
Μετατροπή PDF εικόνας σε PDF με δυνατότητα αναζήτησης
Στον σημερινό κόσμο που βασίζεται σε δεδομένα, τα PDF έχουν γίνει μια απαραίτητη μορφή για την αποθήκευση και την κοινή χρήση εγγράφων. Ωστόσο, δεν είναι εύκολα αναζητήσιμα ή επεξεργάσιμα όλα τα PDF, ειδικά εκείνα που βασίζονται σε εικόνες. Όταν ασχολείστε με έγγραφα, είναι πραγματικά δύσκολο να αντιγράψετε/εξάγετε οποιαδήποτε πληροφορία κειμένου για περαιτέρω χειρισμό. Ευτυχώς, με τη δύναμη της τεχνολογίας Optical Character Recognition (OCR), μπορείτε να μετατρέψετε εύκολα αρχεία PDF εικόνας σε PDF με δυνατότητα αναζήτησης. Σε αυτό το τεχνικό ιστολόγιο, θα εξερευνήσουμε πώς να μετατρέψετε το OCR PDF σε PDF με δυνατότητα αναζήτησης χρησιμοποιώντας διάφορες τεχνικές, με ιδιαίτερη έμφαση στο REST API. Θα συζητήσουμε επίσης πώς να εξαγάγετε κείμενο από αρχεία OCR PDF, δίνοντάς σας μια ολοκληρωμένη κατανόηση του τρόπου με τον οποίο μπορείτε να αξιοποιήσετε την τεχνολογία OCR για να ξεκλειδώσετε πλήρως τις δυνατότητες των εγγράφων PDF σας.
- OCR PDF χρησιμοποιώντας Java SDK
- Σαρωμένο PDF σε PDF με δυνατότητα αναζήτησης χρησιμοποιώντας Java
- OCR Online χρησιμοποιώντας εντολές cURL
OCR PDF χρησιμοποιώντας Java SDK
Το Aspose.PDF Cloud SDK για Java είναι ένα ισχυρό API που βασίζεται σε σύννεφο που προσφέρει ένα ευρύ φάσμα λειτουργιών και δυνατοτήτων για εργασία με έγγραφα PDF. Μία από τις βασικές του λειτουργίες είναι η δυνατότητα εκτέλεσης OCR σε αρχεία PDF, η οποία μπορεί να απλοποιήσει σημαντικά τη διαδικασία εξαγωγής κειμένου από αρχεία PDF που βασίζονται σε εικόνα και τη δημιουργία αρχείων PDF με δυνατότητα αναζήτησης. Με τη φιλική προς το χρήστη διεπαφή και την ολοκληρωμένη τεκμηρίωσή του, αυτό το SDK διευκολύνει την αυτοματοποίηση της διαδικασίας εκτέλεσης OCR σε αρχεία PDF, εξοικονομώντας χρόνο και αυξάνοντας την παραγωγικότητα.
Επιπλέον, αυτό το API που βασίζεται σε σύννεφο έχει σχεδιαστεί για να χειρίζεται μια μεγάλη ποικιλία μορφών εισαγωγής και μπορεί ακόμη και να αναγνωρίσει χειρόγραφο κείμενο, καθιστώντας το μια εξαιρετική επιλογή για επιχειρήσεις και προγραμματιστές που θέλουν να βελτιστοποιήσουν τη ροή εργασίας των εγγράφων τους. Τώρα το πρώτο βήμα είναι να προσθέσετε την αναφορά του στο έργο Java προσθέτοντας τις ακόλουθες λεπτομέρειες στο pom.xml του έργου κατασκευής maven.
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>https://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
Εάν δεν έχετε υπάρχοντα λογαριασμό, πρέπει να δημιουργήσετε έναν δωρεάν λογαριασμό μέσω Aspose Cloud. Συνδεθείτε χρησιμοποιώντας νέο λογαριασμό και αναζητήστε/δημιουργήστε Client ID και Client Secret στο Cloud Dashboard. Αυτές οι λεπτομέρειες απαιτούνται σε επόμενες ενότητες.
Σαρωμένο PDF σε PDF με δυνατότητα αναζήτησης χρησιμοποιώντας Java
Αυτή η ενότητα εξηγεί τις λεπτομέρειες σχετικά με τον τρόπο μετατροπής του σαρωμένου PDF σε PDF με δυνατότητα αναζήτησης χρησιμοποιώντας απόσπασμα κώδικα Java. Λάβετε υπόψη ότι το Java Cloud SDK υποστηρίζει την αναγνώριση των ακόλουθων γλωσσών: eng, ara, bel, ben, bul, ces, dan, deu, ell, fin, fra, heb, hin, ind, isl, ita, jpn, kor, nld , nor, pol, por, ron, rus, spa, swe, tha, tur, ukr, vie, chisim, chitra ή ο συνδυασμός τους π.χ. eng,rus.
- Πρώτα πρέπει να δημιουργήσουμε ένα αντικείμενο του PdfApi, όπου περνάμε ως ορίσματα ClientID και μυστικές λεπτομέρειες Client
- Δεύτερον, δημιουργήστε μια παρουσία της κλάσης Αρχείο για να φορτώσετε το PDF της εικόνας
- Τρίτον, καλέστε τη μέθοδο uploadFile(…) για να ανεβάσετε το PDF εισόδου στο χώρο αποθήκευσης cloud
- Καθώς το PDF της εικόνας μας περιέχει αγγλικό κείμενο, έτσι πρέπει να δημιουργήσουμε ένα αντικείμενο συμβολοσειράς με τιμή “eng”
- Τέλος, καλέστε τη μέθοδο putSearchableDocument(…), η οποία απαιτεί ένα PDF εισαγωγής και έναν κώδικα γλώσσας ως ορίσματα.
Μόλις ο κώδικας εκτελεστεί επιτυχώς, το PDF με δυνατότητα αναζήτησης αποθηκεύεται στον χώρο αποθήκευσης cloud
try
{
// Λάβετε ClientID και ClientSecret από https://dashboard.aspose.cloud/
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// στιγμιότυπο δημιουργίαςPdfApi
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// Εισαγωγή εγγράφου PDF εικόνας
String name = "ScannedPDF.pdf";
// Φορτώστε το αρχείο από το τοπικό σύστημα
File file = new File(name);
// μεταφορτώστε το αρχείο στο χώρο αποθήκευσης cloud
FilesUploadResult uploadResponse = pdfApi.uploadFile(name, file, null);
// τις γλώσσες που χρησιμοποιούνται στο PDF εικόνας
String lang = "eng";
// εκτελέστε το OCR σε έγγραφο PDF εικόνας
AsposeResponse response = pdfApi.putSearchableDocument(name, null, null, lang);
// μήνυμα επιτυχίας εκτύπωσης
System.out.println("OCR PDF successfull !");
}catch(Exception ex)
{
System.out.println(ex.getMessage());
}
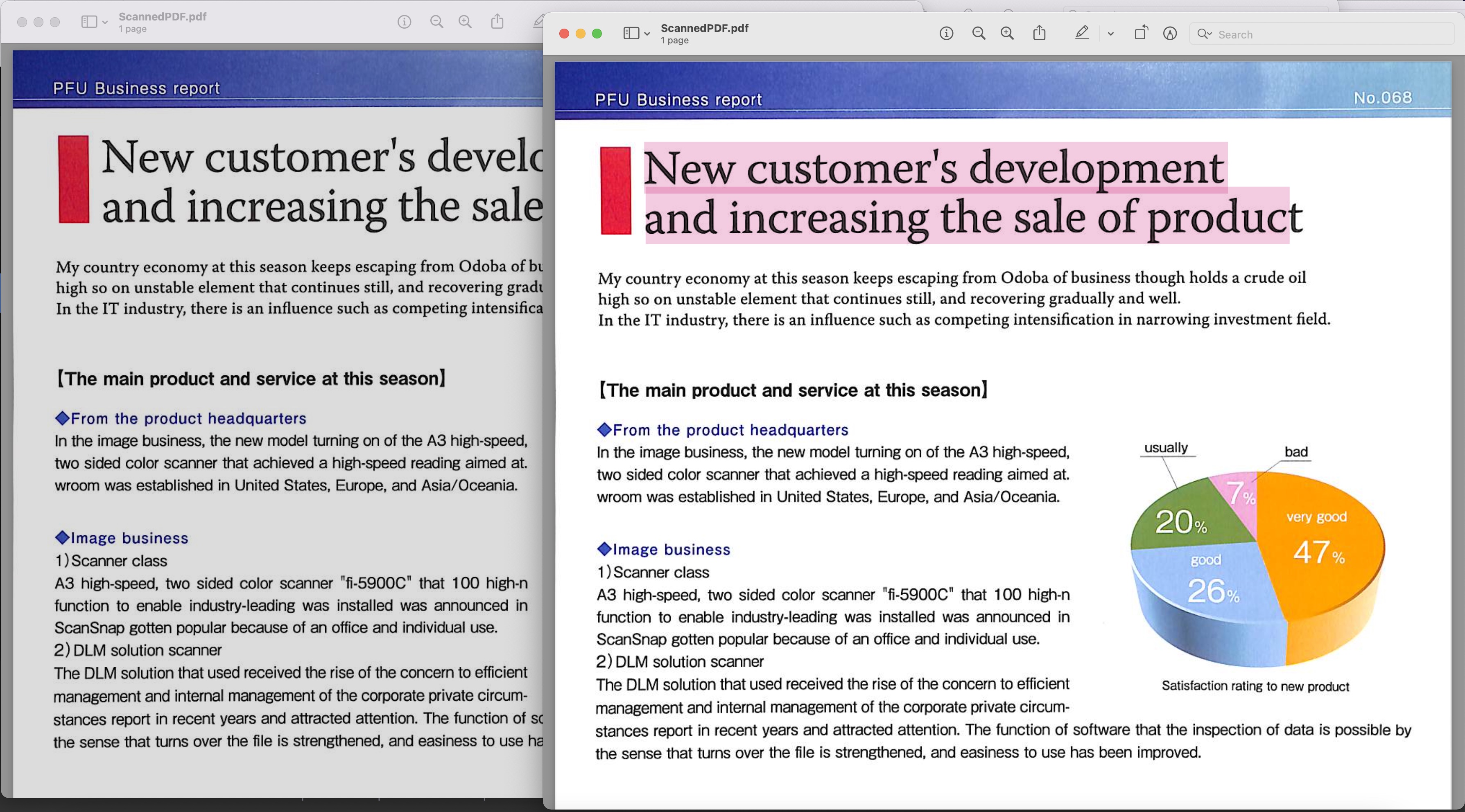
Εικόνα 1: - Προεπισκόπηση PDF με δυνατότητα αναζήτησης
Το σαρωμένο PDF που χρησιμοποιείται στο παραπάνω παράδειγμα μπορεί να ληφθεί από το BusinessReport.pdf και το PDF με δυνατότητα αναζήτησης που προκύπτει από το Converted.pdf
OCR Online χρησιμοποιώντας εντολές cURL
Οι εντολές cURL είναι μια από τις βολικές προσεγγίσεις για την κλήση των REST API. Έτσι, σε αυτήν την ενότητα, θα χρησιμοποιήσουμε τις εντολές cURL για το OCR online. Τώρα, ως προαπαιτούμενο, πρέπει πρώτα να δημιουργήσουμε ένα διακριτικό πρόσβασης JWT (με βάση τα διαπιστευτήρια πελάτη) ενώ εκτελούμε την ακόλουθη εντολή.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Μόλις έχουμε JWT token, παρακαλούμε την ακόλουθη εντολή για να εκτελέσετε OCR online και να μετατρέψετε το Image PDF σε έγγραφο PDF με δυνατότητα αναζήτησης. Το αρχείο που προκύπτει αποθηκεύεται στη συνέχεια στον χώρο αποθήκευσης cloud.
curl -v -X GET "https://api.aspose.cloud/v4.0/words/Resultant.docx?format=TIFF&outPath=converted.tiff" \
-H "accept: application/octet-stream" \
-H "Authorization: Bearer <JWT Token>"
συμπέρασμα
Η εκτέλεση OCR σε αρχεία PDF είναι μια κρίσιμη διαδικασία για το ξεκλείδωμα του πλήρους δυναμικού αυτών των εγγράφων. Με τη βοήθεια εργαλείων OCR που βασίζονται σε σύννεφο όπως το Aspose.PDF Cloud SDK για Java, αυτή η διαδικασία μπορεί να απλοποιηθεί και να αυτοματοποιηθεί, εξοικονομώντας χρόνο και αυξάνοντας την παραγωγικότητα. Αξιοποιώντας τη δύναμη του OCR, οι επιχειρήσεις και οι προγραμματιστές μπορούν να μετατρέψουν αρχεία PDF που βασίζονται σε εικόνες σε PDF με δυνατότητα αναζήτησης, διευκολύνοντας την αναζήτηση, την επεξεργασία και την κοινή χρήση τους. Είναι σαφές ότι αυτό το API προσφέρει μια σειρά από ισχυρές δυνατότητες και δυνατότητες για εργασία με αρχεία PDF. Ακολουθώντας τους οδηγούς βήμα προς βήμα που παρέχονται σε αυτό το τεχνικό ιστολόγιο, μπορείτε να ξεκινήσετε με το OCR σε αρχεία PDF και να μεταφέρετε τη ροή εργασίας του εγγράφου σας στο επόμενο επίπεδο.
Μπορείτε να εξετάσετε το ενδεχόμενο πρόσβασης στο API μέσα σε ένα πρόγραμμα περιήγησης ιστού χρησιμοποιώντας τη διασύνδεση swagger. Επιπλέον, καθώς τα SDK μας έχουν κατασκευαστεί με άδεια MIT, μπορείτε να λάβετε ολόκληρο τον πηγαίο κώδικα από το GitHub. Σε περίπτωση που αντιμετωπίσετε προβλήματα κατά τη χρήση του API, μη διστάσετε να επικοινωνήσετε μαζί μας μέσω του δωρεάν φόρουμ υποστήριξης προϊόντων.
Σχετικά Άρθρα
Συνιστούμε ανεπιφύλακτα να επισκεφθείτε τους παρακάτω συνδέσμους για να μάθετε περισσότερα σχετικά με: