
I-convert ang Image PDF sa Searchable PDF
Sa mundong hinihimok ng data ngayon, ang PDFs ay naging isang kailangang-kailangan na format para sa pag-iimbak at pagbabahagi ng mga dokumento. Gayunpaman, hindi lahat ng PDF ay madaling nahahanap o nae-edit, lalo na ang mga nakabatay sa imahe. Kapag nakikitungo sa mga dokumento, talagang mahirap kopyahin/i-extract ang anumang impormasyong teksto para sa karagdagang pagmamanipula. Sa kabutihang palad, sa kapangyarihan ng teknolohiyang Optical Character Recognition (OCR), maaari mong i-convert ang mga PDF ng imahe sa mga mahahanap na PDF nang madali. Sa teknikal na blog na ito, tutuklasin namin kung paano i-convert ang OCR PDF sa mahahanap na PDF gamit ang iba’t ibang mga diskarte, na may partikular na pagtuon sa REST API. Tatalakayin din namin kung paano mag-extract ng text mula sa mga OCR PDF, na nagbibigay sa iyo ng komprehensibong pag-unawa sa kung paano gamitin ang teknolohiya ng OCR upang i-unlock ang buong potensyal ng iyong mga PDF na dokumento.
- OCR PDF gamit ang Java SDK
- Na-scan na PDF sa Mahahanap na PDF gamit ang Java
- OCR Online gamit ang cURL Commands
OCR PDF gamit ang Java SDK
Ang Aspose.PDF Cloud SDK para sa Java ay isang malakas na cloud-based na API na nag-aalok ng malawak na hanay ng mga feature at kakayahan para sa pagtatrabaho sa mga PDF na dokumento. Ang isa sa mga pangunahing pag-andar nito ay ang kakayahang magsagawa ng OCR sa mga PDF, na maaaring lubos na gawing simple ang proseso ng pagkuha ng teksto mula sa mga PDF na nakabatay sa imahe at paglikha ng mga mahahanap na PDF. Gamit ang user-friendly na interface at komprehensibong dokumentasyon, ginagawang madali ng SDK na ito na i-automate ang proseso ng pagsasagawa ng OCR sa mga PDF, makatipid ng oras at mapapataas ang produktibidad.
Higit pa rito, ang cloud-based na API na ito ay idinisenyo upang pangasiwaan ang isang malawak na iba’t ibang mga format ng pag-input at maaari pa ngang makilala ang sulat-kamay na teksto, na ginagawa itong isang mahusay na pagpipilian para sa mga negosyo at mga developer na naghahanap upang i-streamline ang kanilang daloy ng trabaho sa dokumento. Ngayon ang unang hakbang ay idagdag ang sanggunian nito sa proyekto ng Java sa pamamagitan ng pagdaragdag ng mga sumusunod na detalye sa pom.xml ng maven build project.
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>http://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
Kung wala kang kasalukuyang account, kailangan mong gumawa ng libreng account sa Aspose Cloud. Mag-login gamit ang bagong likhang account at maghanap/lumikha ng Client ID at Client Secret sa Cloud Dashboard. Ang mga detalyeng ito ay kinakailangan sa mga susunod na seksyon.
Na-scan na PDF sa Mahahanap na PDF gamit ang Java
Ipinapaliwanag ng seksyong ito ang mga detalye kung paano i-convert ang na-scan na PDF sa Searchable PDF gamit ang Java code snippet. Pakitandaan na sinusuportahan ng Java Cloud SDK ang pagkilala sa mga sumusunod na wika: eng, ara, bel, ben, bul, ces, dan, deu, ell, fin, fra, heb, hin, ind, isl, ita, jpn, kor, nld , nor, pol, por, ron, rus, spa, swe, tha, tur, ukr, vie, chisim, chitra o kanilang kumbinasyon hal eng,rus.
- Una kailangan naming lumikha ng isang bagay ng PdfApi, kung saan ipinapasa namin ang mga lihim na detalye ng ClientID at Client bilang mga argumento
- Pangalawa, lumikha ng isang halimbawa ng klase ng File upang mai-load ang Image PDF
- Pangatlo, tawagan ang paraan na uploadFile(…) para i-upload ang input na PDF sa cloud storage
- Dahil ang aming imaheng PDF ay naglalaman ng ingles na teksto, kaya kailangan naming lumikha ng isang string object na may hawak na halaga na “eng”
- Panghuli, tawagan ang paraan na putSearchableDocument(…), na nangangailangan ng input na PDF at isang language code bilang mga argumento.
Kapag ang code ay matagumpay na naisakatuparan, ang nahahanap na PDF ay iniimbak sa cloud storage
try
{
// Kumuha ng ClientID at ClientSecret mula sa https://dashboard.aspose.cloud/
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// createPdfApi instance
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// pag-input ng imaheng PDF na dokumento
String name = "ScannedPDF.pdf";
// I-load ang file mula sa lokal na sistema
File file = new File(name);
// i-upload ang file sa cloud storage
FilesUploadResult uploadResponse = pdfApi.uploadFile(name, file, null);
// ang mga wikang ginamit sa larawang PDF
String lang = "eng";
// isagawa ang OCR sa imaheng PDF na dokumento
AsposeResponse response = pdfApi.putSearchableDocument(name, null, null, lang);
// i-print ang mensahe ng tagumpay
System.out.println("OCR PDF successfull !");
}catch(Exception ex)
{
System.out.println(ex.getMessage());
}
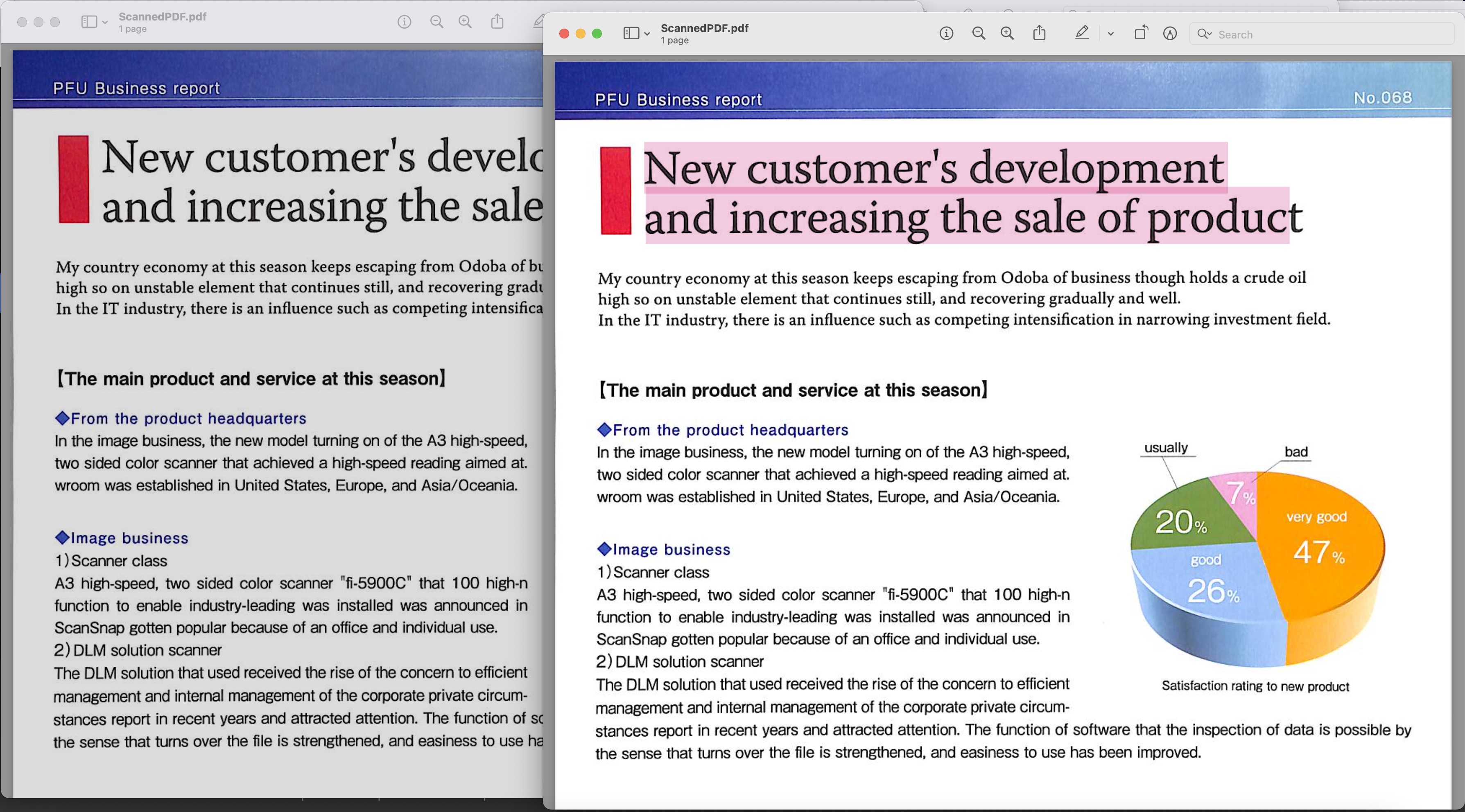
Imahe1:- Nahahanap na PDF preview
Ang na-scan na PDF na ginamit sa halimbawa sa itaas ay maaaring i-download mula sa BusinessReport.pdf at ang resultang mahahanap na PDF mula sa Converted.pdf
OCR Online gamit ang cURL Commands
Ang mga utos ng cURL ay isa sa mga maginhawang paraan upang tawagan ang mga REST API. Kaya sa seksyong ito, gagamitin namin ang mga cURL command para sa OCR online. Ngayon, bilang isang kinakailangan, kailangan muna nating bumuo ng isang JWT access token (batay sa mga kredensyal ng kliyente) habang isinasagawa ang sumusunod na command.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Kapag mayroon na kaming JWT token, mangyaring ang sumusunod na command upang magsagawa ng OCR online at i-convert ang Image PDF sa mahahanap na PDF na dokumento. Ang resultang file ay iniimbak sa cloud storage.
curl -v -X GET "https://api.aspose.cloud/v4.0/words/Resultant.docx?format=TIFF&outPath=converted.tiff" \
-H "accept: application/octet-stream" \
-H "Authorization: Bearer <JWT Token>"
Konklusyon
Ang pagsasagawa ng OCR sa mga PDF ay isang kritikal na proseso para ma-unlock ang buong potensyal ng mga dokumentong ito. Sa tulong ng cloud-based na mga tool sa OCR tulad ng Aspose.PDF Cloud SDK para sa Java, ang prosesong ito ay maaaring gawing simple at awtomatiko, makatipid ng oras at mapataas ang pagiging produktibo. Sa pamamagitan ng paggamit ng kapangyarihan ng OCR, maaaring baguhin ng mga negosyo at developer ang mga PDF na nakabatay sa larawan sa mga mahahanap na PDF, na ginagawang mas madali itong maghanap, mag-edit, at magbahagi. Malinaw na nag-aalok ang API na ito ng isang hanay ng mga mahuhusay na feature at kakayahan para sa pagtatrabaho sa mga PDF. Sa pamamagitan ng pagsunod sa mga sunud-sunod na gabay na ibinigay sa teknikal na blog na ito, maaari kang magsimula sa OCR sa mga PDF at dalhin ang iyong daloy ng trabaho sa dokumento sa susunod na antas.
Maaari mong isaalang-alang ang pag-access sa API sa loob ng isang web browser gamit ang swagger interface. Higit pa rito, dahil ang aming mga SDK ay binuo sa ilalim ng lisensya ng MIT, kaya ang kumpletong source code ay maaaring ma-download mula sa GitHub. Kung sakaling makatagpo ka ng anumang mga isyu habang ginagamit ang API, mangyaring huwag mag-atubiling makipag-ugnayan sa amin sa pamamagitan ng free product support forum.
Mga Kaugnay na Artikulo
Lubos naming inirerekumenda ang pagbisita sa mga sumusunod na link upang matuto nang higit pa tungkol sa: