
Cloud Javaを使用してPDF画像を抽出する方法
PDF ファイルはテキストと画像コンテンツの優れたサポートを提供するため、定期的に使用しています。これらの要素をドキュメント内に配置すると、表示にどのプラットフォームを使用しても、ファイルのレイアウトは保持されます。ただし、PDF 画像を抽出する必要がある場合があります。これは PDF ビューア アプリケーションを使用して実行できますが、各ページを手動で移動し、各画像を個別に保存する必要があります。さらに、別のシナリオでは、画像ベースの PDF があり、PDF OCR を実行する必要がある場合、まずすべての画像を抽出してから、OCR 操作を実行する必要があります。大規模なドキュメントのセットがある場合、これは非常に困難になりますが、プログラムによるソリューションは信頼性が高く、迅速なソリューションになる可能性があります。そこでこの記事では、Java Cloud SDK を使用して PDF から画像を抽出するオプションを検討します。
PDFからJPGへの変換API
Java アプリケーションで PDF を JPG に、または JPG から PDF に変換するには、Aspose.PDF Cloud SDK for Java が素晴らしい選択肢です。同時に、PDF から画像を抽出したり、PDF からテキストを抽出したり、PDF から添付ファイルを抽出したりすることもでき、PDF 操作のための豊富なオプションも提供します。したがって、Java アプリケーションに PDF 画像を保存する機能を実装するには、まずプロジェクトに Cloud SDK 参照を追加する必要があります。そのため、Maven ビルド タイプ プロジェクトの pom.xml に次の詳細を追加してください。
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>https://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
SDK リファレンスが追加され、Aspose Cloud 上に既存のアカウントがない場合は、有効な電子メール アドレスを使用して無料アカウントを作成してください。次に、新しく作成したアカウントを使用してログインし、クラウド ダッシュボードでクライアント ID とクライアント シークレットを検索/作成します。これらの詳細は、次のセクションで説明する認証の目的で必要になります。
Java で PDF 画像を抽出する
PDF から画像を抽出するには、以下の手順に従ってください。操作が完了すると、画像はクラウド ストレージ上の別のフォルダーに保存されます。
- まず、ClientID と Client Secret を引数として指定して PdfApi オブジェクトを作成する必要があります。
- 次に、File インスタンスを使用して入力 PDF ファイルをロードします。
- UploadFile(…) メソッドを使用して、入力 PDF をクラウド ストレージにアップロードします
- また、オプションのパラメータを使用して、抽出された画像の高さと幅の詳細を設定します。
- 最後に putImagesExtractAsJpeg(…) メソッドを呼び出します。このメソッドは、入力 PDF 名、画像を抽出するための PageNumber、抽出された画像のサイズ、抽出された画像を保存するクラウド ストレージ上のフォルダーの名前を受け取ります。
try
{
// https://dashboard.aspose.cloud/ から ClientID と ClientSecret を取得します。
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// PdfApi のインスタンスを作成する
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// 入力された PDF ドキュメントの名前
String inputFile = "marketing.pdf";
// 入力された PDF ファイルの内容を読み取る
File file = new File("//Users//"+inputFile);
// PDFをクラウドストレージにアップロードする
pdfApi.uploadFile("input.pdf", file, null);
// 画像を抽出する PDF のページ
int pageNumber =1;
// 抽出された画像の幅
int width = 600;
// 抽出された画像の高さ
int height = 800;
// 抽出した画像を保存するフォルダー
String folderName = "NewFolder";
// PDF画像を抽出してクラウドストレージに保存
pdfApi.putImagesExtractAsJpeg(inputFile, pageNumber, width, height, null, null, folderName);
// 成功メッセージを出力する
System.out.println("PDF images Successsuly extracted !");
}catch(Exception ex)
{
System.out.println(ex);
}
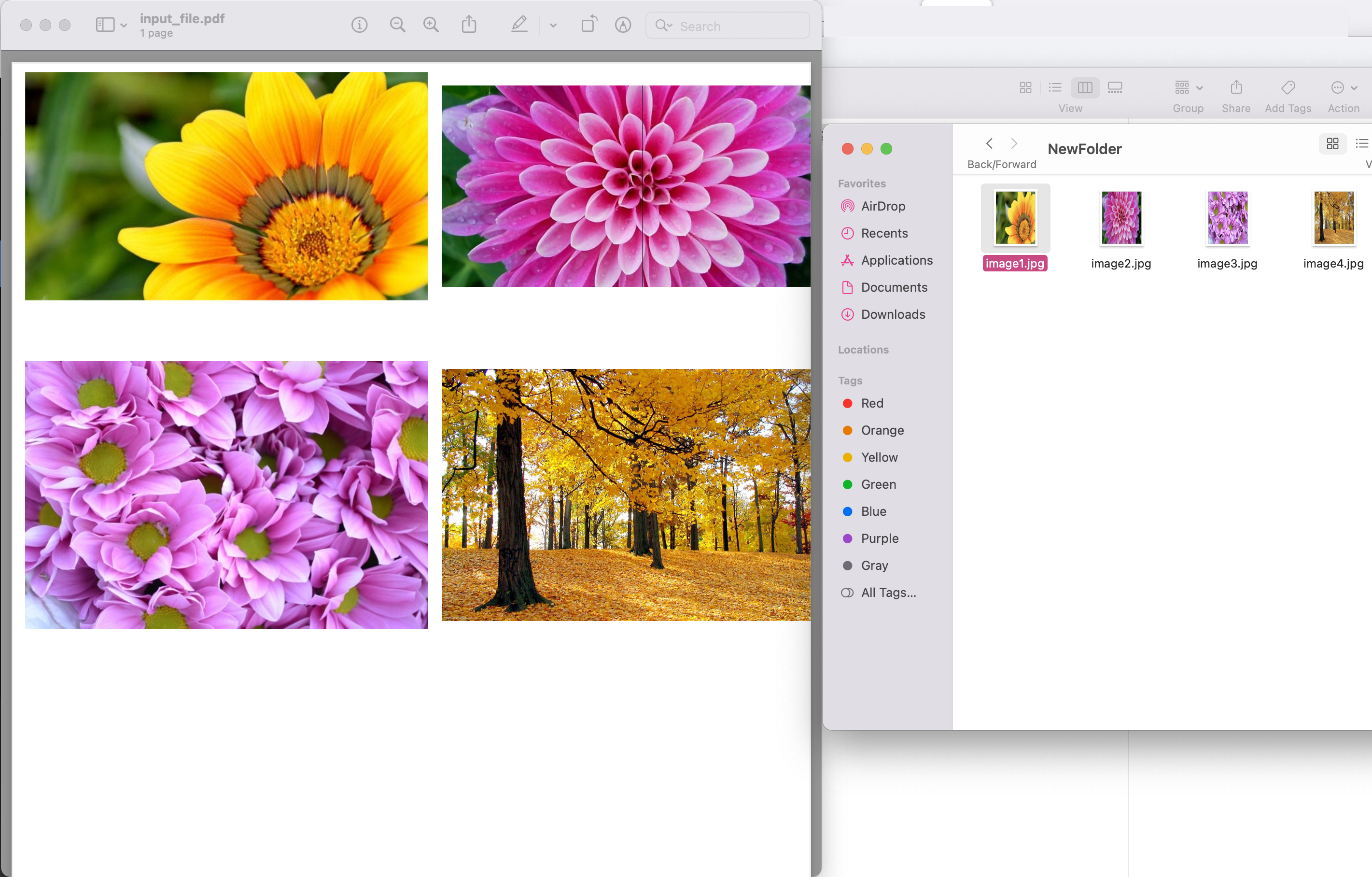
画像 1:- PDF 画像の抽出プレビュー
上記の例で使用されているサンプル PDF ファイルは、input.pdf からダウンロードできます。
cURL コマンドを使用して PDF 画像を保存する
次に、cURL コマンドを使用して PDF 画像抽出用の API を呼び出します。このアプローチの前提条件として、まず次のコマンドの実行中に (クライアントの資格情報に基づいて) JWT アクセス トークンを生成する必要があります。
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
JWT トークンを取得したら、次のコマンドを実行して、PDF 画像をクラウド ストレージ上の別のフォルダーに保存してください。
curl -X PUT "https://api.aspose.cloud/v3.0/pdf/input_file.pdf/pages/1/images/extract/jpeg?width=0&height=0&destFolder=NewFolder" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
結論
この記事を読んだ後は、Java コード スニペットと cURL コマンドを使用して PDF 画像を抽出するための、シンプルかつ信頼性の高いアプローチを学習したことになります。お気づきのとおり、PDF ファイルの指定されたページから画像を抽出する機能が得られ、抽出プロセスをより詳細に制御できるようになります。製品 ドキュメント には、この API の機能をさらに説明する一連の素晴らしいトピックが充実しています。
また、すべての Cloud SDK は MIT ライセンスに基づいて公開されているため、GitHub から完全なソース コードをダウンロードし、要件に応じて変更することを検討することもできます。問題が発生した場合は、無料の 製品サポート フォーラム を通じて迅速に解決するために当社に連絡することを検討してください。
関連記事
詳細については、次のリンクを参照してください。