
如何使用 Cloud Java 提取 PDF 圖像
我們經常使用 PDF 文件,因為它們為文本和圖像內容提供了驚人的支持。一旦將這些元素放入文檔中,無論您使用哪個平台查看它們,文件的佈局都會被保留。但是,我們可能需要提取 PDF 圖像。這可以使用 PDF 查看器應用程序來完成,但您需要手動遍歷每個頁面並單獨保存每個圖像。此外,在另一種情況下,如果您有基於圖像的 PDF,並且需要執行 PDF OCR,那麼您需要先提取所有圖像,然後執行 OCR 操作。當您擁有大量文檔時,這會變得非常困難,但編程解決方案可能是可靠且快速的解決方案。因此,在本文中,我們將探索使用 Java Cloud SDK 從 PDF 中提取圖像的選項
PDF 到 JPG 轉換 API
為了在 Java 應用程序中將 PDF 轉換為 JPG 或將 JPG 轉換為 PDF,Aspose.PDF Cloud SDK for Java 是一個了不起的選擇。同時,它還使您能夠從 PDF 中提取圖像、從 PDF 中提取文本、從 PDF 中提取附件以及提供大量的 PDF 操作選項。因此,為了在 Java 應用程序中實現保存 PDF 圖片的功能,首先我們需要在我們的項目中添加 Cloud SDK 引用。因此,請在 maven 構建類型項目的 pom.xml 中添加以下詳細信息。
<repositories>
<repository>
<id>aspose-cloud</id>
<name>artifact.aspose-cloud-releases</name>
<url>https://artifact.aspose.cloud/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf-cloud</artifactId>
<version>21.11.0</version>
</dependency>
</dependencies>
一旦添加了 SDK 參考並且您沒有任何現有的 Aspose Cloud 帳戶,請使用有效的電子郵件地址創建一個免費帳戶。然後使用新創建的帳戶登錄並在 Cloud Dashboard 查找/創建客戶端 ID 和客戶端密碼。在以下部分中,出於身份驗證目的需要這些詳細信息。
在 Java 中提取 PDF 圖像
請按照以下步驟從 PDF 中提取圖像,操作完成後,圖像將存儲在雲存儲上的單獨文件夾中。
- 首先,我們需要創建一個 PdfApi 對象,同時提供 ClientID 和 Client secret 作為參數
- 其次,使用 File 實例加載輸入 PDF 文件
- 使用 uploadFile(…) 方法將輸入的 PDF 上傳到雲存儲
- 我們還將使用一個可選參數來設置提取圖像的高度和寬度細節
- 最後調用 putImagesExtractAsJpeg(…) 方法,輸入 PDF 名稱、提取圖像的頁碼、提取圖像的尺寸和雲存儲上保存提取圖像的文件夾名稱
try
{
// 從 https://dashboard.aspose.cloud/ 獲取 ClientID 和 ClientSecret
String clientId = "bb959721-5780-4be6-be35-ff5c3a6aa4a2";
String clientSecret = "4d84d5f6584160cbd91dba1fe145db14";
// 創建 PdfApi 的實例
PdfApi pdfApi = new PdfApi(clientSecret,clientId);
// 輸入 PDF 文檔的名稱
String inputFile = "marketing.pdf";
// 讀取輸入PDF文件的內容
File file = new File("//Users//"+inputFile);
// 上傳PDF到雲存儲
pdfApi.uploadFile("input.pdf", file, null);
// 提取圖像的PDF頁面
int pageNumber =1;
// 提取圖像的寬度
int width = 600;
// 提取圖像的高度
int height = 800;
// 保存提取圖像的文件夾
String folderName = "NewFolder";
// 提取 PDF 圖像並保存在雲存儲中
pdfApi.putImagesExtractAsJpeg(inputFile, pageNumber, width, height, null, null, folderName);
// 打印成功信息
System.out.println("PDF images Successsuly extracted !");
}catch(Exception ex)
{
System.out.println(ex);
}
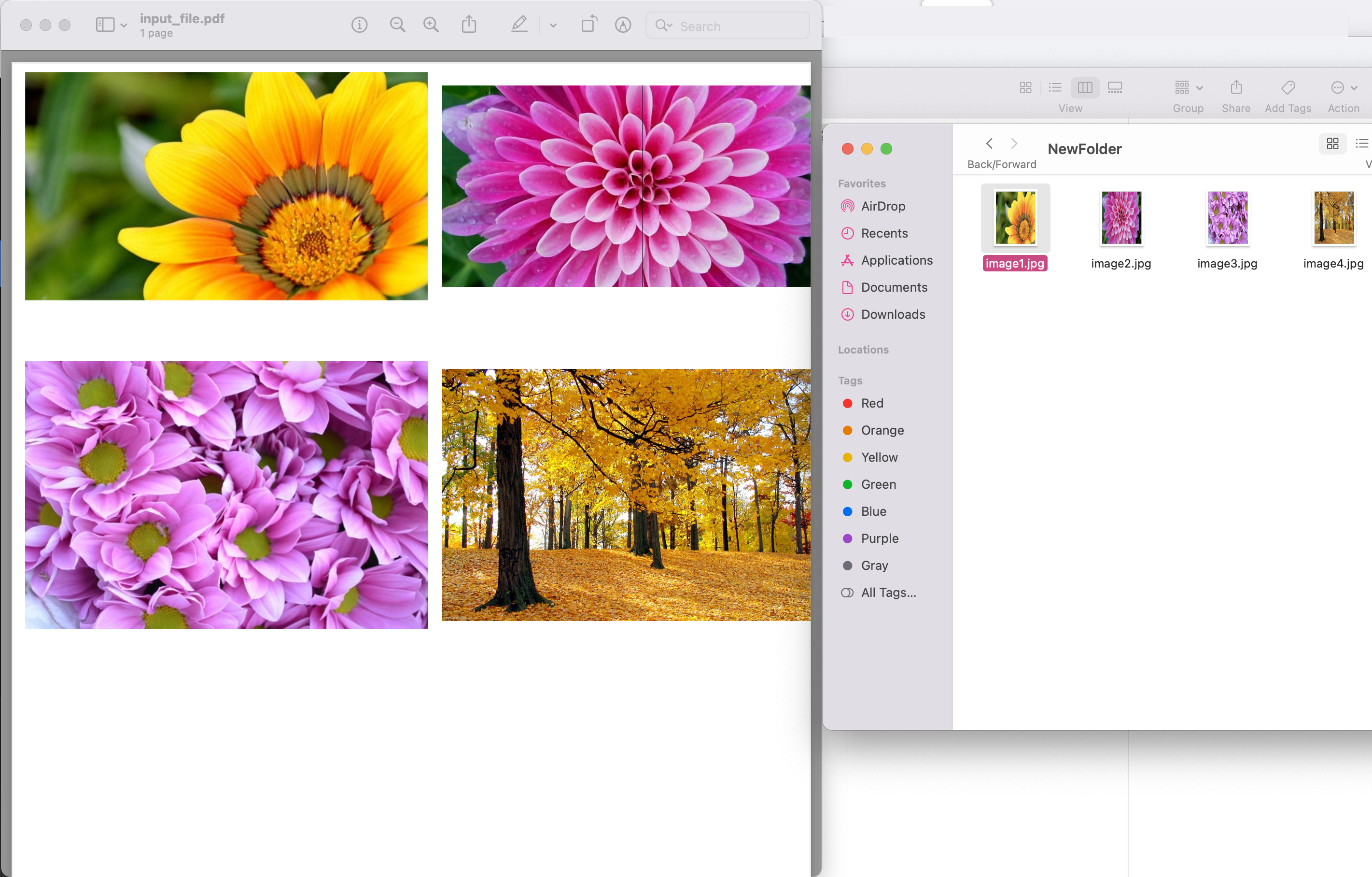
Image1:- 提取 PDF 圖像預覽
上例中使用的示例 PDF 文件可以從 input.pdf 下載。
使用 cURL 命令保存 PDF 圖像
現在我們將使用 cURL 命令調用用於提取 PDF 圖像的 API。現在作為此方法的先決條件,首先我們需要在執行以下命令時生成 JWT 訪問令牌(基於客戶端憑據)。
curl -v "https://api.aspose.cloud/connect/token" \
-X POST \
-d "grant_type=client_credentials&client_id=bb959721-5780-4be6-be35-ff5c3a6aa4a2&client_secret=4d84d5f6584160cbd91dba1fe145db14" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Accept: application/json"
一旦我們有了 JWT 令牌,請執行以下命令將 PDF 圖像保存在雲存儲上的單獨文件夾中。
curl -X PUT "https://api.aspose.cloud/v3.0/pdf/input_file.pdf/pages/1/images/extract/jpeg?width=0&height=0&destFolder=NewFolder" \
-H "accept: application/json" \
-H "authorization: Bearer <JWT Token>"
結論
閱讀本文後,您了解了一種使用 Java 代碼片段以及通過 cURL 命令提取 PDF 圖像的簡單而可靠的方法。正如我們所注意到的,我們可以從 PDF 文件的指定頁面中提取圖像,並提供對提取過程的更多控制。產品 文檔 豐富了一系列令人驚嘆的主題,進一步解釋了此 API 的功能。
此外,由於我們所有的 Cloud SDK 都是在 MIT 許可下發布的,因此您可以考慮從 GitHub 下載完整的源代碼並根據您的要求進行修改。如有任何問題,您可以考慮通過免費的 產品支持論壇 聯繫我們尋求快速解決方案。
相關文章
請訪問以下鏈接以了解更多信息: