
चित्र PDF अन्वेषणीय PDF मध्ये परिवर्तयन्तु
अद्यतनदत्तांशसञ्चालितजगति PDFs दस्तावेजानां संग्रहणार्थं साझेदारीार्थं च अनिवार्यं प्रारूपं जातम् । परन्तु सर्वाणि PDF-पत्राणि सुलभतया अन्वेष्टुं सम्पादनीयानि वा न भवन्ति, विशेषतः ये चित्राधारिताः सन्ति । दस्तावेजानां व्यवहारे, अग्रे हेरफेरार्थं कस्यापि पाठ्यसूचनायाः प्रतिलिपिं/निष्कासनं वास्तवतः कठिनम् अस्ति । सौभाग्येन ऑप्टिकल कैरेक्टर् रिकग्निशन (OCR) प्रौद्योगिक्याः शक्तिना भवान् इमेज पीडीएफ इत्येतत् सहजतया अन्वेषणीयपीडीएफ इत्यत्र परिवर्तयितुं शक्नोति । अस्मिन् तकनीकीब्लॉग् मध्ये वयं REST API इत्यत्र विशिष्टं ध्यानं दत्त्वा, विभिन्नानां तकनीकानां उपयोगेन OCR PDF इत्येतत् अन्वेषणीयं PDF इत्यत्र कथं परिवर्तयितुं शक्यते इति अन्वेषयिष्यामः । वयं OCR PDFs तः पाठं कथं निष्कासयितुं शक्यते इति अपि चर्चां करिष्यामः, येन भवान् स्वस्य PDF दस्तावेजानां पूर्णक्षमताम् अनलॉक् कर्तुं OCR प्रौद्योगिक्याः लाभं कथं ग्रहीतुं शक्यते इति व्यापकं अवगमनं प्राप्नुमः।
- जावा SDK इत्यस्य उपयोगेन OCR PDF
- जावा इत्यस्य उपयोगेन PDF इत्येतत् Searchable PDF इत्यत्र स्कैन् कृतम्
- cURL Commands इत्यस्य उपयोगेन OCR Online
जावा SDK इत्यस्य उपयोगेन OCR PDF
Aspose.PDF Cloud SDK for Java इति एकः शक्तिशाली क्लाउड्-आधारितः एपिआइ अस्ति यः PDF दस्तावेजैः सह कार्यं कर्तुं विस्तृतं विशेषतां क्षमतां च प्रदाति । अस्य एकं मुख्यकार्यक्षमता पीडीएफ-मध्ये OCR-करणस्य क्षमता अस्ति, यत् चित्राधारित-पीडीएफ-तः पाठं निष्कासयितुं, अन्वेषणीय-पीडीएफ-निर्माणस्य प्रक्रियां बहु सरलीकर्तुं शक्नोति उपयोक्तृ-अनुकूल-अन्तरफलकेन व्यापक-दस्तावेजेन च एतत् SDK PDF-इत्यत्र OCR-करणस्य प्रक्रियां स्वचालितं कर्तुं सुलभं करोति, समयस्य रक्षणं करोति, उत्पादकताम् वर्धयति च
अपि च, एतत् मेघ-आधारितं एपिआइ विस्तृतविविधनिवेशस्वरूपं नियन्त्रयितुं विनिर्मितम् अस्ति तथा च हस्तलिखितं पाठं अपि ज्ञातुं शक्नोति, येन स्वदस्तावेजकार्यप्रवाहं सुव्यवस्थितं कर्तुं इच्छन्तीनां व्यवसायानां विकासकानां च कृते उत्तमः विकल्पः भवति अधुना प्रथमं सोपानं maven build project इत्यस्य pom.xml इत्यस्मिन् निम्नलिखितविवरणं योजयित्वा Java project इत्यस्मिन् तस्य reference योजयितुं भवति ।
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>http://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
यदि भवतां समीपे विद्यमानं खातं नास्ति तर्हि Aspose Cloud इत्यस्य उपरि निःशुल्कं खातं निर्मातव्यम् । नवनिर्मित खातेः उपयोगेन प्रवेशं कुर्वन्तु तथा च Cloud Dashboard इत्यत्र Client ID तथा Client Secret इत्येतत् पश्यन्तु/निर्माणं कुर्वन्तु । एते विवरणाः अनन्तरखण्डेषु आवश्यकाः सन्ति ।
जावा इत्यस्य उपयोगेन PDF इत्येतत् Searchable PDF इत्यत्र स्कैन् कृतम्
अस्मिन् खण्डे Java code snippet इत्यस्य उपयोगेन स्कैन् कृतं PDF इत्येतत् Searchable PDF इत्यत्र कथं परिवर्तयितुं शक्यते इति विवरणं व्याख्यायते । कृपया ज्ञातव्यं यत् Java Cloud SDK निम्नलिखितभाषानां मान्यतां समर्थयति: eng, ara, bel, ben, bul, ces, dan, deu, ell, fin, fra, heb, hin, ind, isl, ita, jpn, kor, nld , न, पोल, पोर, रोन्, रुस, स्पा, स्वे, था, तुर, उक्र, विये, चिसिं, चित्रा वा तेषां संयोजनं यथा एङ्ग,रुस्।
- प्रथमं अस्माभिः PdfApi इत्यस्य एकं ऑब्जेक्ट् निर्मातव्यं, यत्र वयं ClientID तथा Client secret details इत्येतौ आर्गुमेण्ट् रूपेण पारयामः
- द्वितीयं, Image PDF लोड् कर्तुं File class इत्यस्य instance रचयन्तु
- तृतीयम्, input PDF इत्येतत् cloud storage इत्यत्र अपलोड् कर्तुं uploadFile(…) इति मेथड् आह्वयन्तु
- यथा अस्माकं इमेज PDF मध्ये english text अस्ति, अतः अस्माभिः “eng” इति मूल्यं धारयन् string object निर्मातव्यम् ।
- अन्ते putSearchableDocument(…) इति मेथड् आह्वयन्तु, यस्य कृते आर्गुमेण्ट् रूपेण इनपुट् PDF तथा भाषा कोड् आवश्यकम् अस्ति ।
एकदा कोडः सफलतया निष्पादितः जातः तदा अन्वेषणीयः PDF मेघभण्डारणस्थाने संगृहीतः भवति
try
{
// https://dashboard.aspose.cloud/ इत्यस्मात् ClientID तथा ClientSecret प्राप्तुं शक्नुवन्ति।
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// createPdfApi उदाहरणम्
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// input image PDF दस्तावेज़
String name = "ScannedPDF.pdf";
// स्थानीयप्रणाल्याः सञ्चिकां लोड् कुर्वन्तु
File file = new File(name);
// सञ्चिकां मेघभण्डारणस्थाने अपलोड् कुर्वन्तु
FilesUploadResult uploadResponse = pdfApi.uploadFile(name, file, null);
// इमेज PDF इत्यस्मिन् प्रयुक्ताः भाषाः
String lang = "eng";
// इमेज PDF दस्तावेजे OCR करणीयम्
AsposeResponse response = pdfApi.putSearchableDocument(name, null, null, lang);
// सफलता सन्देशं मुद्रयन्तु
System.out.println("OCR PDF successfull !");
}catch(Exception ex)
{
System.out.println(ex.getMessage());
}
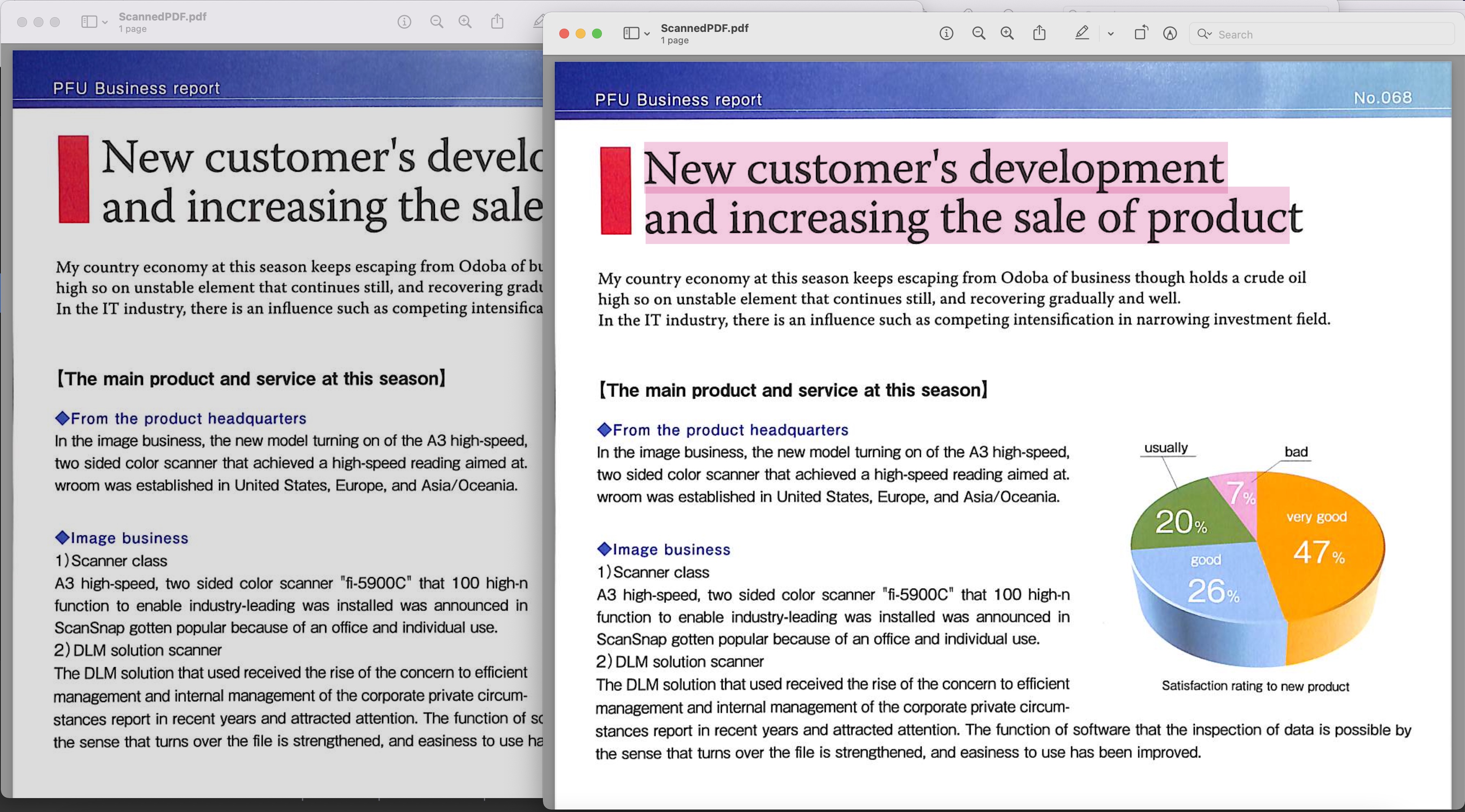
Image1:- अन्वेषणीयं PDF पूर्वावलोकनं
उपर्युक्ते उदाहरणे प्रयुक्तं स्कैन् कृतं PDF BusinessReport.pdf इत्यस्मात् डाउनलोड् कर्तुं शक्यते तथा च परिणामी अन्वेषणीयं PDF Converted.pdf इत्यस्मात् डाउनलोड् कर्तुं शक्यते ।
cURL Commands इत्यस्य उपयोगेन OCR Online
cURL आदेशाः REST APIs आह्वयितुं सुलभपद्धतिषु अन्यतमाः सन्ति । अतः अस्मिन् विभागे वयं OCR कृते cURL आदेशान् online उपयोक्तुं गच्छामः । अधुना पूर्वापेक्षारूपेण निम्नलिखित-आदेशं निष्पादयन् प्रथमं JWT-प्रवेश-टोकनं (क्लायन्ट्-प्रमाणपत्राधारितं) जनयितुं आवश्यकम् ।
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
एकदा अस्माकं JWT टोकन भवति तदा कृपया OCR ऑनलाइन कर्तुं निम्नलिखित आदेशं कुर्वन्तु तथा च Image PDF अन्वेषणीय PDF दस्तावेजे परिवर्तयन्तु । ततः परिणामी सञ्चिका मेघभण्डारणस्थाने संगृहीता भवति ।
curl -v -X GET "https://api.aspose.cloud/v4.0/words/Resultant.docx?format=TIFF&outPath=converted.tiff" \
-H "accept: application/octet-stream" \
-H "Authorization: Bearer <JWT Token>"
निगमन
एतेषां दस्तावेजानां पूर्णक्षमताम् अनलॉक् कर्तुं PDFs इत्यत्र OCR करणं महत्त्वपूर्णा प्रक्रिया अस्ति । जावा कृते Aspose.PDF Cloud SDK इत्यादीनां क्लाउड्-आधारित-OCR-उपकरणानाम् साहाय्येन एषा प्रक्रिया सरलीकरणं स्वचालितं च कर्तुं शक्यते, येन समयस्य रक्षणं भवति, उत्पादकता च वर्धते OCR इत्यस्य शक्तिं उपयुज्य व्यवसायाः विकासकाः च चित्राधारित-पीडीएफ-इत्येतत् अन्वेषणीय-पीडीएफ-रूपेण परिवर्तयितुं शक्नुवन्ति, येन तेषां अन्वेषणं, सम्पादनं, साझेदारी च सुलभं भवति । स्पष्टं यत् एतत् एपिआइ PDF इत्यनेन सह कार्यं कर्तुं शक्तिशालिनः विशेषताः क्षमताश्च श्रेणीं प्रदाति । अस्मिन् तकनीकीब्लॉगे प्रदत्तानां चरणबद्धमार्गदर्शिकानां अनुसरणं कृत्वा भवान् PDFs इत्यत्र OCR इत्यनेन सह आरम्भं कर्तुं शक्नोति तथा च स्वस्य दस्तावेजकार्यप्रवाहं अग्रिमस्तरं प्रति नेतुं शक्नोति।
भवान् swagger interface इत्यस्य उपयोगेन जालपुटस्य अन्तः API - मध्ये प्रवेशं कर्तुं विचारयितुं शक्नोति । अपि च, यथा अस्माकं SDKs MIT अनुज्ञापत्रस्य अन्तर्गतं निर्मिताः सन्ति, अतः सम्पूर्णः स्रोतसङ्केतः GitHub इत्यस्मात् अवतरणं कर्तुं शक्यते । एपिआइ-उपयोगकाले भवान् किमपि समस्यां प्राप्नोति चेत्, कृपया free product support forum इत्यनेन अस्माभिः सह सम्पर्कं कर्तुं निःशङ्कं भवन्तु ।
सम्बन्धित लेख
अस्य विषये अधिकं ज्ञातुं निम्नलिखितलिङ्कानि द्रष्टुं वयं अत्यन्तं अनुशंसयामः: