
Kā izvilkt PDF attēlus, izmantojot Cloud Java
Mēs regulāri izmantojam PDF failus, jo tie nodrošina pārsteidzošu atbalstu teksta un attēlu saturam. Kad šie elementi ir ievietoti dokumentā, faila izkārtojums tiek saglabāts neatkarīgi no platformas, kuru izmantojat to skatīšanai. Taču mums var būt prasība iegūt PDF attēlus. To var paveikt, izmantojot PDF skatītāja lietojumprogrammu, taču jums ir manuāli jāpārvietojas cauri katrai lapai un atsevišķi jāsaglabā katrs attēls. Turklāt citā scenārijā, ja jums ir uz attēlu balstīts PDF un jums ir jāveic PDF OCR, vispirms ir jāizņem visi attēli un pēc tam jāveic OCR darbība. Tas kļūst ļoti sarežģīti, ja jums ir liels dokumentu kopums, taču programmatisks risinājums var būt uzticams un ātrs risinājums. Tāpēc šajā rakstā mēs izpētīsim iespējas, kā iegūt attēlus no PDF, izmantojot Java Cloud SDK
- PDF uz JPG konvertēšanas API
- Izņemiet PDF attēlus Java
- Saglabājiet PDF attēlus, izmantojot cURL komandas
PDF uz JPG konvertēšanas API
Lai Java lietojumprogrammā pārvērstu PDF formātā JPG vai JPG formātā PDF formātā, Aspose.PDF Cloud SDK for Java ir lieliska izvēle. Tajā pašā laikā tas arī ļauj iegūt attēlus no PDF, tekstu izvilkt no PDF, izvilkt pielikumus no PDF, kā arī nodrošina daudz iespēju PDF manipulācijām. Tātad, lai ieviestu PDF attēlu saglabāšanas funkciju Java lietojumprogrammā, vispirms mūsu projektā ir jāpievieno Cloud SDK atsauce. Tāpēc, lūdzu, pievienojiet tālāk norādīto informāciju maven build tipa projekta pom.xml.
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>http://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
Kad SDK atsauce ir pievienota un jums nav neviena konta pakalpojumā Aspose Cloud, lūdzu, izveidojiet bezmaksas kontu, izmantojot derīgu e-pasta adresi. Pēc tam piesakieties, izmantojot jaunizveidoto kontu, un vietnē Cloud Dashboard atrodiet/izveidojiet klienta ID un klienta noslēpumu. Šī informācija ir nepieciešama autentifikācijas nolūkos nākamajās sadaļās.
Izņemiet PDF attēlus Java
Lūdzu, veiciet tālāk norādītās darbības, lai izvilktu attēlus no PDF, un, kad darbība ir pabeigta, attēli tiek saglabāti atsevišķā mākoņkrātuves mapē.
- Vispirms mums ir jāizveido PdfApi objekts, vienlaikus nodrošinot ClientID un Client Secret kā argumentus
- Otrkārt, ielādējiet ievades PDF failu, izmantojot failu instanci
- Augšupielādējiet ievades PDF failu mākoņkrātuvē, izmantojot metodi uploadFile(…).
- Mēs arī izmantosim izvēles parametru, lai iestatītu informāciju par augstumu un platumu iegūtajiem attēliem
- Visbeidzot izsauciet metodi putImagesExtractAsJpeg(…), kas izmanto ievades PDF nosaukumu, PageNumber attēlu izvilkšanai, izvilkto attēlu izmērus un mapes nosaukumu mākoņkrātuvē, lai saglabātu izvilktos attēlus.
try
{
// Iegūstiet ClientID un ClientSecret no https://dashboard.aspose.cloud/
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// izveidot PdfApi gadījumu
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// ievades PDF dokumenta nosaukums
String inputFile = "marketing.pdf";
// lasīt ievades PDF faila saturu
File file = new File("//Users//"+inputFile);
// augšupielādējiet PDF failu mākoņa krātuvē
pdfApi.uploadFile("input.pdf", file, null);
// PDF lapa attēlu iegūšanai
int pageNumber =1;
// platums izvilktajiem attēliem
int width = 600;
// izvilkto attēlu augstums
int height = 800;
// mapi, lai saglabātu izvilktos attēlus
String folderName = "NewFolder";
// Izņemiet PDF attēlus un saglabājiet tos mākoņkrātuvē
pdfApi.putImagesExtractAsJpeg(inputFile, pageNumber, width, height, null, null, folderName);
// izdrukāt veiksmes ziņojumu
System.out.println("PDF images Successsuly extracted !");
}catch(Exception ex)
{
System.out.println(ex);
}
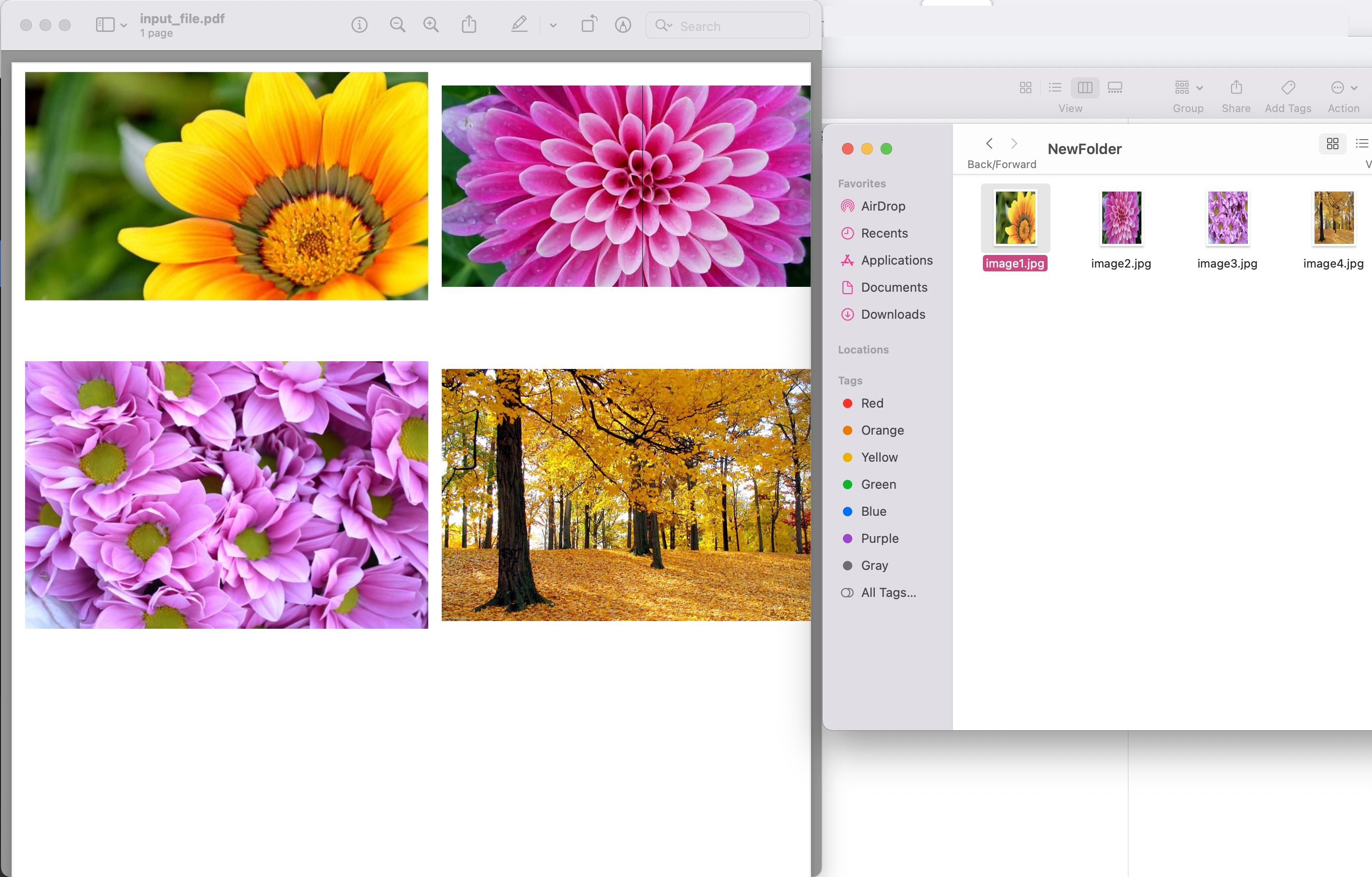
Attēls1: - izņemiet PDF attēlu priekšskatījumu
Iepriekš minētajā piemērā izmantoto PDF faila paraugu var lejupielādēt no input.pdf.
Saglabājiet PDF attēlus, izmantojot cURL komandas
Tagad mēs izsauksim API PDF attēlu iegūšanai, izmantojot cURL komandas. Tagad kā šīs pieejas priekšnoteikums mums vispirms ir jāģenerē JWT piekļuves marķieris (pamatojoties uz klienta akreditācijas datiem), vienlaikus izpildot šo komandu.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Kad esam ieguvuši JWT marķieri, lūdzu, izpildiet šo komandu, lai saglabātu PDF attēlus atsevišķā mapē mākoņkrātuvē.
curl -X PUT "https://api.aspose.cloud/v3.0/pdf/input_file.pdf/pages/1/images/extract/jpeg?width=0&height=0&destFolder=NewFolder" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Secinājums
Pēc šī raksta izlasīšanas jūs esat iemācījušies vienkāršu, bet uzticamu pieeju PDF attēlu iegūšanai, izmantojot Java koda fragmentu, kā arī cURL komandas. Kā esam pamanījuši, mēs iegūstam sviras efektu, lai izvilktu attēlus no norādītās PDF faila lapas, un tas nodrošina lielāku ieguves procesa kontroli. Produkts Dokumentācija ir bagātināts ar virkni pārsteidzošu tēmu, kas sīkāk izskaidro šīs API iespējas.
Turklāt, tā kā visi mūsu mākoņa SDK ir publicēti saskaņā ar MIT licenci, varat apsvērt iespēju lejupielādēt visu avota kodu no GitHub un pārveidot to atbilstoši savām prasībām. Ja rodas problēmas, varat sazināties ar mums, lai ātri atrisinātu to, izmantojot bezmaksas produktu atbalsta forumu.
Saistītie raksti
Lūdzu, apmeklējiet šīs saites, lai uzzinātu vairāk par: