
如何使用 Cloud Java 提取 PDF 图像
我们经常使用 PDF 文件,因为它们为文本和图像内容提供了惊人的支持。一旦将这些元素放入文档中,无论您使用哪个平台查看它们,文件的布局都会被保留。但是,我们可能需要提取 PDF 图像。这可以使用 PDF 查看器应用程序来完成,但您需要手动遍历每个页面并单独保存每个图像。此外,在另一种情况下,如果您有基于图像的 PDF,并且需要执行 PDF OCR,那么您需要先提取所有图像,然后执行 OCR 操作。当您拥有大量文档时,这会变得非常困难,但编程解决方案可能是可靠且快速的解决方案。因此,在本文中,我们将探索使用 Java Cloud SDK 从 PDF 中提取图像的选项
PDF 到 JPG 转换 API
为了在 Java 应用程序中将 PDF 转换为 JPG 或将 JPG 转换为 PDF,Aspose.PDF Cloud SDK for Java 是一个了不起的选择。同时,它还使您能够从 PDF 中提取图像、从 PDF 中提取文本、从 PDF 中提取附件以及提供大量的 PDF 操作选项。因此,为了在 Java 应用程序中实现保存 PDF 图片的功能,首先我们需要在我们的项目中添加 Cloud SDK 引用。因此,请在 maven 构建类型项目的 pom.xml 中添加以下详细信息。
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>https://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
一旦添加了 SDK 参考并且您没有任何现有的 Aspose Cloud 帐户,请使用有效的电子邮件地址创建一个免费帐户。然后使用新创建的帐户登录并在 Cloud Dashboard 查找/创建客户端 ID 和客户端密码。在以下部分中,出于身份验证目的需要这些详细信息。
在 Java 中提取 PDF 图像
请按照以下步骤从 PDF 中提取图像,操作完成后,图像将存储在云存储上的单独文件夹中。
- 首先,我们需要创建一个 PdfApi 对象,同时提供 ClientID 和 Client secret 作为参数
- 其次,使用 File 实例加载输入 PDF 文件
- 使用 uploadFile(…) 方法将输入的 PDF 上传到云存储
- 我们还将使用一个可选参数来设置提取图像的高度和宽度细节
- 最后调用 putImagesExtractAsJpeg(…) 方法,输入 PDF 名称、提取图像的页码、提取图像的尺寸和云存储上保存提取图像的文件夹名称
try
{
// 从 https://dashboard.aspose.cloud/ 获取 ClientID 和 ClientSecret
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// 创建 PdfApi 的实例
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// 输入 PDF 文档的名称
String inputFile = "marketing.pdf";
// 读取输入PDF文件的内容
File file = new File("//Users//"+inputFile);
// 上传PDF到云存储
pdfApi.uploadFile("input.pdf", file, null);
// 提取图像的PDF页面
int pageNumber =1;
// 提取图像的宽度
int width = 600;
// 提取图像的高度
int height = 800;
// 保存提取图像的文件夹
String folderName = "NewFolder";
// 提取 PDF 图像并保存在云存储中
pdfApi.putImagesExtractAsJpeg(inputFile, pageNumber, width, height, null, null, folderName);
// 打印成功信息
System.out.println("PDF images Successsuly extracted !");
}catch(Exception ex)
{
System.out.println(ex);
}
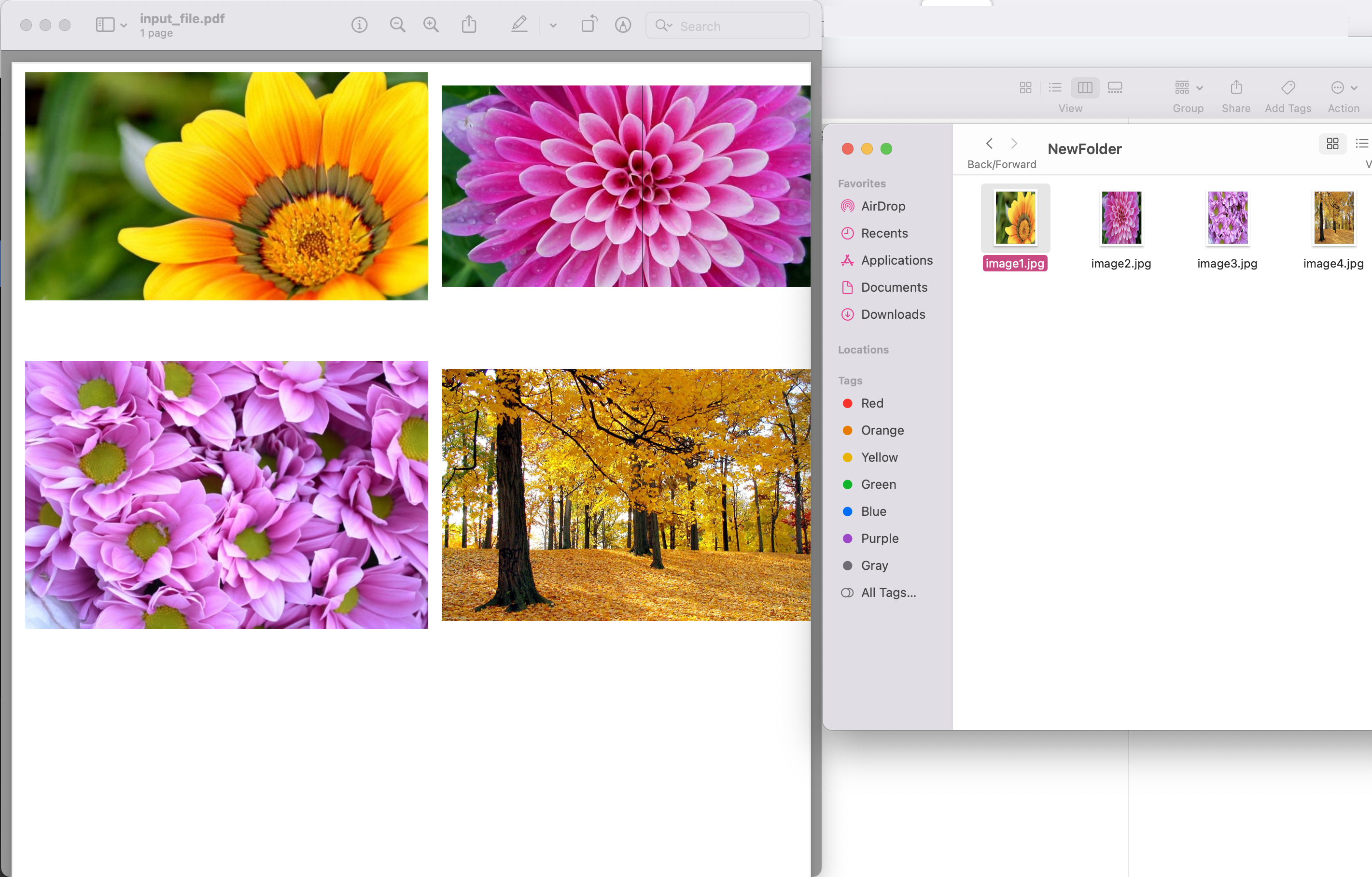
Image1:- 提取 PDF 图像预览
上例中使用的示例 PDF 文件可以从 input.pdf 下载。
使用 cURL 命令保存 PDF 图像
现在我们将使用 cURL 命令调用用于提取 PDF 图像的 API。现在作为此方法的先决条件,首先我们需要在执行以下命令时生成 JWT 访问令牌(基于客户端凭据)。
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
一旦我们有了 JWT 令牌,请执行以下命令将 PDF 图像保存在云存储上的单独文件夹中。
curl -X PUT "https://api.aspose.cloud/v3.0/pdf/input_file.pdf/pages/1/images/extract/jpeg?width=0&height=0&destFolder=NewFolder" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
结论
阅读本文后,您了解了一种使用 Java 代码片段以及通过 cURL 命令提取 PDF 图像的简单而可靠的方法。正如我们所注意到的,我们可以从 PDF 文件的指定页面中提取图像,并提供对提取过程的更多控制。产品 文档 丰富了一系列令人惊叹的主题,进一步解释了此 API 的功能。
此外,由于我们所有的 Cloud SDK 都是在 MIT 许可下发布的,因此您可以考虑从 GitHub 下载完整的源代码并根据您的要求进行修改。如有任何问题,您可以考虑通过免费的 产品支持论坛 联系我们寻求快速解决方案。
相关文章
请访问以下链接以了解更多信息: