
Converteer afbeeldings-PDF naar doorzoekbare PDF
In de huidige datagestuurde wereld zijn PDF’s een onmisbaar formaat geworden voor het opslaan en delen van documenten. Niet alle pdf’s zijn echter gemakkelijk doorzoekbaar of bewerkbaar, vooral niet alle pdf’s die op afbeeldingen zijn gebaseerd. Bij het omgaan met documenten is het erg moeilijk om tekstuele informatie te kopiëren/extraheren voor verdere manipulatie. Gelukkig kunt u met de kracht van Optical Character Recognition (OCR)-technologie eenvoudig afbeeldings-pdf’s converteren naar doorzoekbare pdf’s. In deze technische blog zullen we onderzoeken hoe OCR PDF naar doorzoekbare PDF kan worden geconverteerd met behulp van verschillende technieken, met een specifieke focus op REST API. We zullen ook bespreken hoe u tekst uit OCR-pdf’s kunt extraheren, zodat u uitgebreid begrijpt hoe u OCR-technologie kunt gebruiken om het volledige potentieel van uw PDF-documenten te benutten.
- OCR PDF met behulp van Java SDK
- Gescande PDF naar doorzoekbare PDF met Java
- OCR Online met cURL-opdrachten
OCR PDF met behulp van Java SDK
Aspose.PDF Cloud SDK voor Java is een krachtige cloudgebaseerde API die een breed scala aan functies en mogelijkheden biedt voor het werken met PDF-documenten. Een van de belangrijkste functionaliteiten is de mogelijkheid om OCR op PDF’s uit te voeren, wat het proces van het extraheren van tekst uit op afbeeldingen gebaseerde PDF’s en het maken van doorzoekbare PDF’s aanzienlijk kan vereenvoudigen. Met zijn gebruiksvriendelijke interface en uitgebreide documentatie maakt deze SDK het gemakkelijk om het proces van het uitvoeren van OCR op PDF’s te automatiseren, waardoor tijd wordt bespaard en de productiviteit wordt verhoogd.
Bovendien is deze cloudgebaseerde API ontworpen om een breed scala aan invoerformaten aan te kunnen en kan zelfs handgeschreven tekst herkennen, waardoor het een uitstekende keuze is voor bedrijven en ontwikkelaars die hun documentworkflow willen stroomlijnen. Nu is de eerste stap het toevoegen van de referentie in het Java-project door de volgende details toe te voegen in pom.xml van het maven build-project.
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>http://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
Als u geen bestaand account heeft, moet u een gratis account aanmaken via Aspose Cloud. Log in met een nieuw aangemaakt account en zoek/maak Client ID en Client Secret op bij Cloud Dashboard. Deze details zijn vereist in volgende secties.
Gescande PDF naar doorzoekbare PDF met Java
In dit gedeelte worden de details uitgelegd over het converteren van gescande PDF naar doorzoekbare PDF met behulp van een Java-codefragment. Houd er rekening mee dat Java Cloud SDK de herkenning van de volgende talen ondersteunt: eng, ara, bel, ben, bul, ces, dan, deu, ell, fin, fra, heb, hin, ind, isl, ita, jpn, kor, nld , noch, pol, por, ron, rus, spa, swe, tha, tur, ukr, vie, chisim, chitra of hun combinatie, bijv. eng,rus.
- Eerst moeten we een object van PdfApi maken, waar we ClientID en Client geheime details als argumenten doorgeven
- Maak ten tweede een instantie van de klasse File om de afbeeldings-PDF te laden
- Roep ten derde de methode uploadFile(…) aan om de invoer-PDF naar de cloudopslag te uploaden
- Omdat onze afbeeldings-PDF Engelse tekst bevat, moeten we dus een tekenreeksobject maken met de waarde “eng”
- Roep ten slotte de methode putSearchableDocument(…) aan, die een invoer-PDF en een taalcode als argumenten vereist.
Zodra de code met succes is uitgevoerd, wordt de doorzoekbare PDF opgeslagen in cloudopslag
try
{
// Haal ClientID en ClientSecret op van https://dashboard.aspose.cloud/
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// createPdfApi-instantie
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// invoer afbeelding PDF-document
String name = "ScannedPDF.pdf";
// Laad het bestand vanaf het lokale systeem
File file = new File(name);
// upload het bestand naar cloudopslag
FilesUploadResult uploadResponse = pdfApi.uploadFile(name, file, null);
// de talen die worden gebruikt in afbeelding PDF
String lang = "eng";
// voer de OCR uit op het PDF-afbeeldingsdocument
AsposeResponse response = pdfApi.putSearchableDocument(name, null, null, lang);
// succesbericht afdrukken
System.out.println("OCR PDF successfull !");
}catch(Exception ex)
{
System.out.println(ex.getMessage());
}
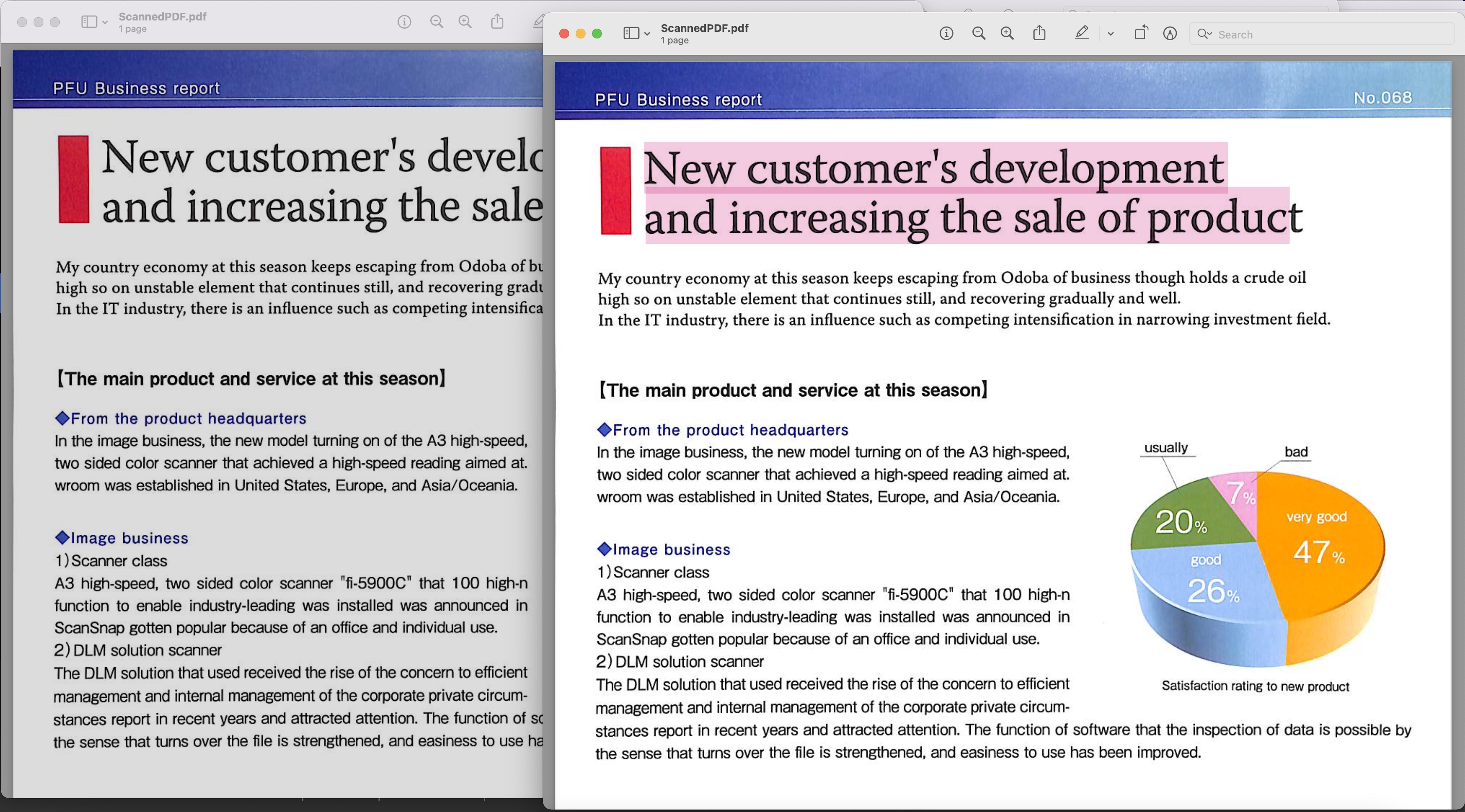
Image1: - Doorzoekbaar PDF-voorbeeld
De gescande pdf die in het bovenstaande voorbeeld wordt gebruikt, kan worden gedownload van BusinessReport.pdf en de resulterende doorzoekbare pdf van Converted.pdf
OCR Online met cURL-opdrachten
De cURL-opdrachten zijn een van de handige benaderingen om de REST API’s aan te roepen. Dus in dit gedeelte gaan we de cURL-opdrachten voor OCR online gebruiken. Nu moeten we als vereiste eerst een JWT-toegangstoken genereren (op basis van clientreferenties) terwijl we de volgende opdracht uitvoeren.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Zodra we het JWT-token hebben, voert u de volgende opdracht uit om OCR online uit te voeren en Image PDF te converteren naar een doorzoekbaar PDF-document. Het resulterende bestand wordt vervolgens opgeslagen in cloudopslag.
curl -v -X GET "https://api.aspose.cloud/v4.0/words/Resultant.docx?format=TIFF&outPath=converted.tiff" \
-H "accept: application/octet-stream" \
-H "Authorization: Bearer <JWT Token>"
Conclusie
Het uitvoeren van OCR op PDF’s is een cruciaal proces om het volledige potentieel van deze documenten te ontsluiten. Met behulp van op de cloud gebaseerde OCR-tools zoals Aspose.PDF Cloud SDK voor Java kan dit proces worden vereenvoudigd en geautomatiseerd, wat tijd bespaart en de productiviteit verhoogt. Door gebruik te maken van de kracht van OCR kunnen bedrijven en ontwikkelaars op afbeeldingen gebaseerde PDF’s omzetten in doorzoekbare PDF’s, waardoor ze gemakkelijker kunnen worden doorzocht, bewerkt en gedeeld. Het is duidelijk dat deze API een reeks krachtige functies en mogelijkheden biedt voor het werken met PDF’s. Door de stapsgewijze handleidingen in deze technische blog te volgen, kunt u aan de slag gaan met OCR op PDF’s en uw documentworkflow naar een hoger niveau tillen.
U kunt overwegen toegang te krijgen tot de API in een webbrowser met behulp van de swagger-interface. Bovendien, aangezien onze SDK’s zijn gebouwd onder een MIT-licentie, kan de volledige broncode worden gedownload van GitHub. Als u problemen ondervindt tijdens het gebruik van de API, neem dan gerust contact met ons op via gratis productondersteuningsforum.
gerelateerde artikelen
We raden u ten zeerste aan de volgende links te bezoeken voor meer informatie over: