
Cloud Java를 사용하여 PDF 이미지를 추출하는 방법
텍스트 및 이미지 콘텐츠에 대한 놀라운 지원을 제공하는 PDF 파일을 정기적으로 사용합니다. 이러한 요소가 문서 내부에 배치되면 해당 요소를 보기 위해 사용하는 플랫폼에 관계없이 파일의 레이아웃이 유지됩니다. 그러나 PDF 이미지를 추출해야 하는 요구 사항이 있을 수 있습니다. 이것은 PDF 뷰어 응용 프로그램을 사용하여 수행할 수 있지만 각 페이지를 수동으로 탐색하고 각 이미지를 개별적으로 저장해야 합니다. 또한 다른 시나리오에서는 이미지 기반 PDF가 있고 PDF OCR을 수행해야 하는 경우 먼저 모든 이미지를 추출한 다음 OCR 작업을 수행해야 합니다. 많은 양의 문서가 있을 때 이것은 정말 어려운 일이지만 프로그래밍 방식의 솔루션이 안정적이고 빠른 솔루션이 될 수 있습니다. 따라서 이 기사에서는 Java Cloud SDK를 사용하여 PDF에서 이미지를 추출하는 옵션을 살펴보겠습니다.
PDF에서 JPG로 변환 API
Java 애플리케이션에서 PDF를 JPG로 또는 JPG를 PDF로 변환하려면 Aspose.PDF Java용 Cloud SDK가 놀라운 선택입니다. 동시에 PDF에서 이미지를 추출하고, PDF에서 텍스트를 추출하고, PDF에서 첨부 파일을 추출할 수 있을 뿐만 아니라 PDF 조작을 위한 다양한 옵션을 제공합니다. 따라서 Java 애플리케이션에서 PDF 이미지를 저장하는 기능을 구현하려면 먼저 프로젝트에 Cloud SDK 참조를 추가해야 합니다. 따라서 maven 빌드 타입 프로젝트의 pom.xml에 다음 내용을 추가해 주세요.
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>https://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
SDK 참조가 추가되고 Aspose Cloud에 대한 기존 계정이 없으면 유효한 이메일 주소를 사용하여 무료 계정을 만드십시오. 그런 다음 새로 생성된 계정으로 로그인하고 클라우드 대시보드에서 클라이언트 ID와 클라이언트 시크릿을 조회/생성합니다. 이러한 세부 정보는 다음 섹션에서 인증 목적으로 필요합니다.
Java에서 PDF 이미지 추출
아래 단계에 따라 PDF에서 이미지를 추출하고 작업이 완료되면 이미지는 클라우드 저장소의 별도 폴더에 저장됩니다.
- 먼저 ClientID와 Client secret을 인수로 제공하면서 PdfApi 객체를 생성해야 합니다.
- 둘째, File 인스턴스를 사용하여 입력 PDF 파일을 로드합니다.
- uploadFile(…) 메서드를 사용하여 입력 PDF를 클라우드 스토리지에 업로드합니다.
- 또한 선택적 매개변수를 사용하여 추출된 이미지의 높이 및 너비 세부 정보를 설정합니다.
- 마지막으로 putImagesExtractAsJpeg(…) 메서드를 호출하여 PDF 이름 입력, 이미지 추출을 위한 PageNumber, 추출된 이미지 크기 및 클라우드 스토리지의 폴더 이름을 가져와 추출된 이미지를 저장합니다.
try
{
// https://dashboard.aspose.cloud/에서 ClientID 및 ClientSecret 가져오기
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// PdfApi 인스턴스 생성
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// 입력 PDF 문서의 이름
String inputFile = "marketing.pdf";
// 입력된 PDF 파일의 내용 읽기
File file = new File("//Users//"+inputFile);
// 클라우드 스토리지에 PDF 업로드
pdfApi.uploadFile("input.pdf", file, null);
// 이미지를 추출하는 PDF 페이지
int pageNumber =1;
// 추출된 이미지의 너비
int width = 600;
// 추출된 이미지의 높이
int height = 800;
// 추출된 이미지를 저장할 폴더
String folderName = "NewFolder";
// PDF 이미지 추출 및 Cloud Storage에 저장
pdfApi.putImagesExtractAsJpeg(inputFile, pageNumber, width, height, null, null, folderName);
// 인쇄 성공 메시지
System.out.println("PDF images Successsuly extracted !");
}catch(Exception ex)
{
System.out.println(ex);
}
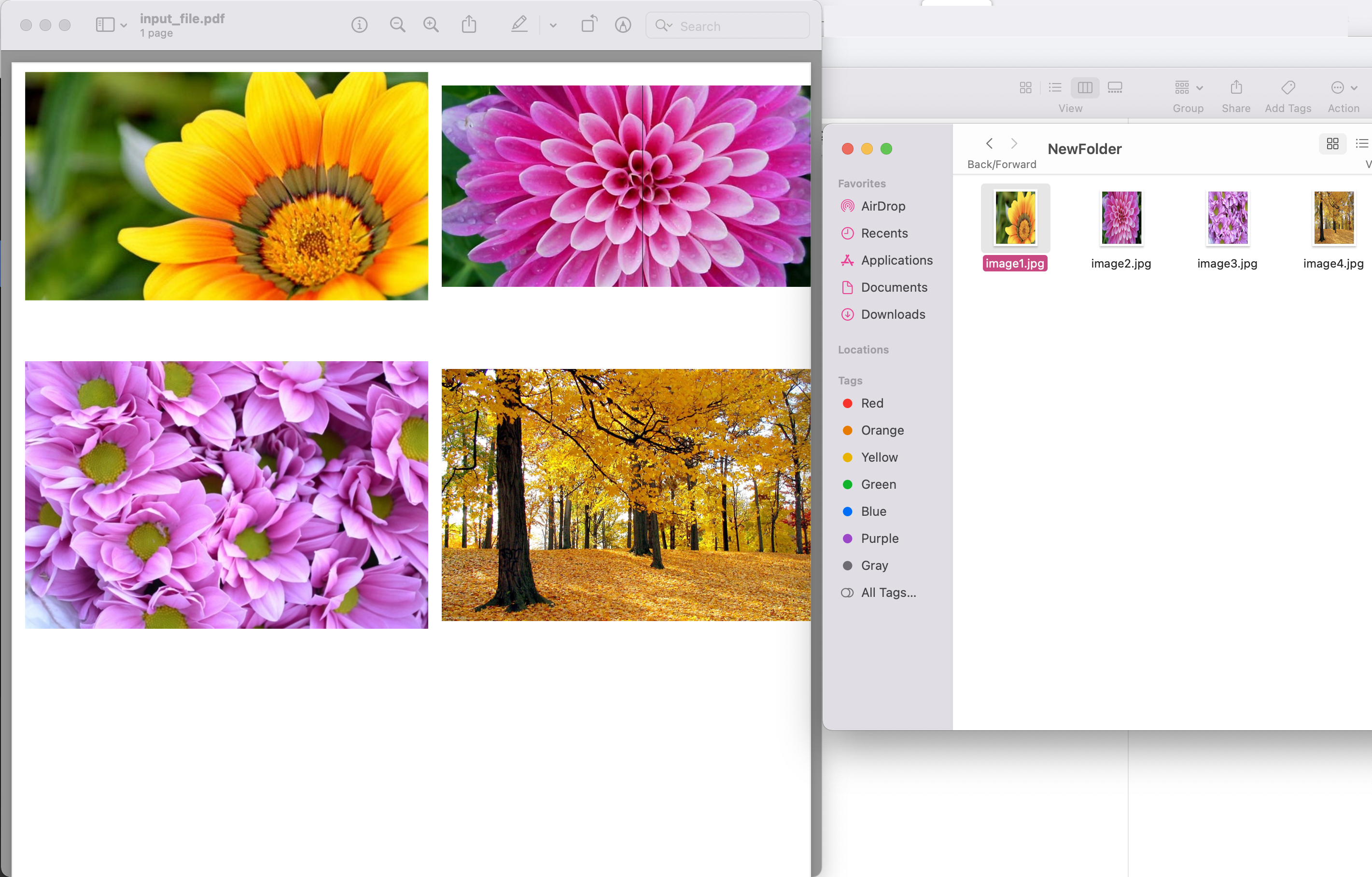
Image1:- PDF 이미지 추출 미리보기
위 예제에서 사용된 샘플 PDF 파일은 input.pdf에서 다운로드할 수 있습니다.
cURL 명령을 사용하여 PDF 이미지 저장
이제 cURL 명령을 사용하여 PDF 이미지 추출을 위한 API를 호출할 것입니다. 이제 이 접근 방식의 전제 조건으로 먼저 다음 명령을 실행하는 동안 JWT 액세스 토큰(클라이언트 자격 증명 기반)을 생성해야 합니다.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
JWT 토큰이 있으면 다음 명령을 실행하여 클라우드 스토리지를 통해 별도의 폴더에 PDF 이미지를 저장하십시오.
curl -X PUT "https://api.aspose.cloud/v3.0/pdf/input_file.pdf/pages/1/images/extract/jpeg?width=0&height=0&destFolder=NewFolder" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
결론
이 기사를 읽은 후 Java 코드 스니펫과 cURL 명령을 사용하여 PDF 이미지를 추출하는 간단하면서도 안정적인 접근 방식을 배웠습니다. 알다시피 PDF 파일의 지정된 페이지에서 이미지를 추출하고 추출 프로세스를 더 많이 제어할 수 있습니다. 제품 문서에는 이 API의 기능을 추가로 설명하는 다양한 놀라운 주제가 포함되어 있습니다.
또한 모든 Cloud SDK는 MIT 라이선스로 게시되므로 GitHub에서 전체 소스 코드를 다운로드하고 요구 사항에 따라 수정할 수 있습니다. 문제가 있는 경우 무료 제품 지원 포럼을 통해 빠른 해결을 위해 당사에 연락하는 것을 고려할 수 있습니다.
관련 기사
자세한 내용은 다음 링크를 참조하십시오.