
छवि पीडीएफ को खोजने योग्य पीडीएफ में बदलें
आज की डेटा-संचालित दुनिया में, पीडीएफ दस्तावेजों को संग्रहीत करने और साझा करने के लिए एक अनिवार्य प्रारूप बन गया है। हालाँकि, सभी PDF आसानी से खोजने योग्य या संपादन योग्य नहीं हैं, विशेष रूप से वे जो छवि-आधारित हैं। दस्तावेजों के साथ काम करते समय, आगे के हेरफेर के लिए किसी पाठ्य सूचना को कॉपी/निकालना वाकई मुश्किल है। सौभाग्य से, ऑप्टिकल कैरेक्टर रिकॉग्निशन (ओसीआर) तकनीक की शक्ति के साथ, आप छवि पीडीएफ को आसानी से खोजने योग्य पीडीएफ में परिवर्तित कर सकते हैं। इस तकनीकी ब्लॉग में, हम REST API पर विशेष ध्यान देने के साथ विभिन्न तकनीकों का उपयोग करके OCR PDF को खोजने योग्य PDF में बदलने का तरीका जानेंगे। हम यह भी चर्चा करेंगे कि OCR PDF से टेक्स्ट कैसे निकालें, जिससे आपको अपने PDF दस्तावेज़ों की पूरी क्षमता को अनलॉक करने के लिए OCR तकनीक का लाभ उठाने की व्यापक समझ मिलेगी।
- ओसीआर पीडीएफ जावा एसडीके का उपयोग कर
- जावा का उपयोग करके पीडीएफ को खोजने योग्य पीडीएफ में स्कैन किया गया
- ओसीआर ऑनलाइन कर्ल कमांड का उपयोग कर रहा है
ओसीआर पीडीएफ जावा एसडीके का उपयोग कर
जावा के लिए Aspose.PDF क्लाउड एसडीके एक शक्तिशाली क्लाउड-आधारित एपीआई है जो पीडीएफ दस्तावेजों के साथ काम करने के लिए कई प्रकार की सुविधाएँ और क्षमताएं प्रदान करता है। इसकी प्रमुख कार्यात्मकताओं में से एक पीडीएफ पर ओसीआर प्रदर्शन करने की क्षमता है, जो छवि-आधारित पीडीएफ से पाठ निकालने और खोजने योग्य पीडीएफ बनाने की प्रक्रिया को बहुत सरल कर सकती है। अपने उपयोगकर्ता के अनुकूल इंटरफेस और व्यापक प्रलेखन के साथ, यह एसडीके पीडीएफ पर ओसीआर प्रदर्शन की प्रक्रिया को स्वचालित करना, समय की बचत करना और उत्पादकता बढ़ाना आसान बनाता है।
इसके अलावा, यह क्लाउड-आधारित एपीआई विभिन्न प्रकार के इनपुट प्रारूपों को संभालने के लिए डिज़ाइन किया गया है और हस्तलिखित पाठ को भी पहचान सकता है, जिससे यह व्यवसायों और डेवलपर्स के लिए एक उत्कृष्ट विकल्प बन जाता है जो अपने दस्तावेज़ वर्कफ़्लो को सुव्यवस्थित करना चाहते हैं। अब पहला कदम मावेन बिल्ड प्रोजेक्ट के pom.xml में निम्नलिखित विवरण जोड़कर जावा प्रोजेक्ट में इसका संदर्भ जोड़ना है।
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>http://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
यदि आपके पास कोई मौजूदा खाता नहीं है, तो आपको एस्पोज़ क्लाउड पर एक मुफ़्त खाता बनाने की आवश्यकता है। नए बनाए गए खाते का उपयोग करके लॉगिन करें और क्लाउड डैशबोर्ड पर क्लाइंट आईडी और क्लाइंट सीक्रेट देखें/बनाएं। ये विवरण बाद के खंडों में आवश्यक हैं।
जावा का उपयोग करके पीडीएफ को खोजने योग्य पीडीएफ में स्कैन किया गया
यह खंड जावा कोड स्निपेट का उपयोग करके स्कैन किए गए पीडीएफ को खोजने योग्य पीडीएफ में बदलने के तरीके के विवरण की व्याख्या करता है। कृपया ध्यान दें कि Java क्लाउड SDK निम्नलिखित भाषाओं की मान्यता का समर्थन करता है: eng, ara, Bel, Ben, bul, ces, dan, deu, ell, fin, fra, heb, hin, ind, isl, ita, jpn, kor, nld , न ही, पोल, पोर, रॉन, रस, स्पा, स्वे, था, तूर, यूकेआर, वी, चिसिम, चित्रा या उनका संयोजन जैसे इंग्लैंड, रस।
- पहले हमें PdfApi का एक ऑब्जेक्ट बनाने की आवश्यकता है, जहाँ हम ClientID और Client गुप्त विवरण को तर्क के रूप में पास करते हैं
- दूसरे, इमेज पीडीएफ को लोड करने के लिए फाइल क्लास का एक उदाहरण बनाएं
- तीसरा, इनपुट पीडीएफ को क्लाउड स्टोरेज में अपलोड करने के लिए विधि अपलोडफाइल (…) को कॉल करें
- जैसा कि हमारी छवि पीडीएफ में अंग्रेजी पाठ है, इसलिए हमें “eng” मान रखने वाली एक स्ट्रिंग ऑब्जेक्ट बनाने की आवश्यकता है
- अंत में, विधि putSearchableDocument(…) को कॉल करें, जिसके लिए तर्क के रूप में एक इनपुट पीडीएफ और एक भाषा कोड की आवश्यकता होती है।
एक बार कोड सफलतापूर्वक निष्पादित हो जाने के बाद, खोजने योग्य पीडीएफ को क्लाउड स्टोरेज में स्टोर किया जाता है
try
{
// https://dashboard.aspose.cloud/ से ClientID और ClientSecret प्राप्त करें
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// createPdfApi उदाहरण
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// इनपुट छवि पीडीएफ दस्तावेज़
String name = "ScannedPDF.pdf";
// फ़ाइल को स्थानीय सिस्टम से लोड करें
File file = new File(name);
// फ़ाइल को क्लाउड स्टोरेज पर अपलोड करें
FilesUploadResult uploadResponse = pdfApi.uploadFile(name, file, null);
// छवि PDF में उपयोग की जाने वाली भाषाएँ
String lang = "eng";
// छवि पीडीएफ दस्तावेज़ पर ओसीआर का प्रदर्शन करें
AsposeResponse response = pdfApi.putSearchableDocument(name, null, null, lang);
// प्रिंट सफलता संदेश
System.out.println("OCR PDF successfull !");
}catch(Exception ex)
{
System.out.println(ex.getMessage());
}
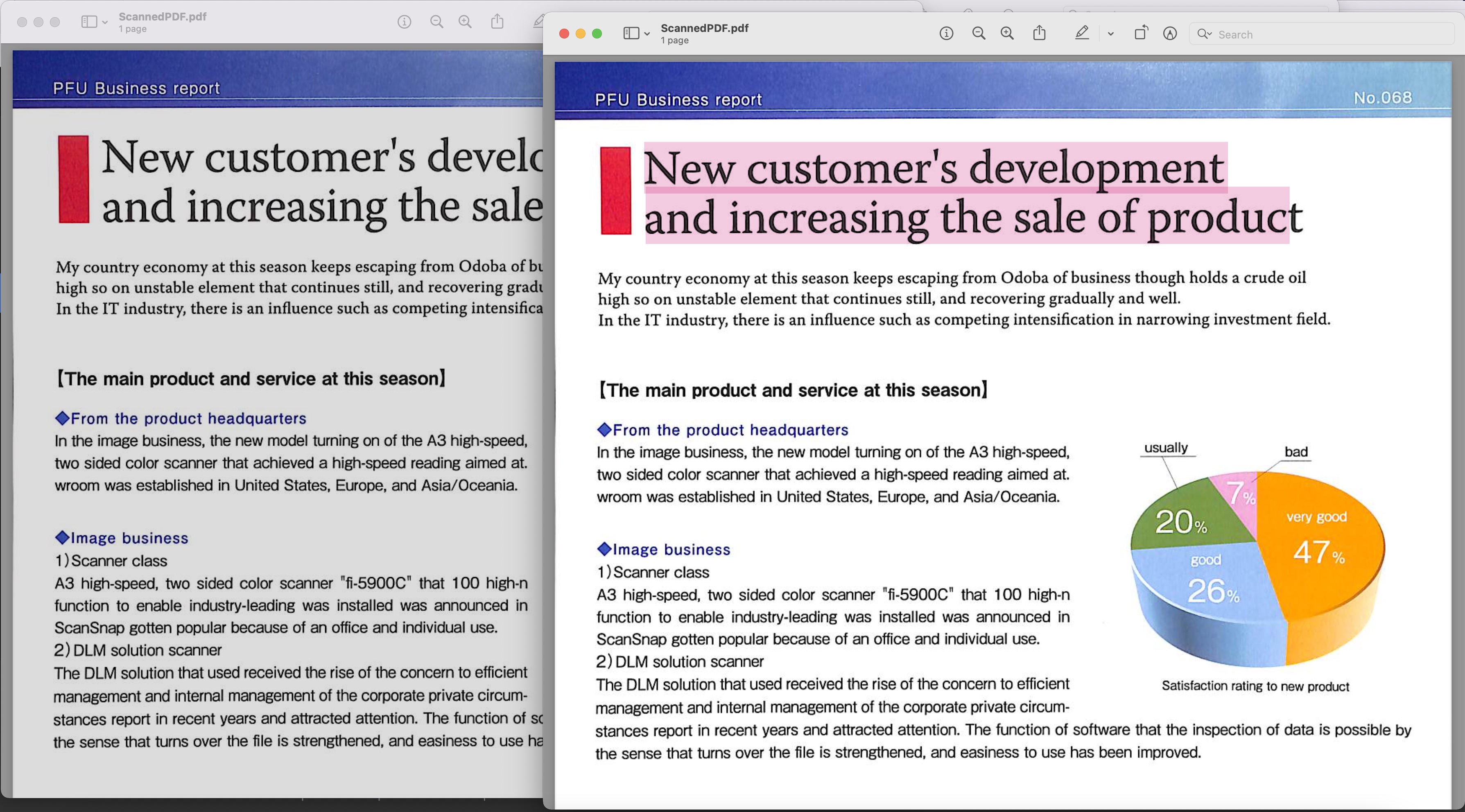
Image1:- खोजने योग्य पीडीएफ पूर्वावलोकन
उपरोक्त उदाहरण में उपयोग किए गए स्कैन किए गए पीडीएफ को BusinessReport.pdf से डाउनलोड किया जा सकता है और परिणामी खोज योग्य पीडीएफ Converted.pdf से डाउनलोड किया जा सकता है।
ओसीआर ऑनलाइन कर्ल कमांड का उपयोग कर रहा है
CURL कमांड REST API को कॉल करने के सुविधाजनक तरीकों में से एक है। तो इस खंड में, हम ओसीआर ऑनलाइन के लिए कर्ल कमांड का उपयोग करने जा रहे हैं। अब, एक शर्त के रूप में, हमें निम्नलिखित कमांड को निष्पादित करते समय सबसे पहले एक JWT एक्सेस टोकन (क्लाइंट क्रेडेंशियल्स के आधार पर) जेनरेट करना होगा।
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
एक बार हमारे पास जेडब्ल्यूटी टोकन हो जाने के बाद, कृपया ओसीआर ऑनलाइन करने के लिए निम्न आदेश दें और छवि पीडीएफ को खोजने योग्य पीडीएफ दस्तावेज़ में परिवर्तित करें। परिणामी फ़ाइल को तब क्लाउड स्टोरेज में संग्रहीत किया जाता है।
curl -v -X GET "https://api.aspose.cloud/v4.0/words/Resultant.docx?format=TIFF&outPath=converted.tiff" \
-H "accept: application/octet-stream" \
-H "Authorization: Bearer <JWT Token>"
निष्कर्ष
इन दस्तावेजों की पूरी क्षमता को अनलॉक करने के लिए पीडीएफ पर ओसीआर प्रदर्शन करना एक महत्वपूर्ण प्रक्रिया है। जावा के लिए Aspose.PDF Cloud SDK जैसे क्लाउड-आधारित OCR टूल की मदद से, इस प्रक्रिया को सरल और स्वचालित किया जा सकता है, जिससे समय की बचत होती है और उत्पादकता बढ़ती है। OCR की शक्ति का लाभ उठाकर, व्यवसाय और डेवलपर छवि-आधारित PDF को खोजने योग्य PDF में बदल सकते हैं, जिससे उन्हें खोजना, संपादित करना और साझा करना आसान हो जाता है। यह स्पष्ट है कि यह एपीआई पीडीएफ के साथ काम करने के लिए कई शक्तिशाली सुविधाओं और क्षमताओं की पेशकश करता है। इस तकनीकी ब्लॉग में दिए गए चरण-दर-चरण निर्देशों का पालन करके, आप PDF पर OCR के साथ आरंभ कर सकते हैं और अपने दस्तावेज़ कार्यप्रवाह को अगले स्तर पर ले जा सकते हैं।
आप स्वैगर इंटरफ़ेस का उपयोग करके एक वेब ब्राउज़र के भीतर एपीआई तक पहुँचने पर विचार कर सकते हैं। इसके अलावा, चूंकि हमारे एसडीके एमआईटी लाइसेंस के तहत बनाए गए हैं, इसलिए पूरा स्रोत कोड जीआईटीहब से डाउनलोड किया जा सकता है। यदि आपको एपीआई का उपयोग करते समय कोई समस्या आती है, तो कृपया बेझिझक हमसे मुफ्त उत्पाद समर्थन फोरम के माध्यम से संपर्क करें।
संबंधित आलेख
इसके बारे में अधिक जानने के लिए हम निम्नलिखित लिंक पर जाने की पुरजोर अनुशंसा करते हैं: