
แปลง Image PDF เป็น PDF ที่ค้นหาได้
ในโลกปัจจุบันที่ขับเคลื่อนด้วยข้อมูล PDF ได้กลายเป็นรูปแบบที่ขาดไม่ได้สำหรับการจัดเก็บและแบ่งปันเอกสาร อย่างไรก็ตาม ไม่ใช่ว่า PDF ทั้งหมดจะสามารถค้นหาหรือแก้ไขได้โดยง่าย โดยเฉพาะไฟล์ที่เป็นรูปภาพ เมื่อจัดการกับเอกสาร เป็นเรื่องยากมากที่จะคัดลอก/แยกข้อมูลที่เป็นข้อความเพื่อการจัดการเพิ่มเติม โชคดีที่ด้วยพลังของเทคโนโลยี Optical Character Recognition (OCR) คุณสามารถแปลง PDF รูปภาพเป็น PDF ที่ค้นหาได้อย่างง่ายดาย ในบล็อกทางเทคนิคนี้ เราจะสำรวจวิธีแปลง OCR PDF เป็น PDF ที่ค้นหาได้โดยใช้เทคนิคต่างๆ โดยเน้นเฉพาะที่ REST API นอกจากนี้ เราจะหารือถึงวิธีการแยกข้อความจากไฟล์ OCR PDF เพื่อให้คุณเข้าใจอย่างครอบคลุมเกี่ยวกับวิธีใช้ประโยชน์จากเทคโนโลยี OCR เพื่อปลดล็อกศักยภาพทั้งหมดของเอกสาร PDF ของคุณ
OCR PDF โดยใช้ Java SDK
Aspose.PDF Cloud SDK สำหรับ Java เป็น API บนคลาวด์ที่ทรงพลังซึ่งมีฟีเจอร์และความสามารถที่หลากหลายสำหรับการทำงานกับเอกสาร PDF หนึ่งในฟังก์ชันหลักคือความสามารถในการทำ OCR บน PDF ซึ่งช่วยลดความซับซ้อนของกระบวนการแยกข้อความจาก PDF ที่ใช้รูปภาพและสร้าง PDF ที่ค้นหาได้ ด้วยอินเทอร์เฟซที่ใช้งานง่ายและเอกสารประกอบที่ครอบคลุม SDK นี้ทำให้กระบวนการดำเนินการ OCR บน PDF เป็นไปโดยอัตโนมัติเป็นเรื่องง่าย ประหยัดเวลาและเพิ่มผลผลิต
นอกจากนี้ API บนระบบคลาวด์นี้ได้รับการออกแบบมาเพื่อจัดการรูปแบบการป้อนข้อมูลที่หลากหลาย และยังสามารถจดจำข้อความที่เขียนด้วยลายมือได้ ทำให้เป็นตัวเลือกที่ยอดเยี่ยมสำหรับธุรกิจและนักพัฒนาที่ต้องการปรับปรุงเวิร์กโฟลว์เอกสารของตน ขั้นตอนแรกคือการเพิ่มการอ้างอิงในโครงการ Java โดยเพิ่มรายละเอียดต่อไปนี้ใน pom.xml ของโครงการ maven build
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>https://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
หากคุณไม่มีบัญชี คุณต้องสร้างบัญชีฟรีผ่าน Aspose Cloud เข้าสู่ระบบโดยใช้บัญชีที่สร้างขึ้นใหม่และค้นหา/สร้างรหัสไคลเอ็นต์และรหัสลับไคลเอ็นต์ที่ Cloud Dashboard รายละเอียดเหล่านี้จำเป็นในส่วนต่อๆ ไป
สแกน PDF เป็น PDF ที่ค้นหาได้โดยใช้ Java
ส่วนนี้อธิบายรายละเอียดเกี่ยวกับวิธีแปลง PDF ที่สแกนเป็น PDF ที่ค้นหาได้โดยใช้ข้อมูลโค้ด Java โปรดทราบว่า Java Cloud SDK รองรับการจดจำภาษาต่อไปนี้: eng, ara, bel, ben, bul, ces, dan, deu, ell, fin, fra, heb, hin, ind, isl, ita, jpn, kor, nld , nor, pol, por, ron, rus, spa, swe, tha, tur, ukr, vie, chisim, chitra หรือการรวมกันของพวกเขาเช่น eng, rus
- ก่อนอื่นเราต้องสร้างวัตถุของ PdfApi ซึ่งเราส่งรหัสลูกค้าและรายละเอียดความลับของลูกค้าเป็นอาร์กิวเมนต์
- ประการที่สอง สร้างอินสแตนซ์ของคลาส File เพื่อโหลด Image PDF
- ประการที่สาม เรียกใช้เมธอด uploadFile(…) เพื่ออัปโหลดอินพุต PDF ไปยังที่เก็บข้อมูลบนคลาวด์
- เนื่องจาก PDF รูปภาพของเรามีข้อความภาษาอังกฤษ เราจึงจำเป็นต้องสร้างวัตถุสตริงที่มีค่าเป็น “eng”
- สุดท้าย เรียกใช้เมธอด putSearchableDocument(…) ซึ่งต้องใช้อินพุต PDF และรหัสภาษาเป็นอาร์กิวเมนต์
เมื่อดำเนินการโค้ดสำเร็จ PDF ที่ค้นหาได้จะถูกจัดเก็บไว้ในที่เก็บข้อมูลบนคลาวด์
try
{
// รับ ClientID และ ClientSecret จาก https://dashboard.aspose.cloud/
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// สร้างอินสแตนซ์ PdfApi
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// ใส่รูปภาพเอกสาร PDF
String name = "ScannedPDF.pdf";
// โหลดไฟล์จากระบบโลคัล
File file = new File(name);
// อัปโหลดไฟล์ไปยังที่เก็บข้อมูลบนคลาวด์
FilesUploadResult uploadResponse = pdfApi.uploadFile(name, file, null);
// ภาษาที่ใช้ใน PDF รูปภาพ
String lang = "eng";
// ดำเนินการ OCR บนเอกสาร PDF รูปภาพ
AsposeResponse response = pdfApi.putSearchableDocument(name, null, null, lang);
// พิมพ์ข้อความแสดงความสำเร็จ
System.out.println("OCR PDF successfull !");
}catch(Exception ex)
{
System.out.println(ex.getMessage());
}
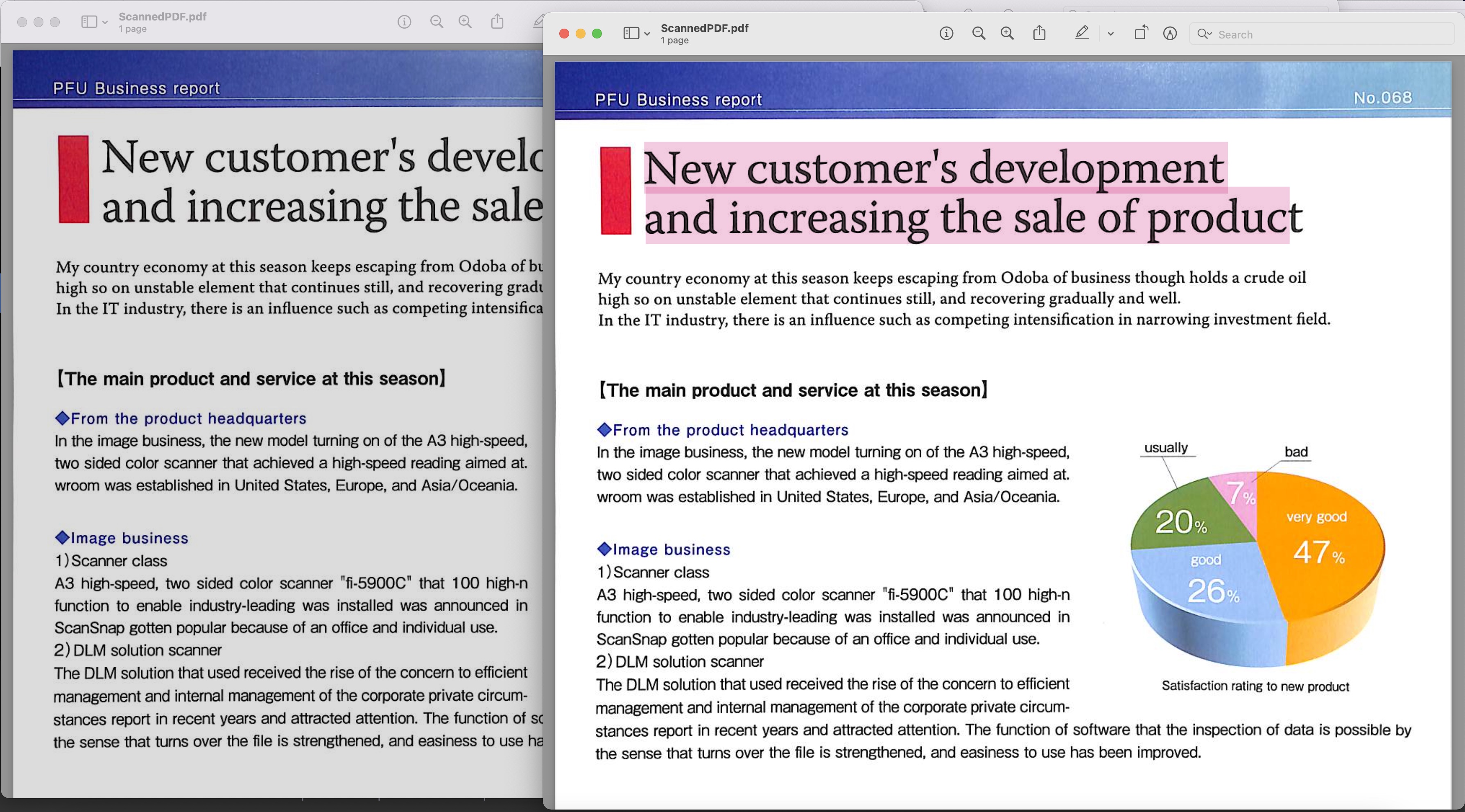
Image1:- ดูตัวอย่าง PDF ที่ค้นหาได้
ไฟล์ PDF ที่สแกนที่ใช้ในตัวอย่างข้างต้นสามารถดาวน์โหลดได้จาก BusinessReport.pdf และไฟล์ PDF ที่ค้นหาผลลัพธ์ได้จาก Converted.pdf
OCR ออนไลน์โดยใช้คำสั่ง cURL
คำสั่ง cURL เป็นหนึ่งในวิธีที่สะดวกในการเรียกใช้ REST API ในส่วนนี้ เราจะใช้คำสั่ง cURL สำหรับ OCR ออนไลน์ ในตอนนี้ ตามข้อกำหนดเบื้องต้น เราต้องสร้างโทเค็นการเข้าถึง JWT (ตามข้อมูลประจำตัวของไคลเอ็นต์) ก่อนในขณะที่ดำเนินการคำสั่งต่อไปนี้
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
เมื่อเรามีโทเค็น JWT โปรดใช้คำสั่งต่อไปนี้เพื่อดำเนินการ OCR ออนไลน์และแปลง Image PDF เป็นเอกสาร PDF ที่ค้นหาได้ ไฟล์ผลลัพธ์จะถูกเก็บไว้ในที่เก็บข้อมูลบนคลาวด์
curl -v -X GET "https://api.aspose.cloud/v4.0/words/Resultant.docx?format=TIFF&outPath=converted.tiff" \
-H "accept: application/octet-stream" \
-H "Authorization: Bearer <JWT Token>"
บทสรุป
การดำเนินการ OCR บน PDF เป็นกระบวนการที่สำคัญอย่างยิ่งในการปลดล็อกศักยภาพทั้งหมดของเอกสารเหล่านี้ ด้วยความช่วยเหลือของเครื่องมือ OCR บนคลาวด์ เช่น Aspose.PDF Cloud SDK สำหรับ Java กระบวนการนี้สามารถทำให้ง่ายขึ้นและเป็นอัตโนมัติ ประหยัดเวลาและเพิ่มผลผลิต ด้วยการใช้ประโยชน์จากพลังของ OCR ธุรกิจและนักพัฒนาสามารถเปลี่ยน PDF ที่ใช้รูปภาพเป็น PDF ที่ค้นหาได้ ทำให้ค้นหา แก้ไข และแชร์ได้ง่ายขึ้น เป็นที่ชัดเจนว่า API นี้มีคุณลักษณะและความสามารถที่มีประสิทธิภาพมากมายสำหรับการทำงานกับ PDF เมื่อทำตามคำแนะนำทีละขั้นตอนที่ให้ไว้ในบล็อกทางเทคนิคนี้ คุณจะเริ่มต้นใช้งาน OCR ใน PDF และนำเวิร์กโฟลว์เอกสารของคุณไปสู่อีกระดับได้
คุณอาจพิจารณาเข้าถึง API ภายในเว็บเบราว์เซอร์โดยใช้ swagger interface นอกจากนี้ เนื่องจาก SDK ของเราสร้างขึ้นภายใต้ใบอนุญาต MIT จึงสามารถดาวน์โหลดซอร์สโค้ดทั้งหมดได้จาก GitHub ในกรณีที่คุณพบปัญหาใดๆ ขณะใช้ API โปรดติดต่อเราผ่าน ฟอรัมสนับสนุนผลิตภัณฑ์ฟรี
บทความที่เกี่ยวข้อง
เราขอแนะนำให้ไปที่ลิงก์ต่อไปนี้เพื่อเรียนรู้เพิ่มเติมเกี่ยวกับ: