
تصویر پی ڈی ایف کو تلاش کے قابل پی ڈی ایف میں تبدیل کریں۔
آج کی ڈیٹا سے چلنے والی دنیا میں، PDFs دستاویزات کو ذخیرہ کرنے اور شیئر کرنے کے لیے ایک ناگزیر شکل بن چکے ہیں۔ تاہم، تمام پی ڈی ایف آسانی سے قابل تلاش یا قابل تدوین نہیں ہیں، خاص طور پر وہ جو تصویر پر مبنی ہیں۔ دستاویزات کے ساتھ کام کرتے وقت، مزید ہیرا پھیری کے لیے کسی بھی متنی معلومات کو کاپی کرنا/ نکالنا واقعی مشکل ہے۔ خوش قسمتی سے، آپٹیکل کریکٹر ریکگنیشن (او سی آر) ٹیکنالوجی کی طاقت سے، آپ تصویری پی ڈی ایف کو آسانی سے تلاش کے قابل پی ڈی ایف میں تبدیل کر سکتے ہیں۔ اس تکنیکی بلاگ میں، ہم REST API پر خاص توجہ کے ساتھ، مختلف تکنیکوں کا استعمال کرتے ہوئے OCR PDF کو تلاش کے قابل PDF میں تبدیل کرنے کا طریقہ دریافت کریں گے۔ ہم اس بات پر بھی تبادلہ خیال کریں گے کہ OCR PDFs سے متن کیسے نکالا جائے، جس سے آپ کو اس بات کی جامع تفہیم ملے گی کہ آپ کی PDF دستاویزات کی مکمل صلاحیت کو کھولنے کے لیے OCR ٹیکنالوجی کا فائدہ کیسے اٹھایا جائے۔
- جاوا SDK کا استعمال کرتے ہوئے OCR PDF
- جاوا کا استعمال کرتے ہوئے پی ڈی ایف کو تلاش کے قابل پی ڈی ایف میں اسکین کیا گیا۔
- CURL کمانڈز کا استعمال کرتے ہوئے OCR آن لائن
جاوا SDK کا استعمال کرتے ہوئے OCR PDF
Aspose.PDF Cloud SDK for Java ایک طاقتور کلاؤڈ بیسڈ API ہے جو PDF دستاویزات کے ساتھ کام کرنے کے لیے وسیع پیمانے پر خصوصیات اور صلاحیتیں پیش کرتا ہے۔ اس کی اہم خصوصیات میں سے ایک PDFs پر OCR انجام دینے کی صلاحیت ہے، جو تصویر پر مبنی PDFs سے متن نکالنے اور قابل تلاش PDFs بنانے کے عمل کو بہت آسان بنا سکتی ہے۔ اپنے صارف دوست انٹرفیس اور جامع دستاویزات کے ساتھ، یہ SDK PDFs پر OCR انجام دینے، وقت کی بچت اور پیداواری صلاحیت کو بڑھانے کے عمل کو خودکار بنانا آسان بناتا ہے۔
مزید برآں، یہ کلاؤڈ بیسڈ API مختلف قسم کے ان پٹ فارمیٹس کو ہینڈل کرنے کے لیے ڈیزائن کیا گیا ہے اور ہاتھ سے لکھے ہوئے متن کو بھی پہچان سکتا ہے، جس سے یہ کاروباروں اور ڈویلپرز کے لیے ایک بہترین انتخاب ہے جو اپنے دستاویز کے کام کے فلو کو ہموار کرنا چاہتے ہیں۔ اب پہلا مرحلہ یہ ہے کہ جاوا پروجیکٹ میں اس کا حوالہ درج ذیل تفصیلات کو شامل کرکے maven build پروجیکٹ کے pom.xml میں شامل کریں۔
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>http://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
اگر آپ کے پاس موجودہ اکاؤنٹ نہیں ہے، تو آپ کو Aspose Cloud پر ایک مفت اکاؤنٹ بنانا ہوگا۔ نئے بنائے گئے اکاؤنٹ کا استعمال کرتے ہوئے لاگ ان کریں اور [کلاؤڈ ڈیش بورڈ] پر کلائنٹ آئی ڈی اور کلائنٹ سیکریٹ تلاش/تخلیق کریں5۔ یہ تفصیلات اگلے حصوں میں درکار ہیں۔
جاوا کا استعمال کرتے ہوئے پی ڈی ایف کو تلاش کے قابل پی ڈی ایف میں اسکین کیا گیا۔
یہ سیکشن جاوا کوڈ کے ٹکڑوں کا استعمال کرتے ہوئے اسکین شدہ پی ڈی ایف کو تلاش کے قابل پی ڈی ایف میں تبدیل کرنے کے بارے میں تفصیلات بتاتا ہے۔ براہ کرم نوٹ کریں کہ Java Cloud SDK درج ذیل زبانوں کی پہچان کی حمایت کرتا ہے: eng, ara, bel, ben, bul, ces, dan, deu, ell, fin, fra, heb, hin, ind, isl, ita, jpn, kor, nld ، اور نہ ہی، پول، پور، رون، روس، سپا، سوی، تھا، تور، یوکر، وی، چسیم، چترا یا ان کا مجموعہ جیسے انگ،روس۔
- سب سے پہلے ہمیں PdfApi کا ایک آبجیکٹ بنانے کی ضرورت ہے، جہاں ہم کلائنٹ آئی ڈی اور کلائنٹ کی خفیہ تفصیلات کو بطور دلیل پیش کرتے ہیں۔
- دوم، امیج پی ڈی ایف لوڈ کرنے کے لیے فائل کلاس کی ایک مثال بنائیں
- تیسرا، کلاؤڈ اسٹوریج میں ان پٹ پی ڈی ایف کو اپ لوڈ کرنے کے لیے طریقہ uploadFile(…) کو کال کریں۔
- جیسا کہ ہماری تصویر پی ڈی ایف انگریزی متن پر مشتمل ہے، لہذا ہمیں ایک سٹرنگ آبجیکٹ بنانے کی ضرورت ہے جس کی قدر “eng” ہو
- آخر میں، طریقہ کو کال کریں putSearchableDocument(…)، جس کے لیے ایک ان پٹ پی ڈی ایف اور ایک لینگویج کوڈ بطور دلیل درکار ہے۔
ایک بار جب کوڈ کو کامیابی کے ساتھ عمل میں لایا جاتا ہے، تلاش کے قابل پی ڈی ایف کلاؤڈ اسٹوریج میں محفوظ ہوجاتا ہے۔
try
{
// https://dashboard.aspose.cloud/ سے ClientID اور ClientSecret حاصل کریں
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// تخلیق پی ڈی ایف اے پی آئی مثال
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// ان پٹ امیج پی ڈی ایف دستاویز
String name = "ScannedPDF.pdf";
// لوکل سسٹم سے فائل لوڈ کریں۔
File file = new File(name);
// فائل کو کلاؤڈ اسٹوریج پر اپ لوڈ کریں۔
FilesUploadResult uploadResponse = pdfApi.uploadFile(name, file, null);
// تصویر پی ڈی ایف میں استعمال ہونے والی زبانیں۔
String lang = "eng";
// تصویر PDF دستاویز پر OCR انجام دیں۔
AsposeResponse response = pdfApi.putSearchableDocument(name, null, null, lang);
// کامیابی کا پیغام پرنٹ کریں۔
System.out.println("OCR PDF successfull !");
}catch(Exception ex)
{
System.out.println(ex.getMessage());
}
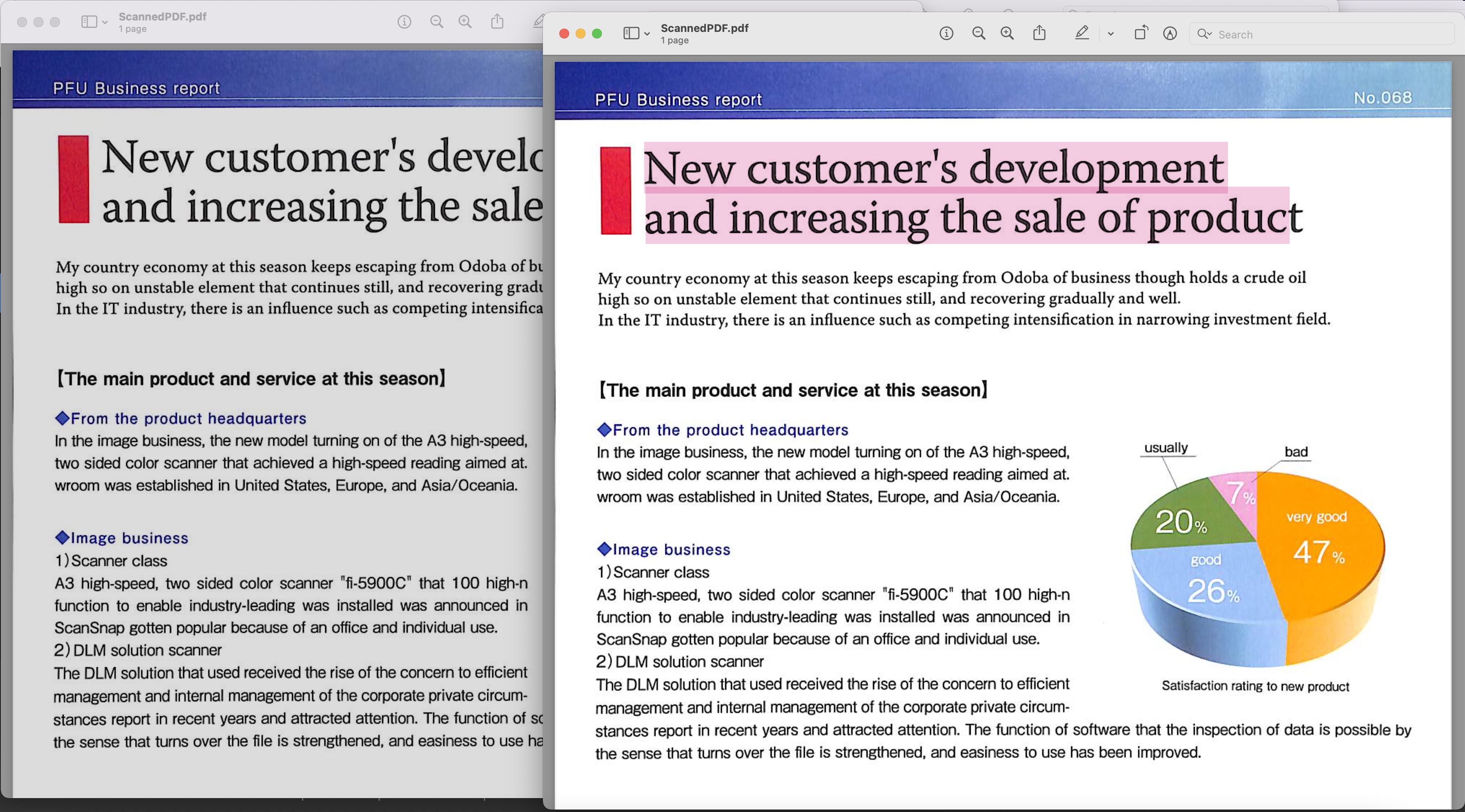
تصویر 1: - تلاش کے قابل پی ڈی ایف پیش نظارہ
مندرجہ بالا مثال میں استعمال شدہ اسکین شدہ پی ڈی ایف کو BusinessReport.pdf سے ڈاؤن لوڈ کیا جا سکتا ہے اور اس کے نتیجے میں پی ڈی ایف کو Converted.pdf سے تلاش کیا جا سکتا ہے۔
CURL کمانڈز کا استعمال کرتے ہوئے OCR آن لائن
CURL کمانڈز REST APIs کو کال کرنے کے لیے آسان طریقوں میں سے ایک ہیں۔ تو اس سیکشن میں، ہم آن لائن OCR کے لیے cURL کمانڈ استعمال کرنے جا رہے ہیں۔ اب، ایک شرط کے طور پر، ہمیں مندرجہ ذیل کمانڈ پر عمل کرتے ہوئے پہلے ایک JWT رسائی ٹوکن (کلائنٹ کی اسناد پر مبنی) بنانے کی ضرورت ہے۔
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
ہمارے پاس JWT ٹوکن ہونے کے بعد، OCR آن لائن انجام دینے اور امیج پی ڈی ایف کو تلاش کے قابل PDF دستاویز میں تبدیل کرنے کے لیے براہ کرم درج ذیل کمانڈ کو استعمال کریں۔ نتیجے کی فائل پھر کلاؤڈ اسٹوریج میں محفوظ ہوجاتی ہے۔
curl -v -X GET "https://api.aspose.cloud/v4.0/words/Resultant.docx?format=TIFF&outPath=converted.tiff" \
-H "accept: application/octet-stream" \
-H "Authorization: Bearer <JWT Token>"
نتیجہ
PDFs پر OCR کرنا ان دستاویزات کی مکمل صلاحیت کو کھولنے کے لیے ایک اہم عمل ہے۔ جاوا کے لیے Aspose.PDF Cloud SDK جیسے کلاؤڈ بیسڈ OCR ٹولز کی مدد سے، اس عمل کو آسان اور خودکار بنایا جا سکتا ہے، وقت کی بچت اور پیداواری صلاحیت میں اضافہ۔ OCR کی طاقت کا فائدہ اٹھا کر، کاروبار اور ڈیولپرز تصویر پر مبنی PDFs کو تلاش کے قابل PDFs میں تبدیل کر سکتے ہیں، جس سے انہیں تلاش، ترمیم اور اشتراک کرنا آسان ہو جاتا ہے۔ یہ واضح ہے کہ یہ API PDFs کے ساتھ کام کرنے کے لیے طاقتور خصوصیات اور صلاحیتوں کی ایک رینج پیش کرتا ہے۔ اس تکنیکی بلاگ میں فراہم کردہ مرحلہ وار گائیڈز پر عمل کرکے، آپ PDFs پر OCR کے ساتھ شروعات کر سکتے ہیں اور اپنے دستاویز کے ورک فلو کو اگلے درجے تک لے جا سکتے ہیں۔
آپ swagger انٹرفیس کا استعمال کرتے ہوئے ویب براؤزر کے اندر API تک رسائی پر غور کر سکتے ہیں۔ مزید برآں، چونکہ ہمارے SDKs ایک MIT لائسنس کے تحت بنائے گئے ہیں، اس لیے مکمل سورس کوڈ GitHub سے ڈاؤن لوڈ کیا جا سکتا ہے۔ API استعمال کرنے کے دوران اگر آپ کو کوئی مسئلہ درپیش ہو تو، براہ کرم ہم سے بلا جھجھک رابطہ کریں [مفت پروڈکٹ سپورٹ فورم9۔
متعلقہ مضامین
اس بارے میں مزید جاننے کے لیے ہم درج ذیل لنکس پر جانے کی انتہائی سفارش کرتے ہیں: