
Як витягти PDF-зображення за допомогою Cloud Java
Ми регулярно використовуємо файли PDF, оскільки вони чудово підтримують текстовий і графічний вміст. Після розміщення цих елементів у документі макет файлу зберігається незалежно від того, яку платформу ви використовуєте для їх перегляду. Але нам може знадобитися видобуток зображень PDF. Це можна зробити за допомогою програми перегляду PDF, але вам потрібно вручну пройти кожною сторінкою та окремо зберегти кожне зображення. Крім того, за іншого сценарію, якщо у вас є PDF-файл на основі зображень і вам потрібно виконати оптичне розпізнавання символів PDF, то спочатку вам потрібно витягти всі зображення, а потім виконати операцію OCR. Це викликає серйозні труднощі, коли у вас є великий набір документів, але програмне рішення може бути надійним і швидким рішенням. Тож у цій статті ми розглянемо варіанти видобування зображень із PDF за допомогою Java Cloud SDK
- API перетворення PDF у JPG
- Розпакуйте PDF-зображення в Java
- Зберігайте зображення PDF за допомогою команд cURL
API перетворення PDF у JPG
Щоб конвертувати PDF у JPG або JPG у PDF у додатку Java, дивовижним вибором стане Aspose.PDF Cloud SDK для Java. Водночас він також дає змогу видобувати зображення з PDF, витягувати текст із PDF, видобувати вкладення з PDF, а також надає безліч варіантів для роботи з PDF. Отже, щоб реалізувати функцію збереження PDF-зображень у додатку Java, спочатку нам потрібно додати посилання на Cloud SDK у наш проект. Тож додайте наступні деталі в pom.xml проекту типу збірки maven.
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>https://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
Після того, як посилання на SDK буде додано, і у вас немає жодного облікового запису в Aspose Cloud, створіть безкоштовний обліковий запис, використовуючи дійсну адресу електронної пошти. Потім увійдіть, використовуючи щойно створений обліковий запис, і знайдіть/створіть ідентифікатор клієнта та секрет клієнта на Cloud Dashboard. Ці дані потрібні для автентифікації в наступних розділах.
Розпакуйте PDF-зображення в Java
Будь ласка, виконайте наведені нижче кроки, щоб отримати зображення з PDF-файлу, і після завершення операції зображення будуть збережені в окремій папці в хмарному сховищі.
- Спочатку нам потрібно створити об’єкт PdfApi, надаючи ClientID і Client secret як аргументи
- По-друге, завантажте вхідний файл PDF за допомогою екземпляра File
- Завантажте вхідний PDF-файл у хмарне сховище за допомогою методу uploadFile(…).
- Ми також збираємося використовувати необов’язковий параметр для встановлення деталей висоти та ширини для вилучених зображень
- Нарешті, викличте метод putImagesExtractAsJpeg(…), який приймає назву PDF-файлу, номер сторінки для вилучення зображень, розміри витягнутих зображень і назву папки в хмарному сховищі для збереження вилучених зображень.
try
{
// Отримайте ClientID і ClientSecret з https://dashboard.aspose.cloud/
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// створити екземпляр PdfApi
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// назва вхідного документа PDF
String inputFile = "marketing.pdf";
// прочитати вміст вхідного файлу PDF
File file = new File("//Users//"+inputFile);
// завантажити PDF в хмарне сховище
pdfApi.uploadFile("input.pdf", file, null);
// Сторінка PDF для вилучення зображень
int pageNumber =1;
// ширина для вилучених зображень
int width = 600;
// висота вилучених зображень
int height = 800;
// папку для збереження вилучених зображень
String folderName = "NewFolder";
// Видобувайте зображення PDF і заощаджуйте на Cloud Storage
pdfApi.putImagesExtractAsJpeg(inputFile, pageNumber, width, height, null, null, folderName);
// повідомлення про успішний друк
System.out.println("PDF images Successsuly extracted !");
}catch(Exception ex)
{
System.out.println(ex);
}
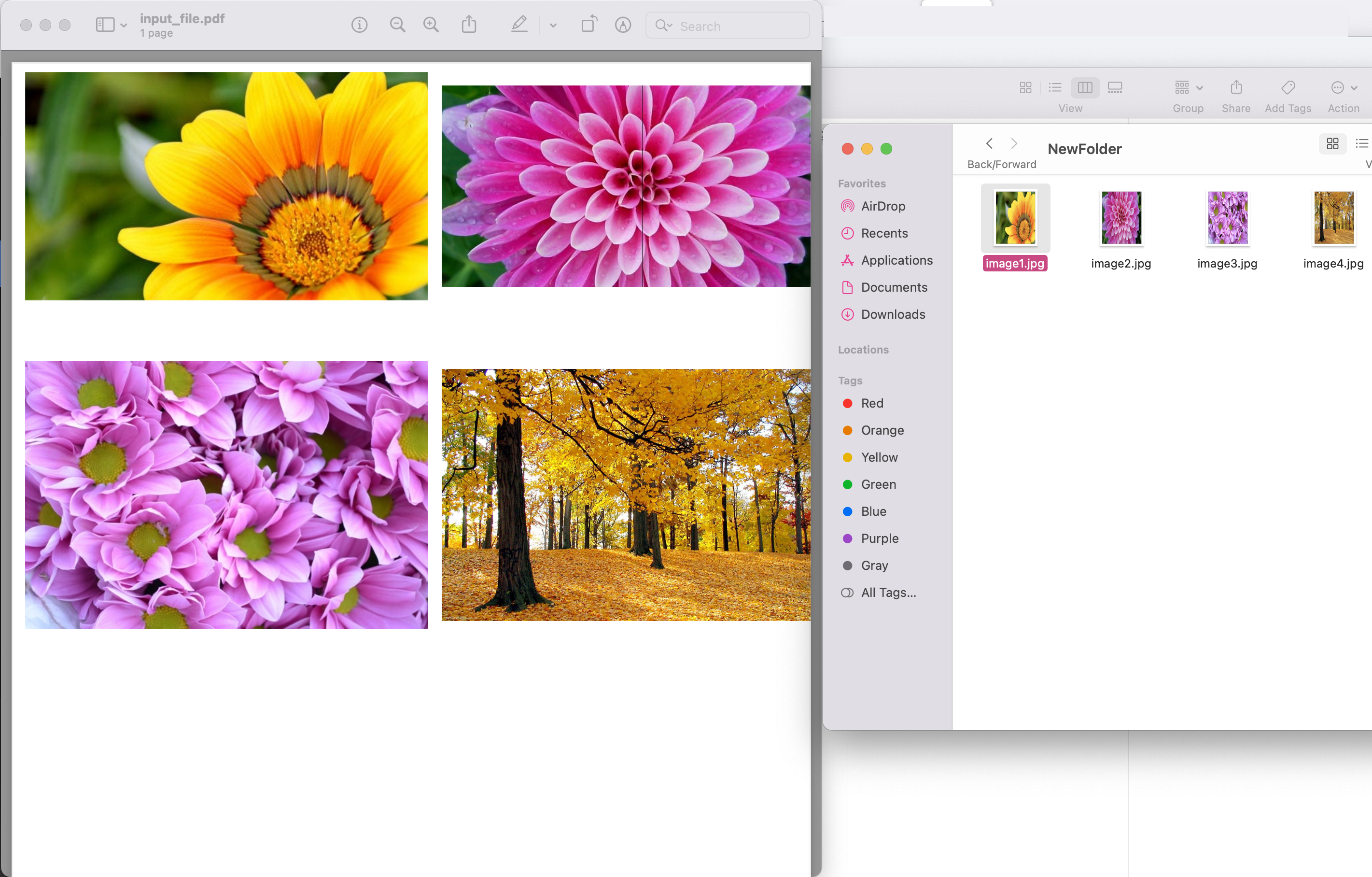
Image1: - Попередній перегляд зображень PDF
Зразок PDF-файлу, використаного у прикладі вище, можна завантажити з input.pdf.
Зберігайте зображення PDF за допомогою команд cURL
Тепер ми викличемо API для вилучення зображень PDF за допомогою команд cURL. Тепер, як передумова для цього підходу, спочатку нам потрібно згенерувати маркер доступу JWT (на основі облікових даних клієнта) під час виконання наступної команди.
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
Отримавши маркер JWT, виконайте наведену нижче команду, щоб зберегти зображення PDF в окремій папці в хмарному сховищі.
curl -X PUT "https://api.aspose.cloud/v3.0/pdf/input_file.pdf/pages/1/images/extract/jpeg?width=0&height=0&destFolder=NewFolder" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
Висновок
Прочитавши цю статтю, ви навчилися простого, але надійного підходу до видобування PDF-зображень за допомогою фрагмента коду Java, а також за допомогою команд cURL. Як ми помітили, ми отримуємо можливість видобувати зображення з указаної сторінки PDF-файлу та забезпечуємо більше контролю над процесом вилучення. Продукт Документація збагачений набором чудових тем, які додатково пояснюють можливості цього API.
Крім того, оскільки всі наші Cloud SDK публікуються за ліцензією MIT, ви можете завантажити повний вихідний код із GitHub і змінити його відповідно до своїх вимог. У разі будь-яких проблем ви можете звернутися до нас за швидким вирішенням через безкоштовний форум підтримки продуктів.
Схожі статті
Перейдіть за наведеними нижче посиланнями, щоб дізнатися більше про: