
نحوه استخراج تصاویر PDF با استفاده از Cloud Java
ما مرتباً از فایلهای PDF استفاده میکنیم زیرا پشتیبانی شگفتانگیزی برای محتوای متن و تصویر ارائه میدهند. هنگامی که این عناصر در داخل سند قرار می گیرند، طرح بندی فایل بدون توجه به پلت فرمی که برای مشاهده آنها استفاده می کنید حفظ می شود. اما، ممکن است نیاز به استخراج تصاویر PDF داشته باشیم. این را می توان با استفاده از برنامه نمایشگر PDF انجام داد، اما باید به صورت دستی از هر صفحه عبور کرده و هر تصویر را به صورت جداگانه ذخیره کنید. علاوه بر این، در یک سناریوی دیگر، اگر PDF مبتنی بر تصویر دارید و باید PDF OCR را انجام دهید، ابتدا باید تمام تصاویر را استخراج کنید و سپس عملیات OCR را انجام دهید. زمانی که مجموعه وسیعی از اسناد دارید، این کار واقعاً مشکل می شود، اما یک راه حل برنامه ای می تواند یک راه حل قابل اعتماد و سریع باشد. بنابراین در این مقاله قصد داریم گزینه های استخراج تصاویر از PDF با استفاده از Java Cloud SDK را بررسی کنیم
API تبدیل PDF به JPG
برای تبدیل PDF به JPG یا JPG به PDF در برنامه جاوا، Aspose.PDF Cloud SDK for Java یک انتخاب شگفت انگیز است. در عین حال، شما را قادر می سازد تصاویر را از PDF استخراج کنید، متن را از PDF استخراج کنید، پیوست ها را از PDF استخراج کنید و همچنین گزینه های زیادی برای دستکاری PDF فراهم می کند. بنابراین برای پیاده سازی قابلیت ذخیره تصاویر PDF در برنامه جاوا، ابتدا باید مرجع Cloud SDK را در پروژه خود اضافه کنیم. بنابراین لطفا جزئیات زیر را در pom.xml پروژه ساخت Maven اضافه کنید.
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>https://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
هنگامی که مرجع SDK اضافه شد و هیچ حساب موجودی روی Aspose Cloud ندارید، لطفاً با استفاده از آدرس ایمیل معتبر یک حساب رایگان ایجاد کنید. سپس با استفاده از حساب تازه ایجاد شده وارد شوید و Client ID و Client Secret را در Cloud Dashboard جستجو/ایجاد کنید. این جزئیات برای اهداف احراز هویت در بخشهای زیر مورد نیاز است.
استخراج تصاویر PDF در جاوا
لطفاً مراحل زیر را برای استخراج تصاویر از PDF دنبال کنید و پس از اتمام عملیات، تصاویر در پوشه جداگانه در فضای ذخیره سازی ابری ذخیره می شوند.
- ابتدا باید یک شی PdfApi ایجاد کنیم و در عین حال ClientID و Client Secret را به عنوان آرگومان ارائه کنیم
- در مرحله دوم، فایل PDF ورودی را با استفاده از نمونه File بارگیری کنید
- PDF ورودی را با استفاده از روش uploadFile(…) در فضای ذخیره سازی ابری آپلود کنید
- همچنین قصد داریم از یک پارامتر اختیاری برای تنظیم جزئیات ارتفاع و عرض برای تصاویر استخراج شده استفاده کنیم
- در نهایت متد putImagesExtractAsJpeg(…) را فراخوانی کنید که نام PDF ورودی، PageNumber برای استخراج تصاویر، ابعاد تصاویر استخراج شده و نام پوشه در فضای ذخیره سازی ابری را برای ذخیره تصاویر استخراج شده می گیرد.
try
{
// ClientID و ClientSecret را از https://dashboard.aspose.cloud/ دریافت کنید
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// یک نمونه از PdfApi ایجاد کنید
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// نام سند PDF ورودی
String inputFile = "marketing.pdf";
// محتوای فایل PDF ورودی را بخوانید
File file = new File("//Users//"+inputFile);
// PDF را در فضای ذخیره سازی ابری آپلود کنید
pdfApi.uploadFile("input.pdf", file, null);
// صفحه PDF برای استخراج تصاویر
int pageNumber =1;
// عرض برای تصاویر استخراج شده
int width = 600;
// ارتفاع تصاویر استخراج شده
int height = 800;
// پوشه برای ذخیره تصاویر استخراج شده
String folderName = "NewFolder";
// تصاویر PDF را استخراج کنید و در فضای ذخیره سازی ابری ذخیره کنید
pdfApi.putImagesExtractAsJpeg(inputFile, pageNumber, width, height, null, null, folderName);
// پیام موفقیت چاپ
System.out.println("PDF images Successsuly extracted !");
}catch(Exception ex)
{
System.out.println(ex);
}
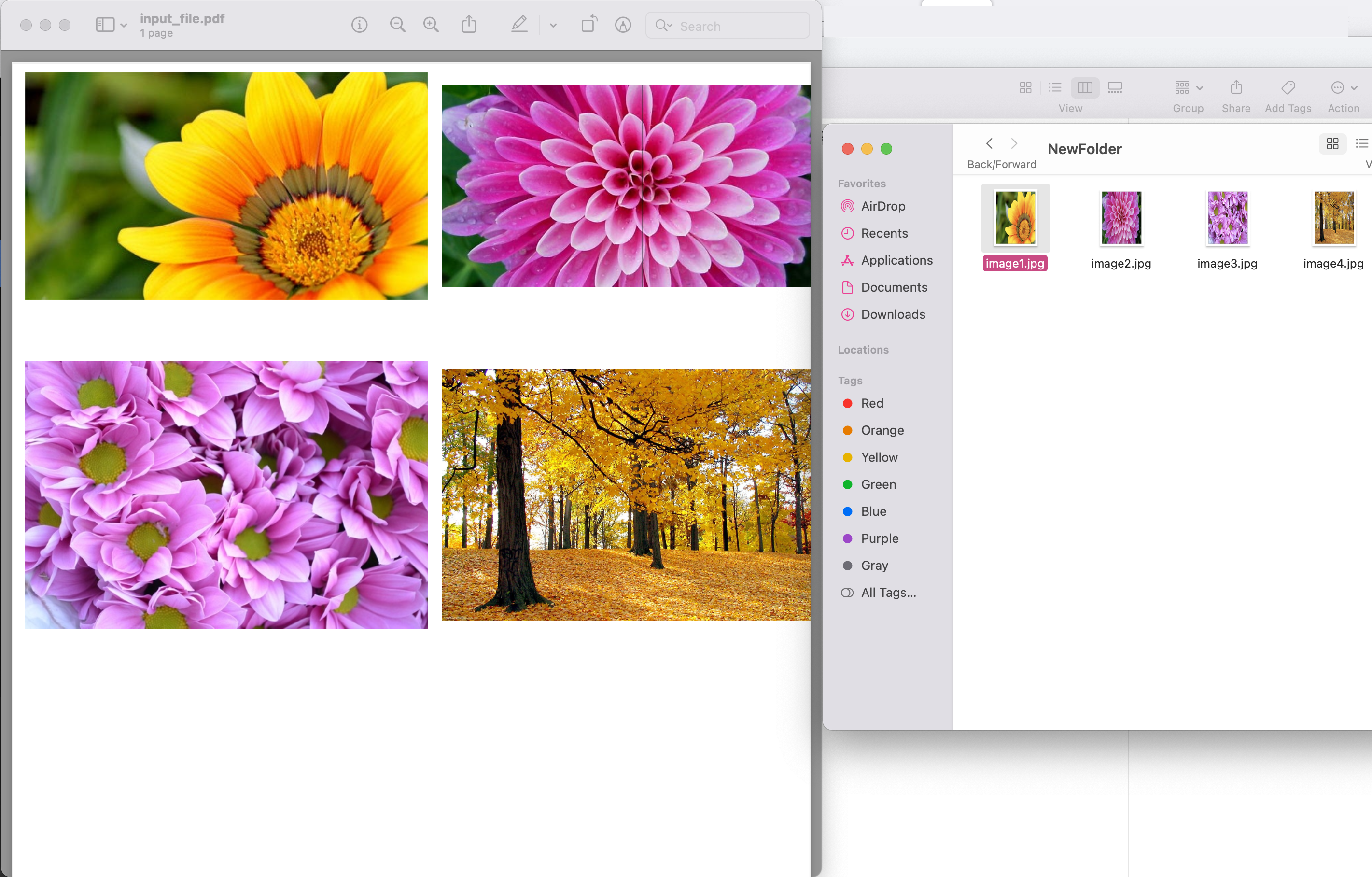
Image1: - پیش نمایش تصاویر PDF را استخراج کنید
نمونه فایل PDF مورد استفاده در مثال بالا را می توان از input.pdf دانلود کرد.
تصاویر PDF را با استفاده از دستورات cURL ذخیره کنید
اکنون می خواهیم API را برای استخراج تصاویر PDF با استفاده از دستورات cURL فراخوانی کنیم. اکنون به عنوان پیش نیاز این رویکرد، ابتدا باید یک توکن دسترسی JWT (بر اساس اعتبار مشتری) در حین اجرای دستور زیر تولید کنیم.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
پس از دریافت رمز JWT، لطفاً دستور زیر را برای ذخیره تصاویر PDF در پوشه جداگانه در فضای ذخیره سازی ابری اجرا کنید.
curl -X PUT "https://api.aspose.cloud/v3.0/pdf/input_file.pdf/pages/1/images/extract/jpeg?width=0&height=0&destFolder=NewFolder" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
نتیجه
پس از خواندن این مقاله، یک روش ساده و در عین حال قابل اعتماد برای استخراج تصاویر PDF با استفاده از قطعه کد جاوا و همچنین از طریق دستورات cURL را آموختید. همانطور که متوجه شدیم، ما اهرمی برای استخراج تصاویر از صفحه مشخص شده فایل PDF دریافت می کنیم و کنترل بیشتری بر فرآیند استخراج فراهم می کنیم. محصول اسناد با مجموعه ای از موضوعات شگفت انگیز غنی شده است که قابلیت های این API را بیشتر توضیح می دهد.
همچنین، از آنجایی که همه کیتهای توسعه نرمافزار ابری ما تحت مجوز MIT منتشر شدهاند، میتوانید کد منبع کامل را از GitHub دانلود کنید و آن را مطابق با نیاز خود تغییر دهید. در صورت بروز هر گونه مشکلی، می توانید برای حل سریع از طریق [تالار گفتمان پشتیبانی محصول] رایگان به ما مراجعه کنید.
مقالات مرتبط
لطفا برای کسب اطلاعات بیشتر به لینک های زیر مراجعه کنید: