
PDF-afbeeldingen extraheren met Cloud Java
We gebruiken regelmatig PDF-bestanden omdat ze een geweldige ondersteuning bieden voor tekst- en afbeeldingsinhoud. Zodra deze elementen in het document zijn geplaatst, blijft de lay-out van het bestand behouden, ongeacht het platform dat u gebruikt om ze te bekijken. Maar het kan zijn dat we PDF-afbeeldingen moeten extraheren. Dit kan worden bereikt met behulp van de PDF-viewertoepassing, maar u moet handmatig door elke pagina bladeren en elke afbeelding afzonderlijk opslaan. Bovendien, in een ander scenario, als u een op afbeeldingen gebaseerde PDF hebt en u PDF OCR moet uitvoeren, moet u eerst alle afbeeldingen extraheren en vervolgens de OCR-bewerking uitvoeren. Dit wordt echt moeilijk als u een grote set documenten heeft, maar een programmatische oplossing kan een betrouwbare en snelle oplossing zijn. Dus in dit artikel gaan we de opties verkennen om afbeeldingen uit PDF te extraheren met behulp van Java Cloud SDK
- PDF naar JPG-conversie-API
- Extraheer PDF-afbeeldingen in Java
- Sla PDF-afbeeldingen op met cURL-opdrachten
PDF naar JPG-conversie-API
Om PDF naar JPG of JPG naar PDF in Java-applicatie te converteren, is Aspose.PDF Cloud SDK voor Java een geweldige keuze. Tegelijkertijd stelt het u ook in staat om afbeeldingen uit PDF te extraheren, tekst uit PDF te extraheren, bijlagen uit PDF te extraheren en biedt het een overvloed aan opties voor PDF-manipulatie. Dus om de functie voor het opslaan van PDF-afbeeldingen in de Java-toepassing te implementeren, moeten we eerst de Cloud SDK-referentie aan ons project toevoegen. Voeg dus de volgende details toe in pom.xml van het maven build-type project.
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>http://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
Zodra de SDK-referentie is toegevoegd en u geen bestaand account heeft via Aspose Cloud, maakt u een gratis account aan met een geldig e-mailadres. Log vervolgens in met een nieuw aangemaakt account en zoek/maak Client ID en Client Secret op bij Cloud Dashboard. Deze details zijn vereist voor authenticatiedoeleinden in de volgende secties.
Extraheer PDF-afbeeldingen in Java
Volg de onderstaande stappen om afbeeldingen uit PDF te extraheren en zodra de bewerking is voltooid, worden de afbeeldingen opgeslagen in een aparte map op Cloud-opslag.
- Eerst moeten we een PdfApi-object maken terwijl we ClientID en Client-geheim als argumenten opgeven
- Ten tweede laadt u het ingevoerde PDF-bestand met behulp van File instance
- Upload de ingevoerde PDF naar cloudopslag met behulp van de methode uploadFile(…).
- We gaan ook een optionele parameter gebruiken om hoogte- en breedtedetails in te stellen voor geëxtraheerde afbeeldingen
- Roep ten slotte de methode putImagesExtractAsJpeg(…) aan die de ingevoerde PDF-naam, het paginanummer nodig heeft om afbeeldingen te extraheren, de afmetingen van de geëxtraheerde afbeeldingen en de naam van de map op cloudopslag om de geëxtraheerde afbeeldingen op te slaan
try
{
// Haal ClientID en ClientSecret op van https://dashboard.aspose.cloud/
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// maak een instantie van PdfApi
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// naam van het ingevoerde PDF-document
String inputFile = "marketing.pdf";
// lees de inhoud van het ingevoerde PDF-bestand
File file = new File("//Users//"+inputFile);
// upload PDF naar cloudopslag
pdfApi.uploadFile("input.pdf", file, null);
// Pagina van PDF om afbeeldingen te extraheren
int pageNumber =1;
// breedte voor geëxtraheerde afbeeldingen
int width = 600;
// hoogte van geëxtraheerde afbeeldingen
int height = 800;
// map om uitgepakte afbeeldingen op te slaan
String folderName = "NewFolder";
// Pak PDF-afbeeldingen uit en sla ze op in Cloud Storage
pdfApi.putImagesExtractAsJpeg(inputFile, pageNumber, width, height, null, null, folderName);
// succesbericht afdrukken
System.out.println("PDF images Successsuly extracted !");
}catch(Exception ex)
{
System.out.println(ex);
}
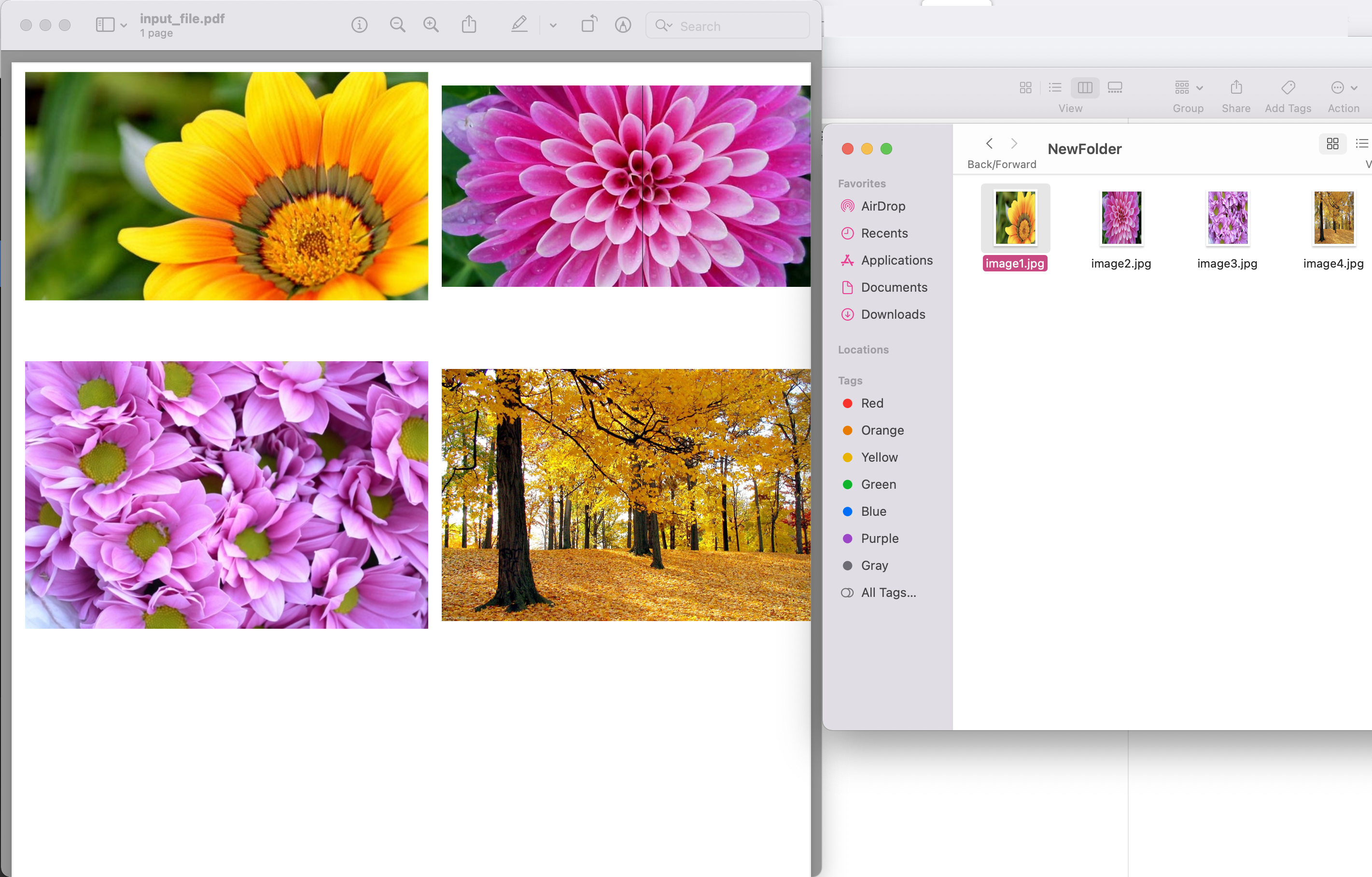
Image1: - Voorbeeld van PDF-afbeeldingen extraheren
Het voorbeeld-pdf-bestand dat in het bovenstaande voorbeeld wordt gebruikt, kan worden gedownload van input.pdf.
Sla PDF-afbeeldingen op met cURL-opdrachten
Nu gaan we de API aanroepen voor het extraheren van PDF-afbeeldingen met behulp van cURL-opdrachten. Als voorwaarde voor deze benadering moeten we eerst een JWT-toegangstoken genereren (op basis van clientreferenties) terwijl we de volgende opdracht uitvoeren.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Zodra we het JWT-token hebben, voert u de volgende opdracht uit om PDF-afbeeldingen op te slaan in een aparte map via cloudopslag.
curl -X PUT "https://api.aspose.cloud/v3.0/pdf/input_file.pdf/pages/1/images/extract/jpeg?width=0&height=0&destFolder=NewFolder" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Conclusie
Na het lezen van dit artikel heb je een eenvoudige maar betrouwbare aanpak geleerd voor het extraheren van PDF-afbeeldingen met behulp van Java-codefragmenten en via cURL-opdrachten. Zoals we hebben gemerkt, krijgen we een hefboomeffect om afbeeldingen van een bepaalde pagina van het PDF-bestand te extraheren en bieden we meer controle over het extractieproces. Het product Documentatie is verrijkt met een reeks geweldige onderwerpen die de mogelijkheden van deze API verder toelichten.
Aangezien al onze Cloud SDK’s onder een MIT-licentie worden gepubliceerd, kunt u overwegen de volledige broncode van GitHub te downloaden en deze naar wens aan te passen. In geval van problemen kunt u overwegen ons te benaderen voor een snelle oplossing via het gratis productondersteuningsforum.
gerelateerde artikelen
Bezoek de volgende links voor meer informatie over: