
Převést obrázek PDF do PDF s možností vyhledávání
V dnešním světě založeném na datech se PDF staly nepostradatelným formátem pro ukládání a sdílení dokumentů. Ne všechny soubory PDF však lze snadno prohledávat nebo upravovat, zejména ty, které jsou založeny na obrázcích. Při práci s dokumenty je opravdu obtížné kopírovat/extrahovat jakékoli textové informace pro další manipulaci. Naštěstí pomocí technologie optického rozpoznávání znaků (OCR) můžete snadno převést soubory PDF na soubory PDF s možností vyhledávání. V tomto technickém blogu prozkoumáme, jak převést OCR PDF na prohledávatelné PDF pomocí různých technik, se specifickým zaměřením na REST API. Budeme také diskutovat o tom, jak extrahovat text z OCR PDF, což vám poskytne komplexní pochopení toho, jak využít technologii OCR k využití plného potenciálu vašich dokumentů PDF.
- OCR PDF pomocí Java SDK
- Naskenované PDF do PDF s možností vyhledávání pomocí Javy
- OCR Online pomocí příkazů cURL
OCR PDF pomocí Java SDK
Aspose.PDF Cloud SDK for Java je výkonné cloudové API, které nabízí širokou škálu funkcí a možností pro práci s dokumenty PDF. Jednou z jeho klíčových funkcí je schopnost provádět OCR na PDF, což může značně zjednodušit proces extrahování textu z obrázků PDF a vytváření prohledávatelných PDF. Tato sada SDK se svým uživatelsky přívětivým rozhraním a komplexní dokumentací usnadňuje automatizaci procesu provádění OCR na souborech PDF, šetří čas a zvyšuje produktivitu.
Kromě toho je toto cloudové rozhraní API navrženo tak, aby zvládlo širokou škálu vstupních formátů a dokáže dokonce rozpoznat ručně psaný text, což z něj činí vynikající volbu pro podniky a vývojáře, kteří chtějí zefektivnit pracovní tok dokumentů. Nyní je prvním krokem přidání jeho reference do projektu Java přidáním následujících podrobností do pom.xml projektu maven build.
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>http://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
Pokud nemáte existující účet, musíte si vytvořit bezplatný účet přes Aspose Cloud. Přihlaste se pomocí nově vytvořeného účtu a vyhledejte/vytvořte ID klienta a tajný klíč klienta na Cloud Dashboard. Tyto podrobnosti jsou vyžadovány v následujících částech.
Naskenované PDF do PDF s možností vyhledávání pomocí Javy
Tato část vysvětluje podrobnosti, jak převést naskenované PDF do PDF s možností vyhledávání pomocí úryvku kódu Java. Vezměte prosím na vědomí, že Java Cloud SDK podporuje rozpoznávání následujících jazyků: eng, ara, bel, ben, bul, ces, dan, deu, ell, fin, fra, heb, hin, ind, isl, ita, jpn, kor, nld , nor, pol, por, ron, rus, spa, swe, tha, tur, ukr, vie, chisim, chitra nebo jejich kombinace např. eng,rus.
- Nejprve musíme vytvořit objekt PdfApi, kam předáme ClientID a tajné detaily klienta jako argumenty
- Za druhé, vytvořte instanci třídy File pro načtení obrázku PDF
- Zatřetí, zavolejte metodu uploadFile(…) pro nahrání vstupního PDF do cloudového úložiště
- Protože náš obrázek PDF obsahuje anglický text, musíme vytvořit objekt typu string s hodnotou „eng“
- Nakonec zavolejte metodu putSearchableDocument(…), která vyžaduje vstupní PDF a kód jazyka jako argumenty.
Po úspěšném provedení kódu se prohledávatelné PDF uloží do cloudového úložiště
try
{
// Získejte ClientID a ClientSecret z https://dashboard.aspose.cloud/
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// createPdfApi instance
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// vstupní obrázek PDF dokument
String name = "ScannedPDF.pdf";
// Načtěte soubor z místního systému
File file = new File(name);
// nahrajte soubor do cloudového úložiště
FilesUploadResult uploadResponse = pdfApi.uploadFile(name, file, null);
// jazyky používané v obrázkovém PDF
String lang = "eng";
// proveďte OCR na obrázku PDF dokumentu
AsposeResponse response = pdfApi.putSearchableDocument(name, null, null, lang);
// tisk zprávy o úspěchu
System.out.println("OCR PDF successfull !");
}catch(Exception ex)
{
System.out.println(ex.getMessage());
}
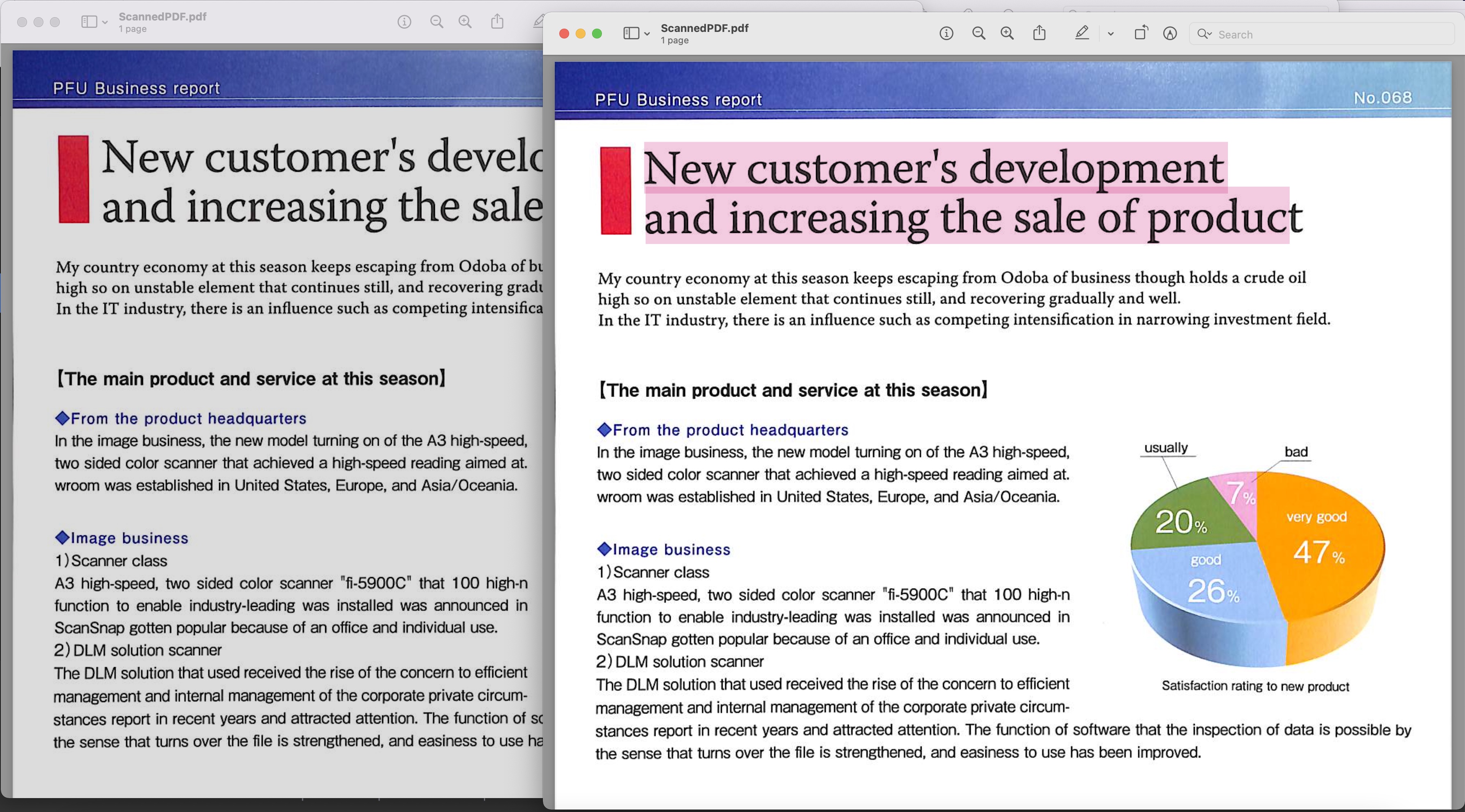
Obrázek1: - Náhled PDF s možností vyhledávání
Naskenovaný PDF použitý ve výše uvedeném příkladu lze stáhnout z BusinessReport.pdf a výsledný prohledávatelný PDF z Converted.pdf
OCR Online pomocí příkazů cURL
Příkazy cURL jsou jedním z pohodlných přístupů k volání REST API. V této části tedy použijeme příkazy cURL pro OCR online. Nyní, jako předpoklad, musíme nejprve vygenerovat přístupový token JWT (na základě přihlašovacích údajů klienta) při provádění následujícího příkazu.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Jakmile máme token JWT, použijte následující příkaz k provedení OCR online a převodu Image PDF na dokument PDF s možností vyhledávání. Výsledný soubor se pak uloží do cloudového úložiště.
curl -v -X GET "https://api.aspose.cloud/v4.0/words/Resultant.docx?format=TIFF&outPath=converted.tiff" \
-H "accept: application/octet-stream" \
-H "Authorization: Bearer <JWT Token>"
Závěr
Provádění OCR na souborech PDF je kritickým procesem pro využití plného potenciálu těchto dokumentů. S pomocí cloudových nástrojů OCR, jako je Aspose.PDF Cloud SDK pro Java, lze tento proces zjednodušit a automatizovat, což šetří čas a zvyšuje produktivitu. Využitím výkonu OCR mohou podniky a vývojáři transformovat soubory PDF založené na obrázcích na soubory PDF s možností vyhledávání, což usnadňuje vyhledávání, úpravy a sdílení. Je jasné, že toto API nabízí řadu výkonných funkcí a možností pro práci s PDF. Pokud budete postupovat podle podrobných průvodců uvedených v tomto technickém blogu, můžete začít s OCR na souborech PDF a posunout svůj pracovní postup dokumentů na další úroveň.
Můžete zvážit přístup k API ve webovém prohlížeči pomocí swagger interface. Navíc, protože naše SDK jsou vytvořeny pod licencí MIT, kompletní zdrojový kód lze stáhnout z GitHub. V případě, že při používání API narazíte na nějaké problémy, neváhejte nás kontaktovat prostřednictvím free product support forum.
Související články
Důrazně doporučujeme navštívit následující odkazy, kde se dozvíte více o: