
Muunna Image PDF haettavaksi PDF-tiedostoksi
Nykypäivän datalähtöisessä maailmassa PDF-tiedostoista on tullut korvaamaton tiedostomuoto asiakirjojen tallentamiseen ja jakamiseen. Kaikki PDF-tiedostot eivät kuitenkaan ole helposti haettavissa tai muokattavissa, etenkään ne, jotka ovat kuvapohjaisia. Asiakirjoja käsiteltäessä on todella vaikeaa kopioida/purkaa mitään tekstitietoa jatkokäsittelyä varten. Onneksi optisen merkintunnistusteknologian (OCR) avulla voit muuntaa PDF-kuvatiedostot helposti haettavissa oleviksi PDF-tiedostoiksi. Tässä teknisessä blogissa tutkimme, kuinka OCR PDF muunnetaan haettavaksi PDF-muotoon useilla eri tekniikoilla keskittyen erityisesti REST-sovellusliittymään. Keskustelemme myös tekstin poimimisesta OCR PDF -tiedostoista, mikä antaa sinulle kattavan käsityksen siitä, kuinka voit hyödyntää OCR-tekniikkaa PDF-dokumenttien täyden potentiaalin hyödyntämiseksi.
- OCR PDF Java SDK:lla
- Skannattu PDF haettavaksi PDF-tiedostoksi Javalla
- OCR Online cURL-komentojen avulla
OCR PDF Java SDK:lla
Aspose.PDF Cloud SDK for Java on tehokas pilvipohjainen API, joka tarjoaa laajan valikoiman ominaisuuksia ja ominaisuuksia PDF-dokumenttien käsittelyyn. Yksi sen tärkeimmistä toiminnoista on kyky suorittaa tekstintunnistusta PDF-tiedostoille, mikä voi yksinkertaistaa huomattavasti tekstin poimimista kuvapohjaisista PDF-tiedostoista ja haettavien PDF-tiedostojen luomista. Tämän SDK:n käyttäjäystävällisen käyttöliittymän ja kattavan dokumentaation ansiosta on helppoa automatisoida tekstintunnistusprosessi PDF-tiedostoille, mikä säästää aikaa ja lisää tuottavuutta.
Lisäksi tämä pilvipohjainen API on suunniteltu käsittelemään monenlaisia syöttömuotoja ja tunnistamaan jopa käsinkirjoitetun tekstin, mikä tekee siitä erinomaisen valinnan yrityksille ja kehittäjille, jotka haluavat virtaviivaistaa dokumenttien työnkulkuaan. Nyt ensimmäinen askel on lisätä sen viite Java-projektiin lisäämällä seuraavat tiedot maven build -projektin pom.xml-tiedostoon.
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>http://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
Jos sinulla ei ole vielä tiliä, sinun on luotava ilmainen tili Aspose Cloudin kautta. Kirjaudu sisään äskettäin luodulla tilillä ja etsi/luo asiakastunnus ja asiakassalaisuus Cloud Dashboardissa. Nämä tiedot vaaditaan seuraavissa osissa.
Skannattu PDF haettavaksi PDF-tiedostoksi Javalla
Tässä osiossa kerrotaan, miten skannattu PDF muunnetaan haettavaksi PDF-tiedostoksi Java-koodinpätkän avulla. Huomaa, että Java Cloud SDK tukee seuraavien kielten tunnistamista: eng, ara, bel, ben, bul, ces, dan, deu, ell, fin, fra, heb, hin, ind, isl, ita, jpn, kor, nld , ei, pol, por, ron, rus, spa, swe, tha, tur, ukr, vie, chisim, chitra tai niiden yhdistelmä esim. eng,rus.
- Ensin meidän on luotava PdfApi-objekti, jossa välitämme ClientID- ja Client Secret -tiedot argumentteina
- Toiseksi luo Tiedosto-luokan esiintymä PDF-kuvan lataamiseksi
- Kolmanneksi kutsu menetelmä uploadFile(…) ladataksesi syöttö-PDF-tiedosto pilvitallennustilaan
- Koska PDF-kuvamme sisältää englanninkielistä tekstiä, meidän on luotava merkkijonoobjekti, jolla on arvo “eng”
- Kutsu lopuksi menetelmä putSearchableDocument(…), joka vaatii syötetyn PDF-tiedoston ja kielikoodin argumentteina.
Kun koodi on suoritettu onnistuneesti, haettava PDF tallennetaan pilvitallennustilaan
try
{
// Hanki ClientID ja ClientSecret osoitteesta https://dashboard.aspose.cloud/
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// luo PdfApi-esiintymä
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// syötä kuva PDF-dokumentti
String name = "ScannedPDF.pdf";
// Lataa tiedosto paikallisesta järjestelmästä
File file = new File(name);
// lataa tiedosto pilvitallennustilaan
FilesUploadResult uploadResponse = pdfApi.uploadFile(name, file, null);
// PDF-kuvassa käytetyt kielet
String lang = "eng";
// Suorita OCR kuvan PDF-dokumentille
AsposeResponse response = pdfApi.putSearchableDocument(name, null, null, lang);
// tulosta menestysviesti
System.out.println("OCR PDF successfull !");
}catch(Exception ex)
{
System.out.println(ex.getMessage());
}
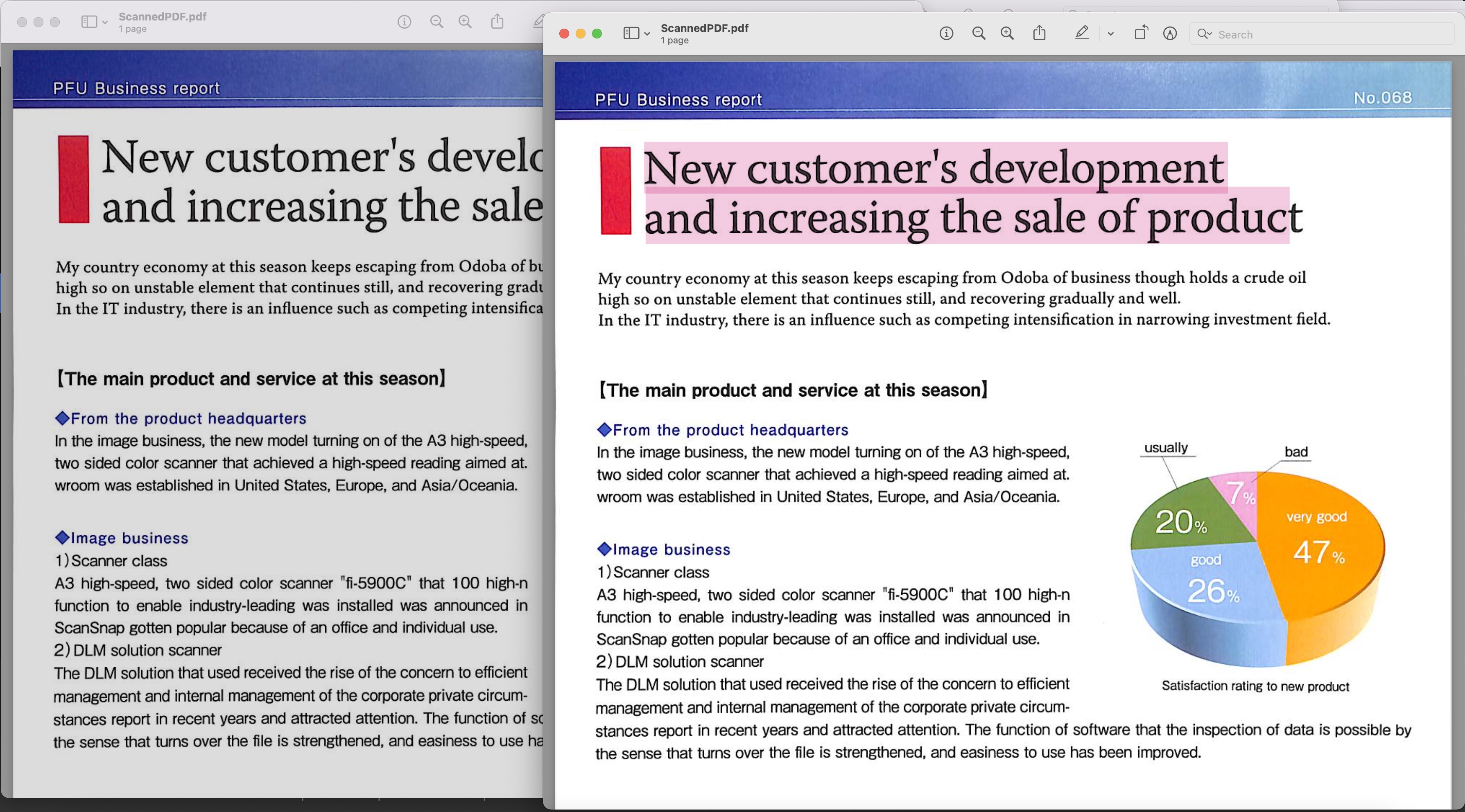
Kuva1: - Haettavissa oleva PDF-esikatselu
Yllä olevassa esimerkissä käytetty skannattu PDF voidaan ladata osoitteesta BusinessReport.pdf ja tuloksena oleva haettava PDF osoitteesta Converted.pdf
OCR Online cURL-komentojen avulla
cURL-komennot ovat yksi kätevistä tavoista kutsua REST-sovellusliittymiä. Joten tässä osiossa aiomme käyttää cURL-komentoja OCR:lle verkossa. Edellytyksenä meidän on nyt ensin luotava JWT-käyttöoikeustunnus (perustuu asiakkaan tunnistetietoihin) samalla kun suoritamme seuraavan komennon.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Kun meillä on JWT-tunnus, suorita OCR verkossa ja muunna Image PDF haettavaksi PDF-dokumentiksi seuraavalla komennolla. Tuloksena oleva tiedosto tallennetaan sitten pilvitallennustilaan.
curl -v -X GET "https://api.aspose.cloud/v4.0/words/Resultant.docx?format=TIFF&outPath=converted.tiff" \
-H "accept: application/octet-stream" \
-H "Authorization: Bearer <JWT Token>"
Johtopäätös
OCR:n suorittaminen PDF-tiedostoissa on kriittinen prosessi näiden asiakirjojen täyden potentiaalin vapauttamiseksi. Pilvipohjaisten OCR-työkalujen, kuten Aspose.PDF Cloud SDK for Java, avulla tämä prosessi voidaan yksinkertaistaa ja automatisoida, mikä säästää aikaa ja lisää tuottavuutta. OCR:n tehoja hyödyntämällä yritykset ja kehittäjät voivat muuttaa kuvapohjaiset PDF-tiedostot haettavissa oleviksi PDF-tiedostoiksi, mikä helpottaa niiden etsimistä, muokkaamista ja jakamista. On selvää, että tämä API tarjoaa joukon tehokkaita ominaisuuksia ja ominaisuuksia PDF-tiedostojen käsittelyyn. Noudattamalla tässä teknisessä blogissa annettuja vaiheittaisia oppaita voit aloittaa tekstintunnistusta PDF-tiedostoissa ja viedä asiakirjan työnkulkusi uudelle tasolle.
Voit harkita sovellusliittymän käyttämistä verkkoselaimessa käyttämällä swagger-käyttöliittymää. Lisäksi, koska SDK:mme on rakennettu MIT-lisenssillä, koko lähdekoodi voidaan ladata GitHubista. Jos kohtaat ongelmia API:n käytössä, ota meihin yhteyttä ilmaisen tuotetukifoorumin kautta.
Aiheeseen liittyvät artikkelit
Suosittelemme tutustumaan seuraaviin linkkeihin saadaksesi lisätietoja: