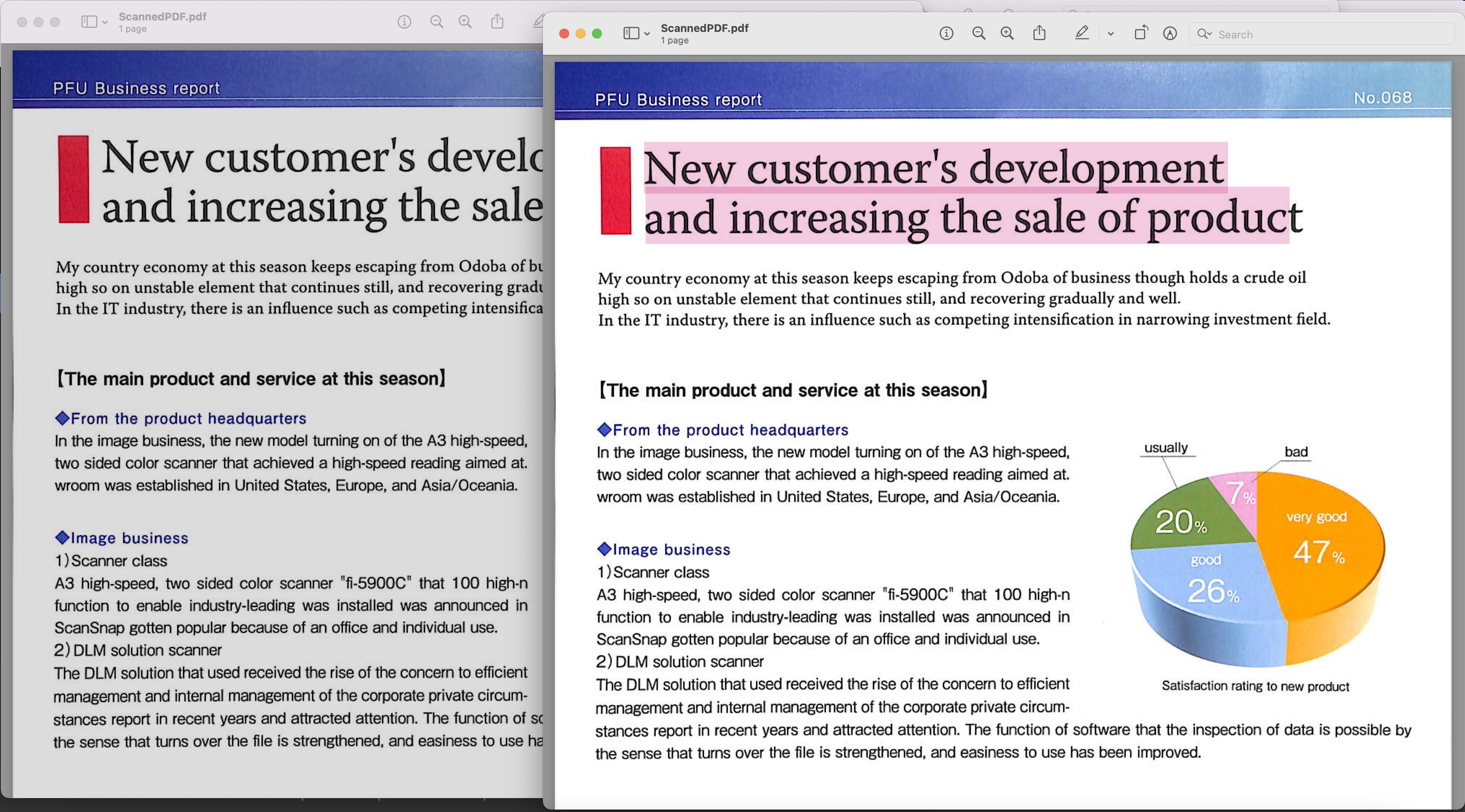
Slika 1: - Pregled PDF-a koji se može pretraživati
Skenirani PDF korišten u gornjem primjeru može se preuzeti s BusinessReport.pdf, a dobiveni pretraživi PDF s Converted.pdf
OCR na mreži pomoću cURL naredbi
Naredbe cURL jedan su od prikladnih pristupa za pozivanje REST API-ja. Stoga ćemo u ovom odjeljku koristiti naredbe cURL za OCR online. Sada, kao preduvjet, prvo moramo generirati JWT pristupni token (na temelju vjerodajnica klijenta) dok izvršavamo sljedeću naredbu.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Nakon što dobijemo JWT token, molimo sljedeću naredbu za izvođenje OCR-a online i pretvaranje slikovnog PDF-a u pretraživi PDF dokument. Rezultirajuća datoteka se zatim pohranjuje u pohranu u oblaku.
curl -v -X GET "https://api.aspose.cloud/v4.0/words/Resultant.docx?format=TIFF&outPath=converted.tiff" \
-H "accept: application/octet-stream" \
-H "Authorization: Bearer <JWT Token>"
Zaključak
Izvođenje OCR-a na PDF-ovima kritičan je proces za otključavanje punog potencijala ovih dokumenata. Uz pomoć OCR alata koji se temelje na oblaku kao što je Aspose.PDF Cloud SDK za Javu, ovaj se proces može pojednostaviti i automatizirati, štedeći vrijeme i povećavajući produktivnost. Iskorištavanjem snage OCR-a, tvrtke i programeri mogu transformirati PDF-ove temeljene na slikama u PDF-ove koji se mogu pretraživati, čineći ih lakšim za pretraživanje, uređivanje i dijeljenje. Jasno je da ovaj API nudi niz snažnih značajki i mogućnosti za rad s PDF-ovima. Slijedeći vodiče korak po korak navedene u ovom tehničkom blogu, možete započeti s OCR-om na PDF-ovima i podići tijek rada s dokumentima na višu razinu.
Možete razmisliti o pristupu API-ju unutar web-preglednika pomoću swagger sučelja. Nadalje, budući da su naši SDK-ovi izgrađeni pod licencom MIT-a, kompletan izvorni kod može se preuzeti s GitHub. U slučaju da naiđete na bilo kakve probleme tijekom korištenja API-ja, slobodno nas kontaktirajte putem besplatnog foruma za podršku proizvoda.
povezani članci
Preporučujemo da posjetite sljedeće veze kako biste saznali više o: